pg_stat_statements是PG中监控数据库活动的重要插件,通过它可以获得SQL的统计信息,例如该SQL被调用了多少次,返回了多少记录,在读写数据上花了多少时间,这个对于监控数据库很有帮助。默认情况下,这个插件可以统计5000个SQL,如果不够可以调整pg_stat_statements.max这个GUC。
一般情况下,可以通过源码安装该插件:
1, 先编译安装pgsql
2,在pg源码的目录下执行 make install -C contrib/pg_stat_statements
3,修改pg的配置文件postgres.conf,在其中加上一行
shared_preload_libraries = 'pg_stat_statements'
4,启动数据库,执行下面的SQL添加该插件:
CREATE EXTENSION pg_stat_statements
该语句会在系统中创建一个视图pg_stat_statements,这个视图中包含了很多有用的监控信息.
前面说到这个插件默认统计5000个SQL,那么如果新执行了一个SQL,该插件则会以SQL的查询计划为输入来计算hash码,(这个hash码就是pg_stat_statements视图中的queryid),然后去查找插件中已经统计的SQL的queryid,如果发现该hash码和某个已经存在的SQL的queryid相同,则将统计结果累加到这个SQL的统计结果中;没有发现,则会添加到插件中,或是满了5000条了就通过类似LRU的算法替换掉某个SQL(这点细节需要看代码)。
因此,这个插件在比对SQL时,智能程度还是很高的,只有语义上相同才会当作相同的SQL。例如下面三个SQL:
select * from t1 where a =1;
select * from t1 where a =2;
select * from t1 where a =3;
会被这个插件当作一个SQL(严格上说是一类)。
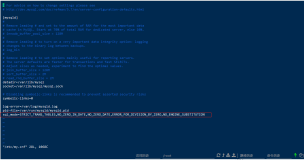
但是,有时候太智能也不太好:今天早上一个开发的同事来找我,说从pg_stat_statements中获得了很多重复的结果。登上他的测试环境,结果的确让人很奇怪:

很明显,结果中出现了三种重复的结果:一个是使用sql来执行pg_xlog_location_diff这个函数,一类是执行drop操作,最后一个就是执行insert 操作。
第一眼看上去很吃惊,但是查看了文档http://www.postgresql.org/docs/9.4/static/pgstatstatements.html,再结合下SQL的处理流程,可以回答为什么前会有前两种重复的结果:
对于执行select pg_xlog_location_diff() 这样的SQL,(抱歉,之前的解释不对,晚上回家看了代码,调试了一下,才发现之前的解释不对,pg还是会为这样只执行函数而不访问表的SQL生成查询计划的,只不过在优化的时候,已经获得了函数的结果),主要是因为执行SQL的用户不一样,所以插件认为是不同的SQL。并且,如果同一个用户连接不同的数据库去执行同一个SQL,插件也会认为是不同的SQL。
对于drop 操作的SQL重复出现,其实可以从文档里面就知道了,因为文档里面说的很明确了“Plannable queries (that is, SELECT, INSERT, UPDATE, and DELETE) are combined into a single pg_stat_statements entry whenever they have identical query structures according to an internal hash calculation.”
而对于insert 操作的SQL重复出现,刚开始怎么也无法解释,后来问了问开发的同学怎么操作数据库的,就恍然大悟了:因为他每次连数据库都会建立一个心跳表,这是个临时表,然后执行那一堆insert 操作来判断数据库是否活着。
一说临时表,就明白了七八分:因为他的临时表是session级别的,一个session连上来建立的临时表在断开session时,pg会自动删除临时表。虽然每次建立的临时表都是同一个表,一模一样,但是从数据库的角度来说,就是一个不同的表的了。所以每次session 第一次insert 这个表的SQL都会和前一次session执行的insert SQL是不同的,虽然他们字面上是一模一样的。当然,他们生成的查询计划的语义也是完全不一样的了。 而且考虑到pg_stat_statements的容量有限,最好还是建立一个非临时表。
本文来自云栖社区合作伙伴“DBGEEK”