热门
万字长文:一文彻底搞懂Elasticsearch中Geo数据类型查询、聚合、排序
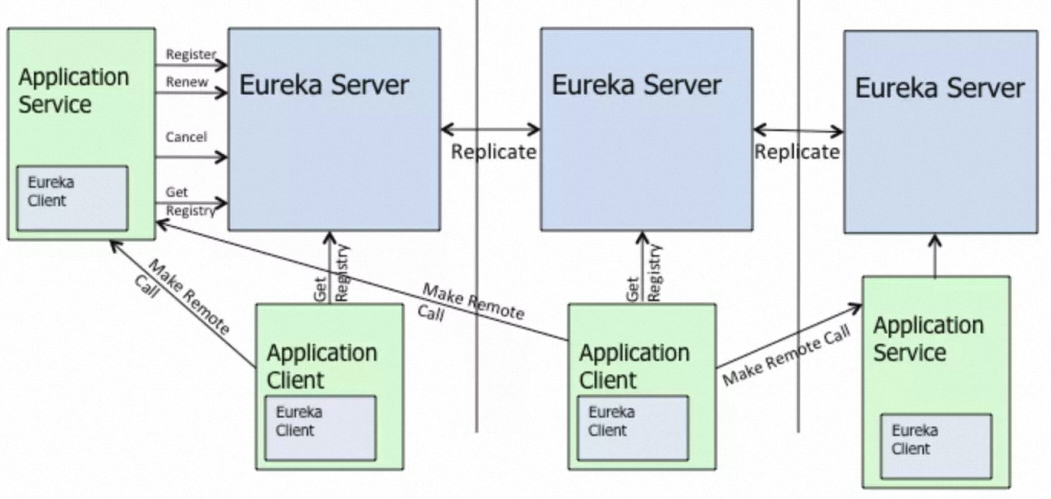
上一任留下的 Eureka,我该如何提升她的性能和稳定性(含数据比对)?
蚂蚁流场景状态演进和优化
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
设计模式之装饰者模式
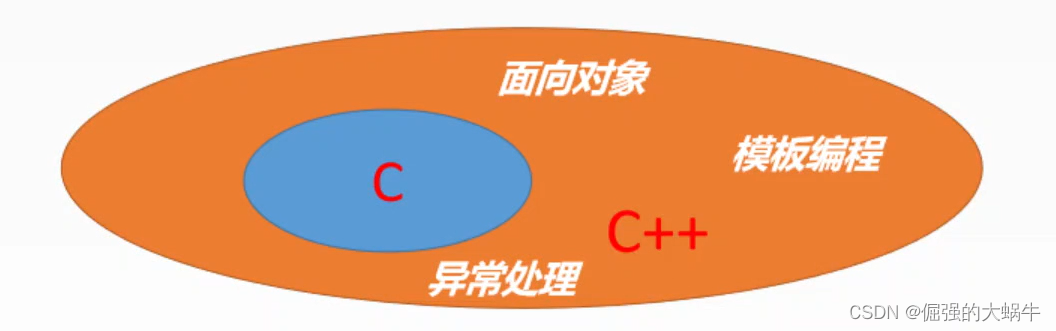
【C++成长记】C++入门 | 命名空间、输入输出、缺省参数
