本节书摘来自华章出版社《python 与数据挖掘 》一书中的第2章,第2.5节,作者张良均 杨海宏 何子健 杨 征,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.5 文件的读写
文件访问是一门语言重要的一环,适当地进行文本读写能够保存一次程序运行下来的结果。在数据挖掘的工作中,数据量很大,整个挖掘程序可以分为几部分,我们应该把每一部分运行的结果都保存下来,这样如果后面的程序出现错误,我们也不必再从头开始。而数据挖掘中最普遍的是对txt、csv等文件进行读写处理。
2.5.1 改变工作目录
要进行文件的读写,首先要设置工作目录。如果使用脚本运行,那么默认的工作目录为脚本所在的目录。但大多数时候我们会将数据文件放在某个固定目录,要改变工作目录,首先要引入os模块,语句为:import os。查看当前工作目录的方法是os.getwd(),改变工作目录的方法是os.chdir(string),如代码清单2-21所示:
代码清单2-21 改变工作目 录
import os
os.chdir('F:/Data') # 改变路径至F盘的Data文件夹下,注意不是反斜杠
print os.getcwd()
# result: F:\数据集
*代码详见:示例程序/code/2-5.py2.5.2 txt文件读取
Python进行文件读写的函数是open或file。其格式如下:
file_handler = open(filename,mode='r')
其中filename是我们希望打开的文件的字符串名字,mode表示我们的读写模式,所有模式如表2-10所示,默认为read模式。如果此语句执行成功,那么一个文件句柄就会返回,后面的文件操作需依赖文件句柄的方法进行。表2-11给出了文件句柄的所有方法。
表2-10 读写模式
模式 说明
‘r’ 以读方式打开文件,仅可读取文件信息
‘w’ 以写方式开始文件,仅可向文件写入信息。如果文件存在,则清空该文件,再进行写入。如果文件不存在则自动创建
‘a’ 以追加模式打开文件,文件指针自动移动到文件末尾,仅可从文件末尾开始写入,如果文件不存在则自动创建
‘r+’ 以读写方式打开文件,可对文件进行读写操作
‘w+’ 消除文件内容,然后以读写方式打开文件。如果文件不存在则自动创建
‘a+’ 以读写方式打开文件,并把文件指针移到文件末尾。如果不存在则自动创建
‘b’ 以二进制模式打开文件,而不是以文本模式
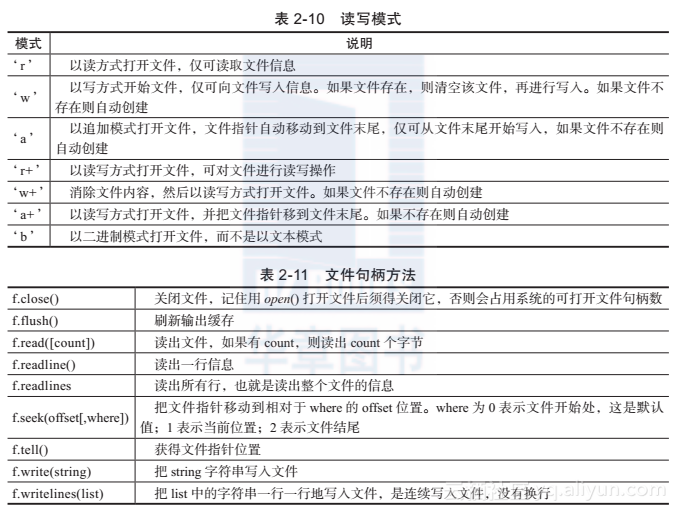
表2-11 文件句柄方法
f.close() 关闭文件,记住用open()打开文件后须得关闭它,否则会占用系统的可打开文件句柄数
f.flush() 刷新输出缓存
f.read([count]) 读出文件,如果有count,则读出count个字节
f.readline() 读出一行信息
f.readlines 读出所有行,也就是读出整个文件的信息
f.seek(offset[,where]) 把文件指针移动到相对于where的offset位置。where为0表示文件开始处,这是默认值;1表示当前位置;2表示文件结尾
f.tell() 获得文件指针位置
f.write(string) 把string字符串写入文件
f.writelines(list) 把list中的字符串一行一行地写入文件,是连续写入文件,没有换行
我们常用的文件读入函数是readline()和readlines()。首先我们假设在我们脚本目录下有这样一个data.txt,其数据如下:
1,2
3,4
注意第一行中有一个换行符。如果我们采用readline()语句读取,执行f=open('data.txt','r')和 a =f. readline(),那么就会将第一行以字符串的形式返回,此时a='1,2n'。同时文件指针指向第一行末尾,如果再执行语句b = f.readline(),那么b='3,4',此时文件指针就指向文件末尾,文件已读取完毕。可以使用下面的while循环读取所有语句:
L=2#文件的行数
for i in range(L):
a = readline()
# 对该行的处理如果我们想去掉第一行的读取的换行符,可以使用语句a=a.strip(),strip()可以去掉一个字符串开头和末尾的空白字符,包括换行符,已在2.4.2节中介绍到。
而readlines则返回一个列表,列表包含了每一行的字符串数据。如执行a=f.readlines(),那么此时a=['1,2n','3,4'],代码清单2-22给出了一个读取数据的例子,其数据是用于回归预测的COIL数据集。例子最终保存的形式是一个二维列表,在后面的数据处理可以很容易的变换为numpy.array,大部分数据挖掘的算法都需要numpy.array作为数据存储的格式。
代码清单2-22 文件读写
data=[] # 先定义存储数据的总列表,总列表的每个元素都是一个列表,各存储一行数据
