本 节 书 摘 来 自 华 章 出 版 社 《CUDA高性能并行计算》 一 书 中 的 第2章,第2.1节, 作 者 CUDA for Engineers: An Introduction to High-Performance Parallel Computing[美] 杜安·斯托尔蒂(Duane Storti)梅特·尤尔托卢(Mete Yurtoglu) 著,苏统华 项文成 李松泽 姚宇鹏 孙博文 译 , 更 多 章 节 内 容 可 以 访 问 云 栖 社 区 “华 章 计 算 机” 公 众 号 查 看。
第2章
CUDA基础知识
在第1章中我们的讨论以计算从一个参考点到一组输入位置距离的函数distance-Array()结束。这个计算完全是串行的,距离数值是根据一个for循环中的计数i和输入数组的范围顺序计算的。但是,任何一个距离的计算相对于其他计算都是独立的。在串行实现中,我们不能发挥计算独立的优势反而会在计算中等待,直到一个计算完成再进行下一个计算。如果读者所使用的系统同一时间只能进行一个计算,那么串行的实现无可苛责。然而,在一个通用的GPU计算中,我们拥有成百上千的可以同时进行运算的硬件单元。为了让我们拥有的众多处理器发挥优势,我们将串行模式(同一时间内只进行一个计算任务,其他的依次等待)转换为并行模式(大量的计算同时执行)。本章中描述了CUDA模式中的并行、CUDA的基本编程语言扩展以及应用程序编程接口(API)[1, 2]。
2.1 CUDA并行模式
从串行到CUDA并行同时涉及硬件和软件两方面。硬件的转换涉及包含了多个运算单元以及运算规划和数据传输机制的芯片。软件的转换涉及API以及对编程语言的扩展。

GPU能够进行并行化的关键属性是其并不是只有一个或几个计算单元(像现代多核CPU一样)而是其具有成百上千计算单元。如果读者能够将计算分成大量的独立子任务,这些大量的计算单元为并行执行这些任务提供了可行性,换言之,同时执行这些任务而不是串行进行。值得注意的是,这样的并行涉及许多规划方面的问题:如何让一个特定的计算单元知道其需要执行哪个子任务?如何让大量的计算单元进行指令和数据的访问而不会造成巨大的通信阻塞?
CUDA引用了单指令多线程(SIMT)的并行模式。CUDA GPU包含了大量的基础计算单元,这些单元被称为核(core)每一个核都包含了一个逻辑计算单元(ALU)和一个浮点计算单元(FPU)。多个核集成在一起被称为多流处理器(SM)。
我们将一个计算任务分解为多个子任务,并将其称为线程,多个线程被组织为线程块。线程块被分解为大小与一个SM中核数量相同的线程束(warp)。每个线程束由一个特定的多流处理器执行。这些多流处理器的控制单元指挥其所有核同时在一个线程束的每个线程中执行同一个指令,因此这个术语称为单指令多线程(single instruction multiple thread)。
执行同一指令并不是仅仅重复一种运算,因为每个线程使用由CUDA提供的单独的索引值进行了不同的运算[3]。这种SIMT的方法是可拓展的,因为可以通过使用更多的多流处理器分担计算负载来增加计算的吞吐量。图2.1显示了一个GPU和一个CPU之间的架构对比。CPU拥有较少的核,占据芯片的小部分,而更多的区域被用来加速那些少量核的控制器和缓存占据。通常而言,访问数据所需的时间会随着计算核和存贮数据的内存间位置的距离而增加。核等待数据的时间被称为延迟(latency),并且一个CPU通过设计大量的可以快速访问的空间存储数据来缩小延迟。
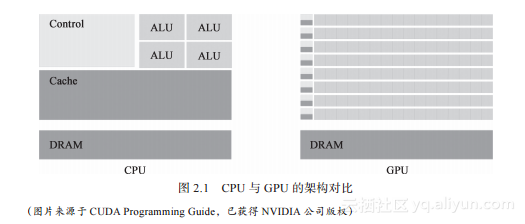
GPU的空间分配则十分不同。芯片上的大多数地方被分配给了大量组织成多流处理器的运算单元和共享的控制单元。与其缩小延迟(需要为每个核配备大量缓存)GPU更倾向于隐藏延迟。当一个线程束所需要的数据不可获得时,多流处理器会转向执行另一个可获得数据的线程束。所关注的重点是整体的运算吞吐量而不是单个核心的执行速度。
现在我们已经准备好讨论CUDA的SIMT软件方面的实现。关键的软件结构是一种叫作核函数(kernel)的特殊形式的函数,这个函数中产生大量的组织成可以分配给多流处理器的计算线程。用CUDA术语来讲,我们加载一个核函数来创建一个由多个线程块组成的线程网格,线程块由多个线程组成。为了替换串行的计算,我们需要一种方法来告诉每个线程去执行哪一部分运算,换言之,访问哪一个输入的入口或者哪一个输出的出口,以及选择哪个计算或存储。CUDA通过为每个线程提供内建的索引变量来进行这样的编址。这些CUDA的索引变量会替换串行代码里的循环索引。加载核函数、创建计算网格、索引线程块和线程的具体过程将在2.2节中进行讨论。