Qt 中的项目文件解析和命名规范
Java+saas模式 智慧校园系统源码MySQL5.7+ elmentui前后端分离架构 让校园管理更高效的数字化平台系统源码
实现Hello Qt 程序
Qt Creator 界面
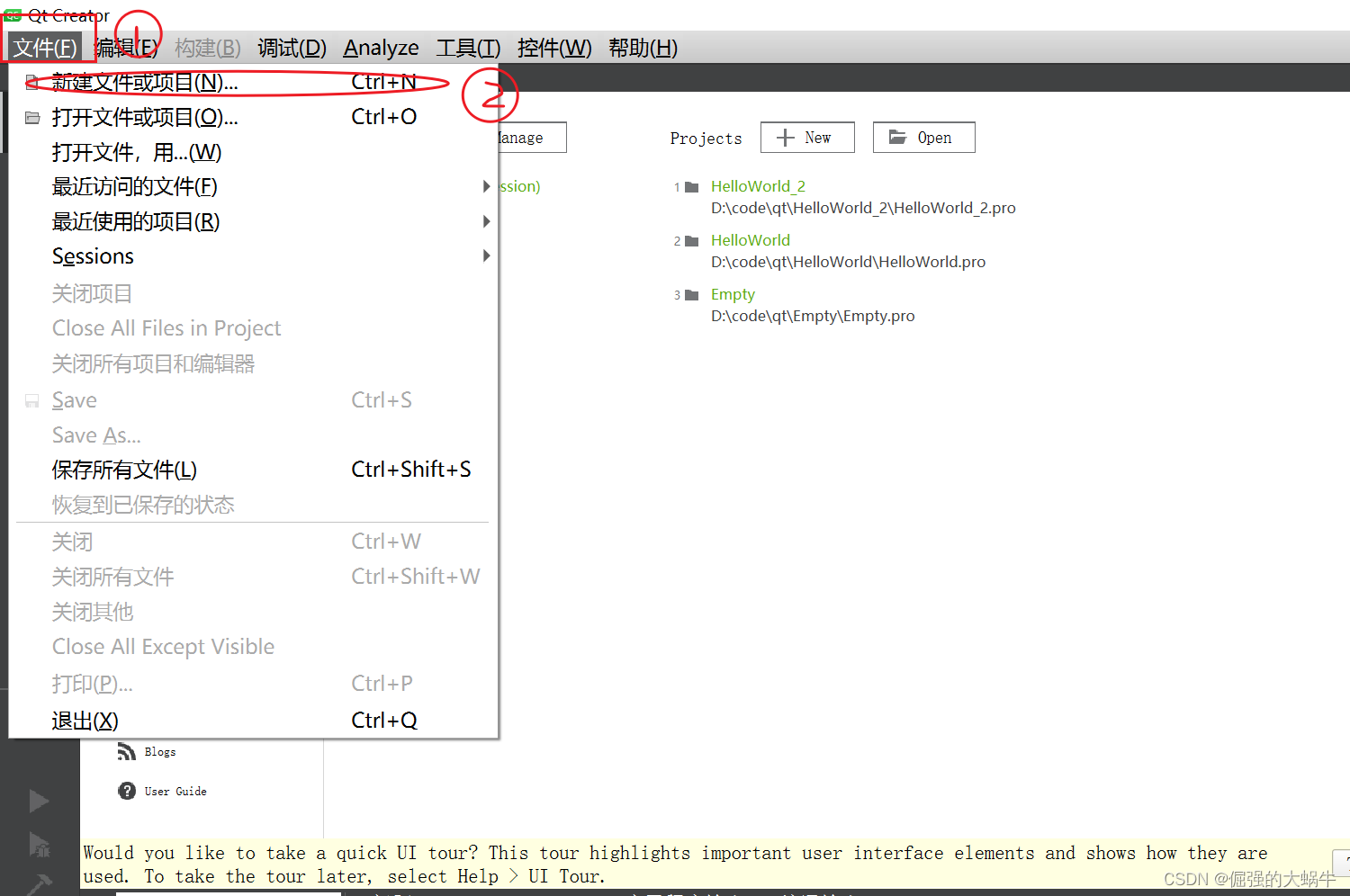
Qt Creator 新建项目
QT Creator概览
QT背景介绍
蓝队面试经验详细总结
Hive【基础知识 04】【Hive 属性配置的三种方式及配置的优先级说明】
