本节书摘来自华章出版社《异构信息网络挖掘: 原理和方法法》一 书中的第2章,第2.2节,作者( 美)孙艺洲(Yizhou Sun),(美)韩家炜(Jiawei Han),更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.2 RankClus算法
首先,我们来看看使用网络中其他类型对象(属性对象)和链接来对(目标)类型对象进行聚类的任务。例如,给定一个包含刊物和作者的双类型文献网络,其中刊物与作者之间,作者与作者之间都直接有链接。让我们感兴趣的是通过网络中的作者和链接,如何将刊物聚集为代表不同研究机构的若干聚类。这一节将介绍一个基于双类型文献网络的排名聚类算法RankClus。
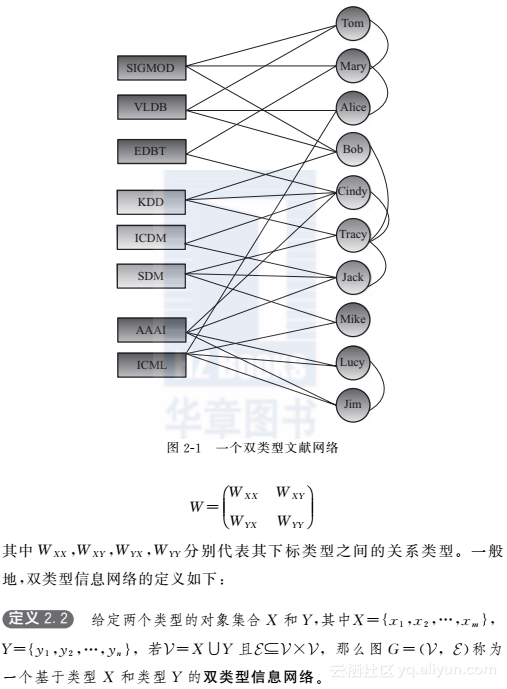
图2.1展示了一个双类型文献网络,它包含了两种类型的对象:刊物(X)和作者(Y);以及两种类型的链接:
作者刊物发表链接(链接的权值为作者在刊物上发表的论文数量)以及作者作者合作关系链接(链接的权值为两位作者的合作次数)。双类型网络可以表示为一个块邻接矩阵:


2.2.1排名函数
在我们的基于排名的聚类算法中,排名函数至关重要,它不仅提供了用于区别对象在聚类中重要性的排名分数,也作为新特征的提取工具用以提高聚类的质量。当前的排名函数主要是基于同构网络定义的,如PageRank[10]和HITS[34]。这一节将介绍两个基于双类型文献网络的排名函数:简单排名和权威排名。本节末尾还将讨论在更为复杂的异构网络上的排名函数。
1.简单排名
最简单的刊物和作者的排名是基于发表数量,这与刊物录用或作者发表的论文数量成一定比例。
一般地,给定含有类型X和类型Y,邻接矩阵W的双类型信息网络,简单排名按如下方式计算类型X和类型Y的排名分数:
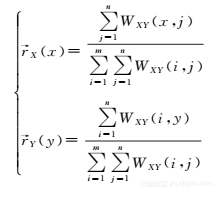

2.权威排名
这里,我们给出一个更有用的排名函数——权威排名,这个函数给予权威性高的对象高的排名分数。乍一看,仅使用发表信息进行权威性排名似乎不可能,因为引用信息可能无法获知或是不完整的(例如,在DBLP数据中,没有从Citeseer,ACM数字图书馆或Google学术引入任何引用信息)。然而,两条简单的经验规则给了我们第一个线索。
- 规则1:排名靠前的作者在排名靠前的刊物发表了许多的论文。
- 规则2:排名靠前的刊物吸引许多排名靠前的作者的论文。
注意,这些经验规则与领域有关,往往由熟悉领域和数据集的领域专家给出。根据上述启发,我们定义了作者和刊物排名分数相互计算的迭代公式。
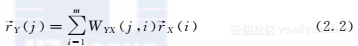
当作者j发表了更多论文,将会有更多非零的和高权重的WYX(j,i),并且,当该作者在一个更高排名的刊物i发表论文,即一个大的r→X(i),那么作者j的分数也会提高。在每一个步骤的最后,r→Y(j)依照

根据规则2,每个刊物的得分由刊物发表论文的数量和质量决定,其中质量由作者的排名分数来度量。
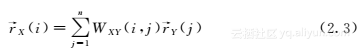
