

本节书摘来自华章出版社《大数据系统构建:可扩展实时数据系统构建原理与最佳实践》一书中的第1章,第1.2节,南森·马茨(Nathan Marz) [美] 詹姆斯·沃伦(JamesWarren) 著 马延辉 向 磊 魏东琦 译,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.2 扩展传统数据库
我们将从许多开发人员的“起点”开始大数据的探索,直击传统数据库技术的局限性。
假设上司的要求是构建一个简单的网络分析应用程序。这个应用程序能追踪客户期望追踪的任何统一资源定位符(Uniform Resource Locator, URL)的页面浏览量。每接收到一次页面浏览,客户的网页就用其URL ping应用程序的Web服务器。此外,应用程序在任何时候都能根据页面浏览量给出前100排名的URL。
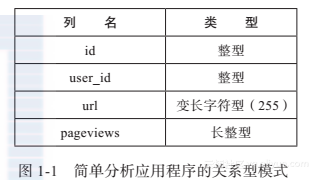
首先启动一个如图1-1所示的页面浏览量的传统关系型模式。其后端包括一个该模式的表的RDBMS和一个Web服务器。每当有人加载被应用程序追踪的网页时,这一网页带着页面浏览ping Web服务器,同时Web服务器会在数据库中增加相应的行。
让我们看看在完善应用程序时出现了什么问题。—如你所见,这里会遇到可扩展性和复杂性问题。
1.2.1 用队列扩展
网络分析产品获得了巨大的成功,应用程序的流量正像野火一样增长。例如,公司举办了一个盛大的派对,但庆祝时,你开
始从监控系统收到大量的电子邮件。这些邮件都在说同样的事情—“插入数据库时发生超时错误。”
你查看了日志,问题很明显—数据库跟不上负载,导致增加页面浏览量的写请求超时。
你需要尽快做些事情来解决这个问题。你会意识到每次只执行一次增量操作到数据库是很浪费的。如果你在单个请求中批处理多个增量操作,这样就可以更有效。所以你重构后端,使这一切成为可能。
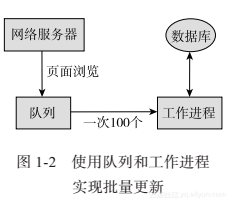
所谓重构后端,不是让Web服务器直接访问数据库,而是在Web服务器和数据库之间插入一个队列。当你收到一个新的页面浏览后,该事件被添加到队列中;然后创建一个一次从队列中读取100个事件的工作进程,并在单个数据库更新操作中批量插入它们,如图1-2所示。
这个方案执行得很好,它解决了超时问题。它甚至还有额外的好处—如果数据库再次超载,只会使队列变得更大,而不会导致Web服务器超时和潜在的数据丢失。
1.2.2 通过数据库分片进行扩展
不幸的是,添加队列并做批量更新只是可扩展性问题的一个“创可贴”。随着应用程序日渐受欢迎,数据库会再次超载。现有的工作进程跟不上写操作的速度,所以你尝试添加更多的工作进程来并行化更新。不幸的是,这并未起到多大的作用—显然,数据库是瓶颈。
使用Google搜索如何扩展写操作频繁的关系型数据库,你会发现最好的方法是使用多个数据库服务器,并在所有服务器上分散该表,使每个服务器拥有该表所包含数据的一个子集。这种方式被称为水平分区或分片。这种技术通过多个机器分散写操作的负载。
这里使用的分片技术是通过分片的数量对键的散列值进行取模,以此为每个键选择分片。使用散列函数将键映射到分片,可以使键均匀分布到所有分片。接下来写一个脚本来映射单个数据库实例中的所有行,并把数据分割成四个分片。这个脚本需要一段时间来运行,所以你要关掉增加页面浏览的工作进程,以便让该脚本完成运行,否则在转换时会丢失页面浏览的增量。
最后,所有应用程序代码需要“知道”如何为每个键找到分片。这就需要将用于从配置文件中读取分片数量的数据库处理代码封装成一个库,并且重新部署所有应用程序代码。你必须修改前100个URL的查询,从每个分片中获取前100个URL并将它们合并,用来获得全局的前100个URL。