Hive【基础知识 02-2】【Hive CLI 命令行工具使用】【详细举例-包含测试脚本文件】
Hive【基础知识 02-1】【Hive CLI 命令行工具使用】【准备阶段-建库、建表、导入数据、编写测试SQL脚本并上传HDFS】
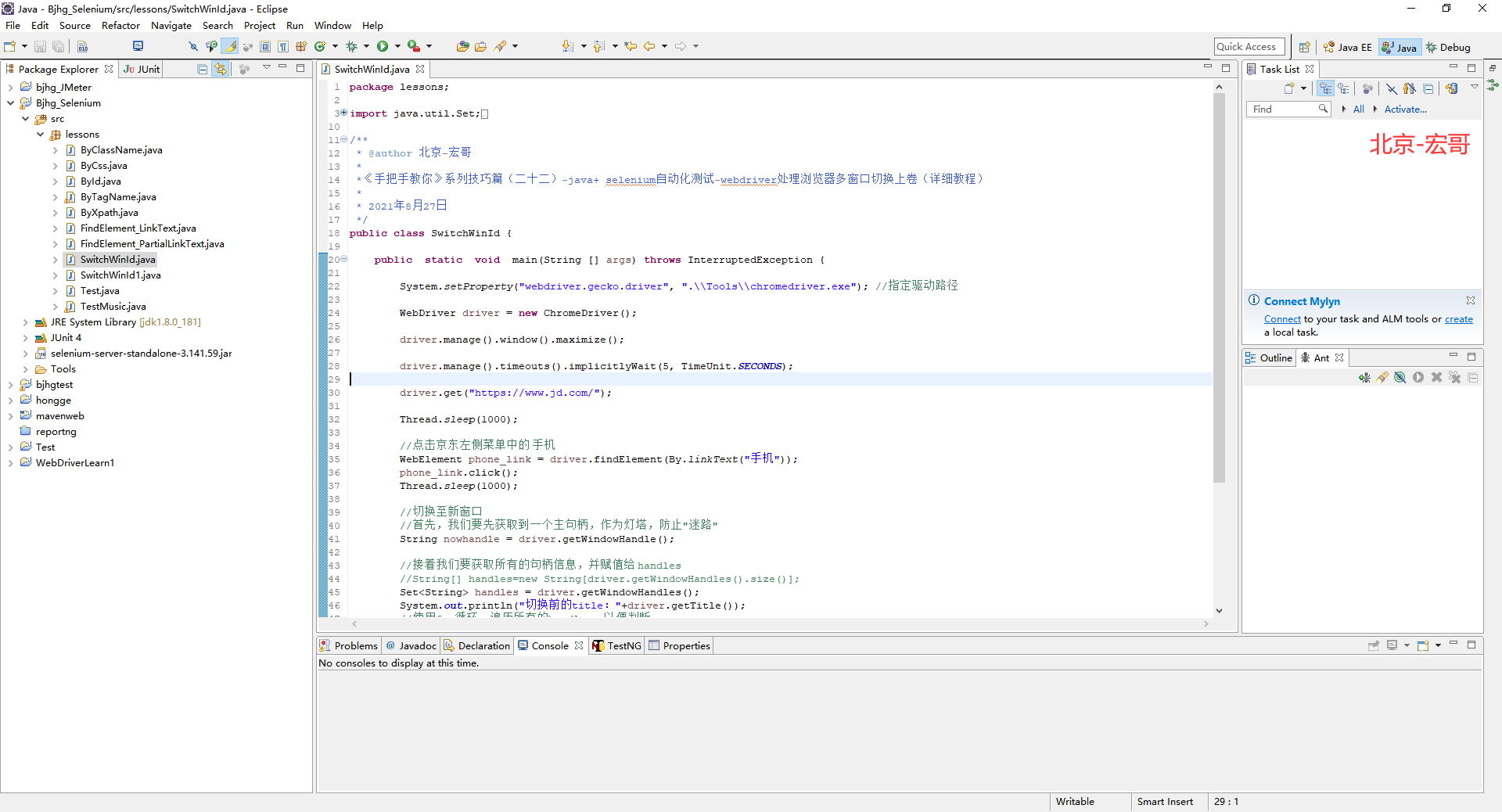
《手把手教你》系列技巧篇(二十二)-java+ selenium自动化测试-webdriver处理浏览器多窗口切换上卷(详细教程)
使用点晴模切ERP的好处有哪些?
算法的时间复杂度和空间复杂度
MongoDB性能最佳实践:如何制定更有效的基准测试?