当有更多的论文在刊物i发表,将会有更多非零的和高权重的WXY(j,i),并且,如果论文由一个排名很高的作者j完成,即一个高的r→Y(j),那么刊物i的分数也会提高。分数向量依照
 被标准化。
被标准化。
注意,标准化不会改变对象的排名位置,但它给每个对象一个相对的重要性评分。如RankClus[66]所示,这两个公式分别收敛于WXYWYX和WYXWXY的主特征向量。
若考虑合作者信息,可以根据规则3进一步优化评分函数。
- 规则3:一个作者若有许多高排名的合作者,那么该作者的排名由此被提高。
添加这个新规则,通过修改式(2.2)我们可以按下式来计算作者的排名分数。
其中参数α∈[0,1]决定每一个因素的权重,α的赋值可以基于先验知识或学习训练数据集得到。
同样地,我们可以证明r→Y应该是αWYXWXY+(1-α)WYY的主特征向量,r→X应该是αWXY(1-(1-α)WYY)-1WYX的主特征向量。由于迭代过程是计算主特征向量的强有力方法,所以排名分数最终将收敛。
权威排名的时间复杂度是O(t||),其中t是迭代数量,||是图中链接的数量。注意,在稀疏网络中||=O(d||)||2,其中||是在网络中对象的总数,d是每个对象的平均链接数。
不同于简单排名依靠对象的直接邻居,权威排名依靠在网络中传播分数,基于整个网络给出每个对象的重要性度量。
3 其他可选的排名函数
虽然在这里我们只提到两个排名函数,然而一般性的排名函数不仅局限于此。在实践中,一个排名函数不仅与信息网络的链接属性有关,而且依赖于领域知识。例如,在许多科学领域,当评价作者时,期刊的权重比会议要高。此外,尽管这一节所述的排名函数都是基于双类型网络定义的,但可以在包含更多类型对象的异构网络中进行类似的定义。例如,对于一般的异构网络,PopRank[51]是一个可行的框架,它既考虑了来自同样类型对象的影响,也考虑了来自其他类型对象的影响,不同的类型有着不同的影响因子。对信息网络中的对象进行排名,垃圾实体通常获得偏高的排名。例如,权威排名可能因为一些有着大量录用篇幅而接受任何投稿的虚假会议变得没有用处。能够使用专家知识的技术,如TrustRank[23],可以半自动化地从垃圾对象中找出名誉好的对象。个性化的PageRank[86]能够以专家排名为查询,并根据相应知识产生排名分布,这是集成专家知识的另一种选择。
2.2.2从条件排名分布到新的聚类度量
给定一个双类型文献网络,假设我们有一个目标类型X(刊物类型)的初始划分,并且已经计算了每个聚集网络中刊物和作者的条件排名分数,那么下一个问题就变成了如何使用条件排名分数来进一步提高聚类结果。直观地,每一个刊物聚类都可能形成一个研究领域,一个聚类(或研究领域)中的作者的排名分数应该与其他聚类中的作者排名有所区别。这意味着可以用这些排名分数获取对象的新特征,以得到更好的聚类。进一步,我们将这些排名分数看作来自一个离散的排名分布,因为它们都是非负值并且加起来等于1,排名分布反映了每个聚类中的根据对象的权威性能确定一个对象知道一位作者或刊物的主观可能性。

从例2.3可以看出每个聚类中属性类型的条件排名分布各不相同,且可以用来描述其所在聚类的特征。换言之,对于每个聚类
Xk,X和Y的条件排名分数r→X|Xk和r→Y|Xk可以被视为
X和Y的条件排名分布,事实上,这也是聚类Xk的特征。