fr = open('ticdata2000.txt') # 打开文件
for line in fr.readlines(): # readlines()返回一个字符串列表,每个字符串存储一行原始数据
line = line.strip() # 去掉换行符
data_line = line.split("\t") # 通过字符串的制表符"\t"分隔数据,并且返回一个列表,使用列表存储该行数据
data.append(data_line) # 将存储一行数据的列表添加到总列表中
print data[0] # 输出第一行的数据
fr.close()
*代码详见:示例程序/code/2-5.py2.5.3 csv文件读取
我们习惯使用Excel表存储数据,但Excel表数据直接用Python读取是行不通的。一个常用的办法是将文件另存为csv文件格式。csv是逗号分隔符的数据表,每两个数据单元间用逗号分隔,实际上和txt文件没有本质的区别。在代码清单2-22中,数据文件的数据是用制表符分隔的,如果改成用逗号分隔,再把后缀名改成csv,那就转换成了csv文件。同理,csv文件读取的处理与txt几乎一样,使用语句f=open('data.csv')读取,这里不再举例赘述。如果我们使用pandas模块,那么读入csv文件会更快捷方便,直接使用pandas.read_csv()方法即可,本书后面会介绍pandas模块。
2.5.4 文件输出
在2.5.2节中,我们把数据1,2,3,4成功读入到程序中,现在我们考虑,假设我们的程序中得出了一个二维列表data=[['1','2'],['3','4']],我们重新输出到文件,还原为2.5.2节中的原始数据。我们可以使用方法f.write(string),并且借助字符串的join方法输出到文件中。如果二维列表的元素不是字符类型而是整数类型,我们不能使用join方法,使用f.write(string)输出比较麻烦,这里介绍另一种更灵活的输出到文件的方式:print>>>f。这样就会把原本print函数输出到shell的内容改为输出到文件中,请参考代码清单2-23。
代码清单2-23 文件输出
f = open('output.txt','w')
# 使用join方法和write方法
data=[['1','2'],['3','4']]
line1 = ','.join(data[0])
f.write(line1+'\n')
line2 =','.join(data[1])
f.write(line2+'\n')
# 使用print>>>f,
data=[[1,2],[3,4]]
for line in data:
print>>>f,str(line[0])+','+str(line[1])+'\n',
f.close()
*代码详见:示例程序/code/2-5.py2.5.5 使用JSON处理数据
从代码清单2-23中读者可以看出,保存数值型数据比保存字符串类型的数据容易得多。因为wtite(string)方法只能输出字符串,且read()函数只会返回字符串,想转化为数值型数据需用int()这样的函数。当想保存列表和字典这样复杂的数据结构时,单靠read()和write()去人工解析是很困难的。幸运的是,Python允许用户使用常用的数据交换格式JSON(JavaScript Object Noation)。标准模块json可以接受Python数据结构,并将它们转换为字符串表示形式,此过程称为序列化(Serialize)。从字符串表示形式重新构建数据结构称为反序列化(Deserialize)。序列化和反序列化的过程中,表示该对象的字符串可以存储在文件中。
假设现在有一个字典x=dict(height=176,weight=60),可以使用y=json.dumps(x)将x转换为一个字符串y。反过来可以使用json.loads(y)将字符串转为原来的字典。如果想保存到文件中或读取JSON文件,可以使用上面函数的变体dump()和load(),代码清单2-24给出了具体实例。
代码清单2-24 使用json处理数据
import json
# 使用dumps()和loads()
x=dict(height=176,weight=60)
print '原始字典内容:',x
y = json.dumps(x) # 返回字符串
print '序列化后的字典:',y
x = json.loads(y)
print '反序列化后又还原为原始的字典:',x
# 使用dump()和load()
f=open('BigData.json','w')
json.dump(x,f) # 保存到文件中
f.close()
f=open('BigData.json','r')
print '从文件读取到的JSON:',json.load(f)
*代码详见:示例程序/code/2-5.py