随着应用程序变得越来越流行,用户不得不将数据库重新切分成更多的分片,才能跟得上写操作的负载。每次重新分片会让你觉得越来越痛苦—因为有很多工作进程需要协调,而且不能只运行一个脚本进行重新分片,那样速度会很慢。你必须并行地重新分片,并且同时管理大量的活跃工作进程的脚本。如果开发者忘记更新应用程序代码与新的分片数量,则会导致大量的增量操作写入错误的分片,因此必须编写一次性脚本来手动检查数据和移动任何错位的数据。
1.2.3 开始处理容错问题
最终,系统中有如此多的分片,以至于其中一台数据库机器的硬盘频出故障。当计算机宕机时,这部分数据是不可用的。解决这个问题的方法如下:
更新队列或工作进程系统,将不可用分片的增量操作放入一个单独的“等待”队列,且试图每5min刷新一次“等待”队列。
使用数据库的复制功能为每个分片添加一个从分片,所以这样就会有一个备份以防主分片出现故障。虽然客户不在从分片中执行写操作,但至少还可以在应用程序中查看状态。
开发者会有这样的想法:“早期我花费时间为客户构建新功能,现在看来我只有花费所有时间来处理读写数据的问题了。”
1.2.4 损坏问题
当运行队列或工作进程代码时,开发者在生产环境中不小心为每个URL部署了一个错误的网页浏览量的增量(为2,而不是1),直到24h后才意识到这个错误,但已经造成了损坏。因为无法知道哪些数据被损坏,所以每周的备份起不到帮助作用。虽然这种方式试图使系统具备可扩展性和对机器故障的可容忍性,但无法使系统具备对人为错误的应对方式。无论你怎样努力试图阻止错误的产生,它都将不可避免地在生产环境中出现。
1.2.5 到底是哪里出错了
随着简单网络分析应用程序的发展,系统不断变得越来越复杂:队列、分片、副本、重新切分的脚本等。在数据上开发应用程序,不仅需要知道数据库模式,还需要知道更多的东西。代码需要知道如何与正确的分片通信,如果出错,从错误的分片进行读或写操作将是不可避免的。
还有一个问题是,数据库对它的分布式特性不是自我感知的,因此它不能帮客户处理分片、副本和分布式查询。这种复杂性在操作数据库和开发应用程序代码的部分中都会存在。
但最严重的问题是,系统并不是针对人为错误设计的。恰恰相反,实际上,随着系统变得越来越复杂,它越来越有可能产生错误。软件中的错误是不可避免的,如果不是在研发时犯错,则可能是写了任意破坏数据的脚本。备份无疑是不够的,开发者必须仔细考虑系统的设计方法,以降低人为错误可能导致的损害。容忍人为错误不是随意的,尤其在大数据给构建应用程序添加那么多复杂性时它更加必要。
1.2.6 大数据技术是如何起到帮助作用的
我们所要学习的大数据技术,将以令人瞩目的方式解决这些可扩展性和复杂性问题。首先,为大数据所使用的数据库和计算系统是可以感知到自己的分布式特性的,所以可以帮助客户处理诸如分片和备份这些事情。用户不会遇到不小心查询了错误的分片的场景,因为这种逻辑是内化在数据库中的。扩展时,用户只需添加节点即可,系统将会自动重新调整到新的节点。
我们将了解的另一个核心技术是“使数据不可变”,即不是存储页面浏览量作为核心数据集,而是要存储原始网页浏览信息。因为随着新页面浏览的传入,存储页面浏览量需要用户不断地改变数据集。而原始网页浏览信息是从来不会改变的。所以当出现错误时,你可能会写入损坏的数据,但至少不会破坏良好的数据。基于数据变化方面,这是一个比传统系统更为强大的容忍人为错误的保证。对于传统的数据库,用户应谨慎使用不可变数据,因为这样的数据集将以很快的速度增长。但由于大数据技术可以扩展到如此多的数据,开发者就可以用不同的方式设计系统。