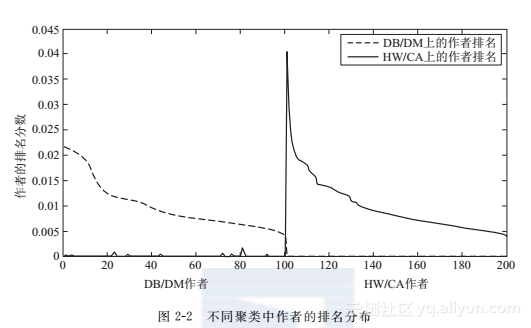
1.目标对象的聚类成员关系
假设我们现在已有对类型X的聚类结果,记为X1,X2,…,XK,其中K是聚类的数量。另外,根据某个给定的排名函数,我们已经获得每个聚类XK中在Y上的条件排名分布,记为r→Y|Xk(k=1,2,…,K),以及在X上的条件排名分布,记为r→X|Xk(k=1,2,…,K)。简便起见,在下文中我们用pk(Y)代表r→
Y|Xk,
pk(X)代表r→X|Xk。我们用πi,k来表示xi之于聚类k的聚类成员关系,这实际是xi属于聚类k的后验概率并且满足∑Kk=1πi,k=1。
根据贝叶斯规则,p(k|xi)∝p(xi|k)p(k)。由于我们已经知道了xi在聚类k中的条件排名p(xi|k),因而目标是估算p(k),即k的聚类大小。在DBLP场景中,刊物的聚类,例如DB刊物,可以得出在相应领域中刊物和作者的子网络。p(k)可被看作是由第k刊物聚类推算出的属于这个研究领域的论文的比例,其中每篇论文表示为刊物与作者之间的一条链接。根据p(k|xi)∝p(xi|k)p(k),我们可以看到,一般来说,一个对象在某个聚类的条件排名(p(xi|k))越高,该对象属于这个聚类的可能性(p(k|xi))就越大。由于X对象的条件排名分数受Y对象的条件排名分数传播影响,我们也可以看到,高排名的属性对象对决定目标对象的聚类成员关系有更大的影响。
2.用EM算法估计参数
为了获取每个目标对象的聚类成员关系,我们需要正确地估计每个聚类p(k)的大小比例,它可以被看作是由目标对象发出且属于聚类k的链接数的比例。在我们的双类型文献信息网络例子中,这正是属于特定聚类的论文数比例。
接下来,我们构建一个混合模型来生成由目标对象发出的链接。也就是,对象xi和对象yj之间每条链接以概率
p(xi,yj)=∑kpk(xi,yj)p(k)生成,其中pk(xi,yj)代表在聚类
k中生成这样一条链接的概率。我们也做一个独立性假设,属性对象yj发出一条链接与目标对象xi接收这条链接相独立,即pk(xi,yj)=pk(xi)pk(yj)。这个假设表明一旦作者完成一篇论文,他更愿意将论文投稿到一个排名高的刊物,从而提高他的排名;而对于刊物,则更希望接收来自高排名作者的论文,以提高刊物的排名。这个想法类似于同构网络中链接信息的优先附加[4](preferential attachment),但是我们考虑更复杂的排名分布,而不是对象的度。

2.2.3聚类中心和距离测量
在通过评价混合模型得到每个目标对象xi的聚类成员关系的估计后,xi能够被表述为一个K维向量
s→xi=(πi,1,πi,2,…,πi,K)。相应地,可以计算每个聚类的中心,对聚类包含的所有xi,聚类中心是s→xi的平均值。接下来,一个对象和一个聚类之间的距离D(x,Xk)被定义为1减去余弦相似度。每个目标对象的聚类标签也随之调整。
2.2.4RankClus算法总结
总结一下,RankClus的输入是一个双类型信息网络G=〈{X∪Y},W〉,X和Y的排名函数,以及聚类数目K。输出是X的K个聚类,每个聚类包含对所有x和y的条件排名分数。图24描绘了算法RankClus并总结如下。
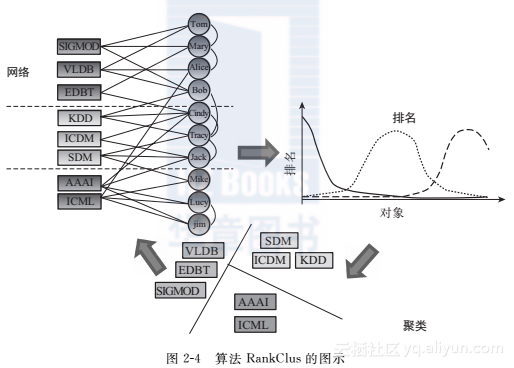