说说Java 8 引入的Stream API
浅谈Java21的新特性-虚拟线程
VSCode插件分享--免费的ER工具
git常用操作+常见问题汇总
SQL Server的索引选择
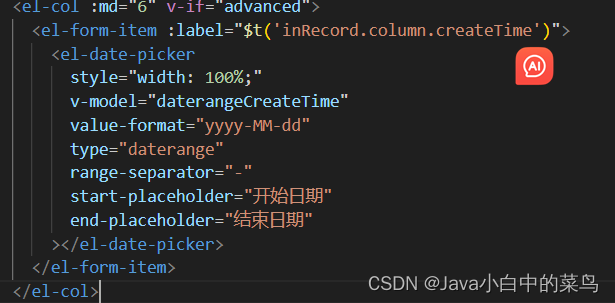
如何在vue添加echarts图表
前端开发使用 Vue 3 + TypeScript + Pinia + Element Plus + ECharts
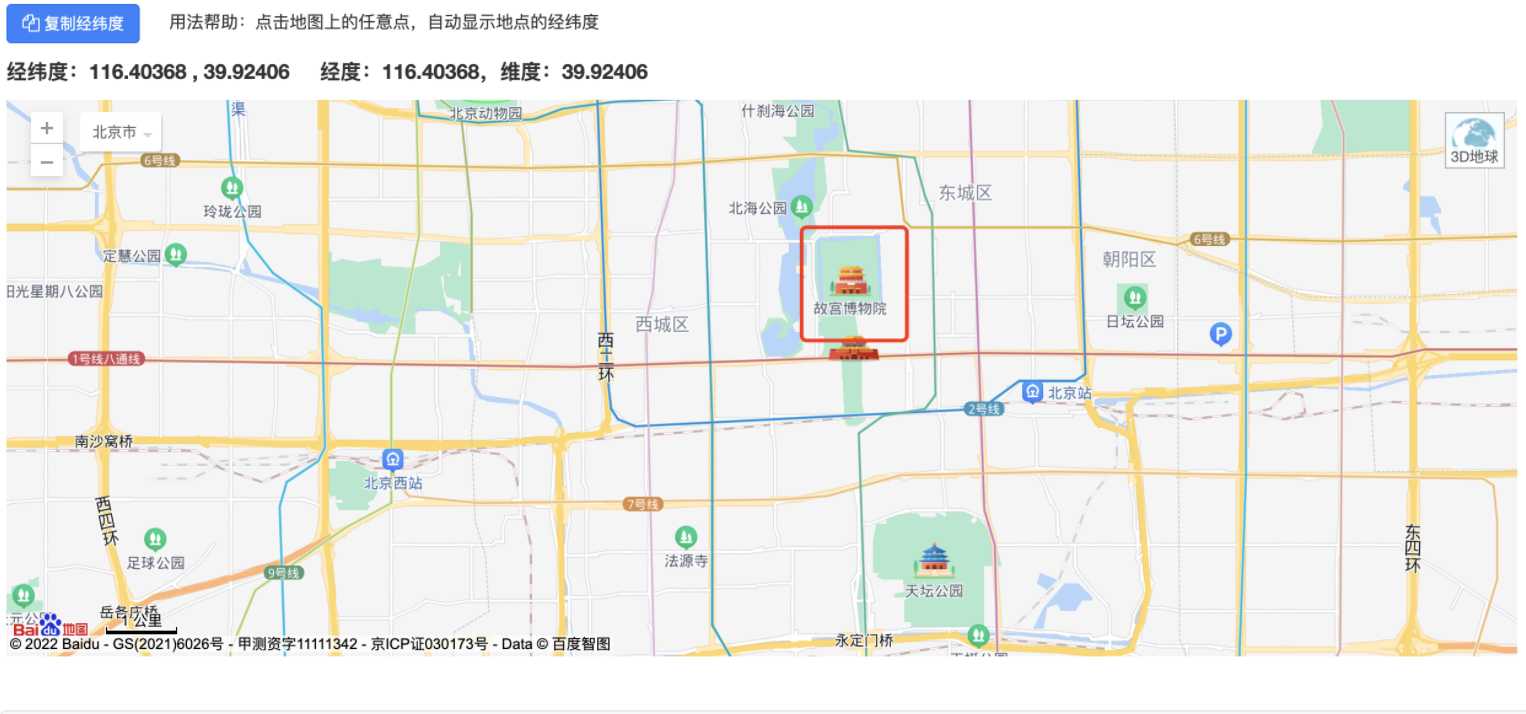