- 步骤0:初始化。
将每个目标对象随机地赋予一个1到K的聚类标签,产生目标对象的初始聚类。
- 步骤1:对每个聚类进行排名。
基于当前的聚类,相应地产生K个聚类诱发(clusterinduced)的网络,并对类型Y和X计算条件排名分布。在这一步,我们还需判断是否有由于算法的不恰当初始化所导致的空聚类。若某个聚类为空,则重新开始算法以产生K个聚类。
- 步骤2:估计目标对象的聚类成员关系。
这一步,我们需要估计混合模型的参数Θ,并且获得每个目标对象和每个目标聚类的中心的新表达:
s→x和s→Xk。在实践中,计算Θ的迭代次数t只需被设定为一个小的数目。
- 步骤3:聚类调整。
在这一步中,我们计算每个对象到各个聚类中心的距离并将对象分配到距离它最近的聚类。
重复步骤1,2,3,直至聚类的变化不超过一个非常小的比率ε或者迭代次数超过预定义值iterNum。在实践中,我们设置
ε=0,iterNum=20。在我们的实验中,对合成数据集,算法大多数情况下在5轮内收敛,对DBLP数据集,算法在10轮左右收敛。
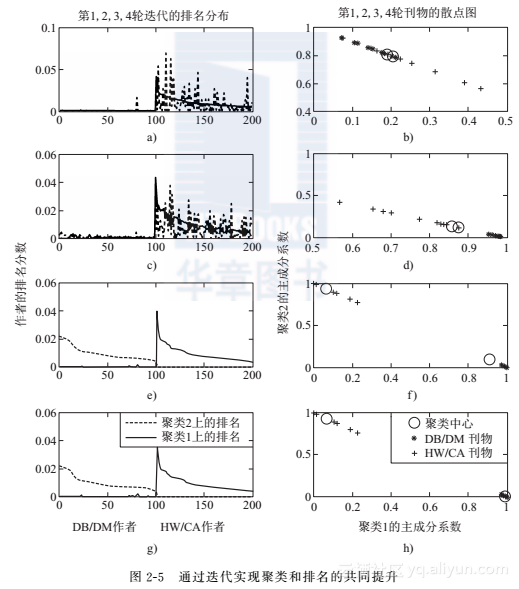
例2.5 (聚类和排名的共同提升)
现在我们将算法应用于“两个研究领域”的例子。图2.5a~h示例了在每一轮迭代中每个聚类的条件排名分布和每个刊物的聚类成员关系。为了更好地解释我们算法是如何运执行的,设定一个极坏的初始聚类作为初始状态。在聚类1中,有14个刊物,其中一半来自DB/DM领域,另一半来自HW/CA领域。聚类2包含了剩下的6个刊物,它们是ICDT、CIKM、PKDD、ASPLOS、ISLPED和CODES。我们能看出,从规模上划分非常不平衡,从领域上来说也是很混乱。在第一轮迭代中,两个聚类的条件排名分布彼此非常相似(图2.5a),并且刊物是混杂的且偏向于聚类2的(图25b)。然而,我们仍然能够根据聚类中心调整它们的聚类标签。大多数HW/CA的刊物被划分为聚类2,大多数DB/DM的刊物被划分为聚类1。在第二轮迭代中,上一轮的聚类(图2.5b)得到了改善,尽管这一轮的聚类结果仍然偏向于一个聚类(聚类1),但这一轮的聚类结果(图2.5d)戏剧性地增强了,因此条件排序也稍微得到了提升(如图2.5c所示)。在第三轮迭代中,排名结果获得显著提升。在此之后,聚类和排名被进一步、小幅度的调整。
在每一轮迭代中,RankClus的时间复杂度包含三部分:排名部分,混合模型估计部分和聚类调整部分。对于排名,如果使用简单排名,时间复杂度是O(||)。若用权威排名,时间复杂度为O(t1||),其中||为链接的数量,t1是迭代次数。对于混合模型估计,在每一轮,我们需要计算各个聚类中每条链接的条件概率,其时间复杂度为O(K||)。对于聚类调整,我们需要计算每个对象(m)和每个聚类(K)之间的距离,每个对象的维度为K,这部分的时间复杂度为
O(mK2)。总的来说,时间复杂度为O(t(t1||+t2(K||)+mK2)),其中t是整个算法的迭代次数,t2是混合模型的迭代次数。如果网络是一个稀疏网络,时间与对象数量几乎呈线性关系。
2.2.5实验结果
我们在合成数据集与真实数据集上,通过比较RankClus算法与其他基于链接的算法来展示RankClus的有效性和执行效率。
基于DBLP数据集的案例研究我们使用DBLP数据集中1998年至2007年2676个刊物和发表论文最多的20000个作者生成一个双类型信息网络。作者刊物关系以及合著关系都被使用到。我们设置聚类的数量K=15,使用带权威排名函数的RankClus算法,令α=095。然后,选择5个聚类,并依据条件排名分数从每个聚类中选出分数最高的10个刊物。表24列出了结果,其中每个聚类的研究领域标签是人工添加上的。
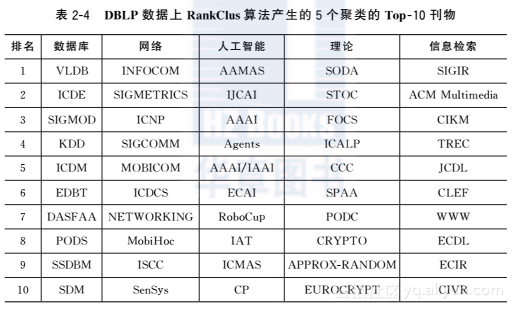
请注意表2-4所示的刊物的聚类和排名没有使用关键字和引用信息,而这两类信息被大多数文献数据分析系统广泛使用。众所周知,引用信息在评判一个刊物或作者在其领域的影响力方面十分重要。然而,RankClus算法仅利用DBLP数据中的论文发表条目,就可以获得与使用引用信息对刊物和作者进行聚类和排名的算法分庭抗礼的结果。这意味着即使不涉及关键字和引用信息,论文发表条目集合仍然能够反映刊物和作者在某个科学领域的状态。
基于合成数据的准确性与效率实验为了比较不同聚类算法的准确性,我们按照与DBLP数据相似的真实信息网络的性质,生成一个合成的双类型信息网络。在我们的实验中,首先修正了网络规模和链接分布,修改配置以调整聚类的密度和聚类间的离散度,从而获得5个不同的网络(数据集1~数据集5)。将聚类个数设置为K=3,每个聚类的目标对象数目分别为
Nx=[10,20,15],每个聚类的属性对象数目分别为Ny=[500,800,700]。5个数据集采用相同的设置。然后,通过改变每个聚类的链接数量(P)和聚类间链接比例的转移矩阵(T),获得以下5个数据集。

我们使用标准化互信息(NMI)[60]来比较不同算法的聚类准确性。对于N个对象、K个聚类和两个聚类结果,令n(i,j)(i,j=1,2,…,K)为在第一次聚类结果(算法产生)中聚类标签为i,在第二次聚类结果中聚类标签为j(真实情况)的对象数目。那么,我们可以定义联合分布p(i,j)=n(i,j)N,行分布
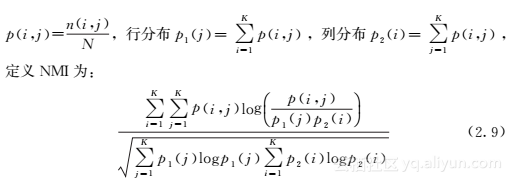
我们实现了带简单排名和权威排名两种排名函数的RankClus算法,并将其与目前最好的聚类算法——kway Ncut算法[58]进行比较。对于kway Ncut算法,分别使用了两种基于链接的相似度函数:Jaccard系数和SimRank[28]。
图2-6给出了结果的准确性。从图中可以看到,RankClus的两个版本在前4个数据集中表现更好。由于权威排名利用整个网络的信息得到更好的排名分布,所以带权威排名的RankClus结果更好些。通过实验,我们观察到的RankClus的两个版本和基于Jaccard系数的Ncut算法高度依赖于数据质量(从聚类离散度和链接密度两方面来讲),而基于SimRank的Ncut算法则有更稳定的表现,特别是当网络稀疏时(数据集5)。
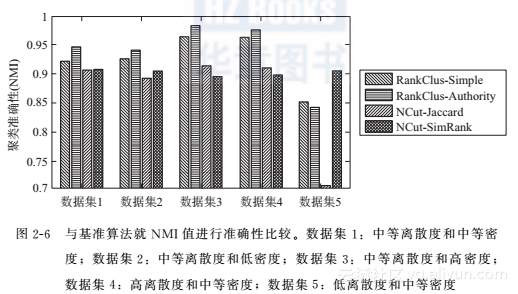
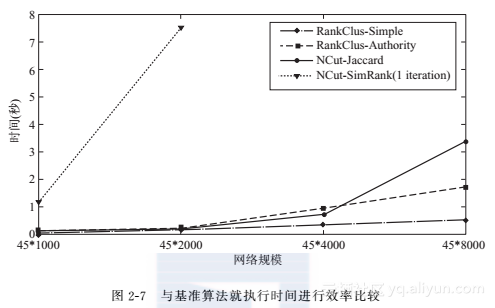
图2-7展示了在四个不同规模的网络上各个算法的平均执行时间。可以看出,与耗时的SimRank算法相比,RankClus执行效率高且伸缩性好。