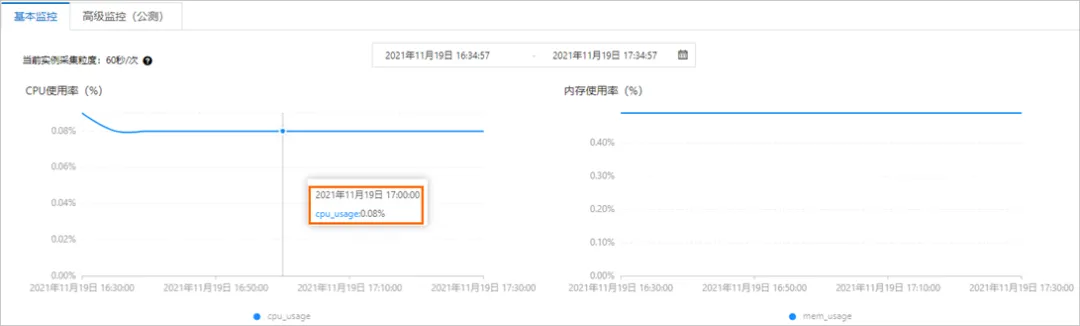
区间时间检索
[绝对要收藏]配置hadoop完全分布式环境
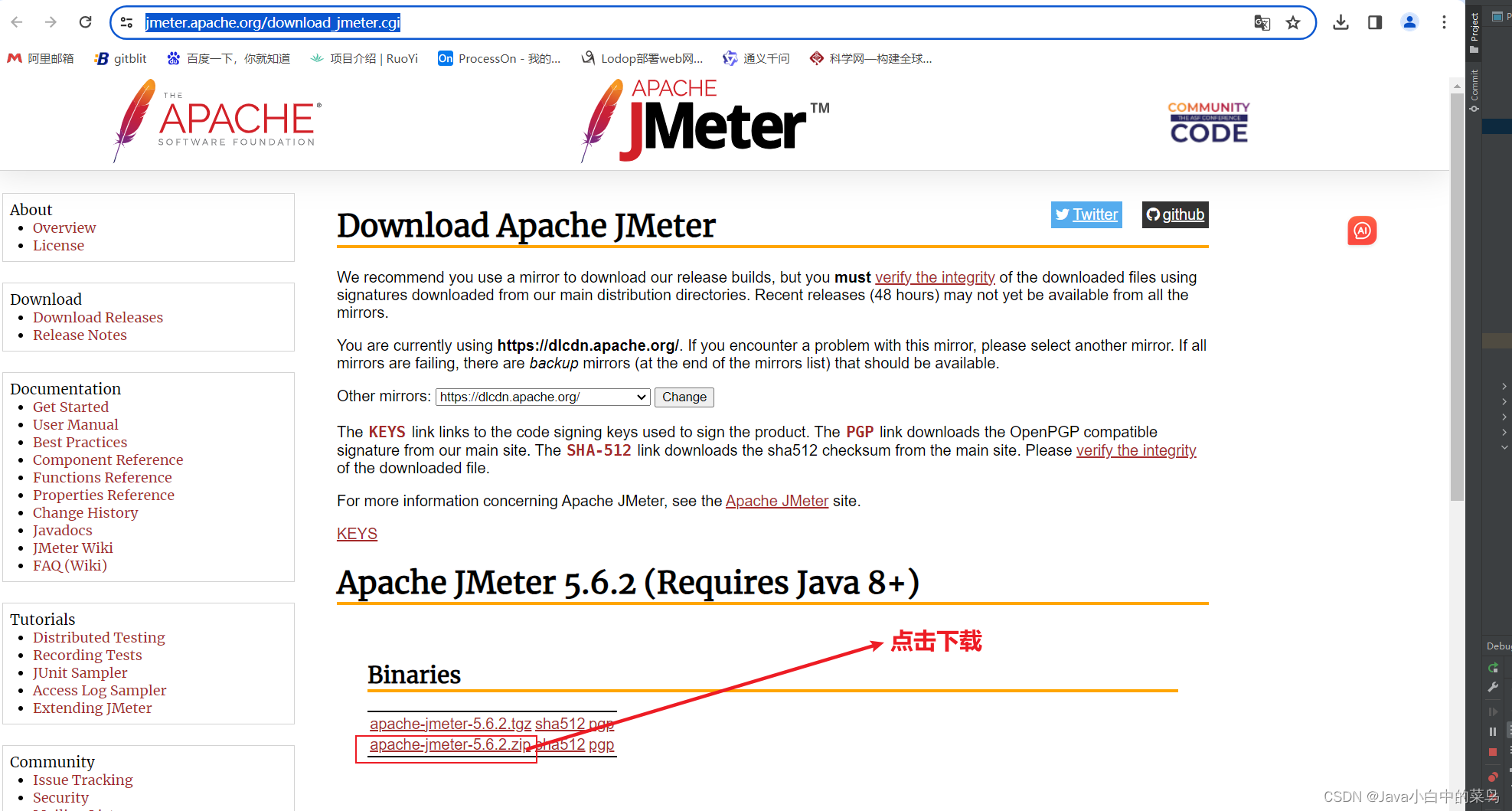
Jmeter的安装与快速使用(做并发测试)
shardingsphere集成mybatis/mybatis-plus快速实现简单分片
捕捉不到异常
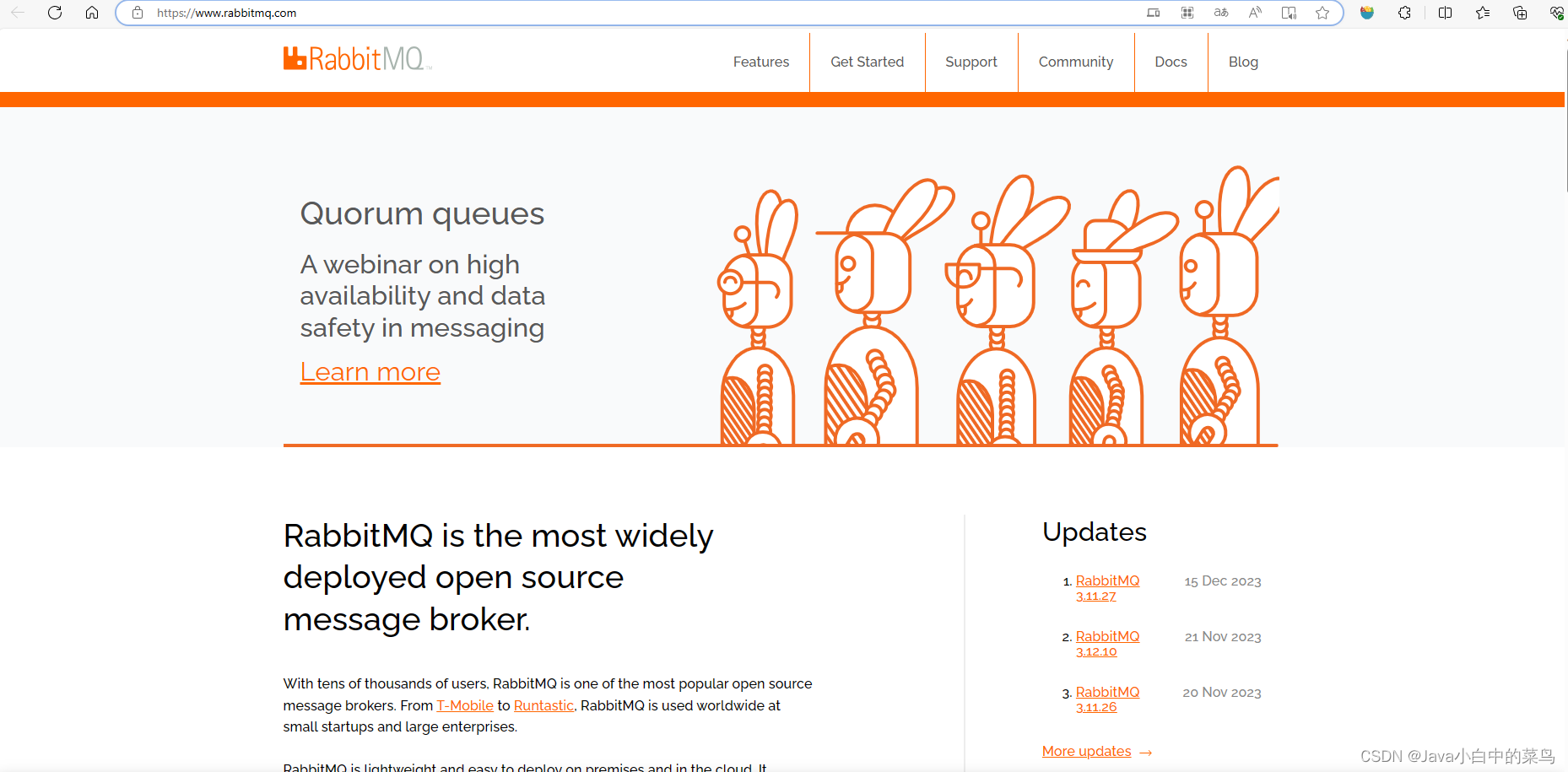
Window系统下载与安装RabbitMQ
多个app的模型间引用外键
快来参加训练营学技能还能领奖品
Vue+ElementUI前端添加展开收起搜索框按钮
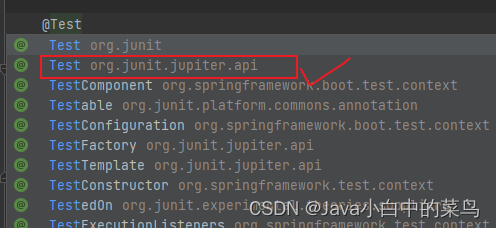
java.lang.Exception: Method a() should be public
云服务器初次连接宝塔,连接不上
map.getOrDefault
sql server查看所有表名以及注释
MySQL忘记密码后重置密码
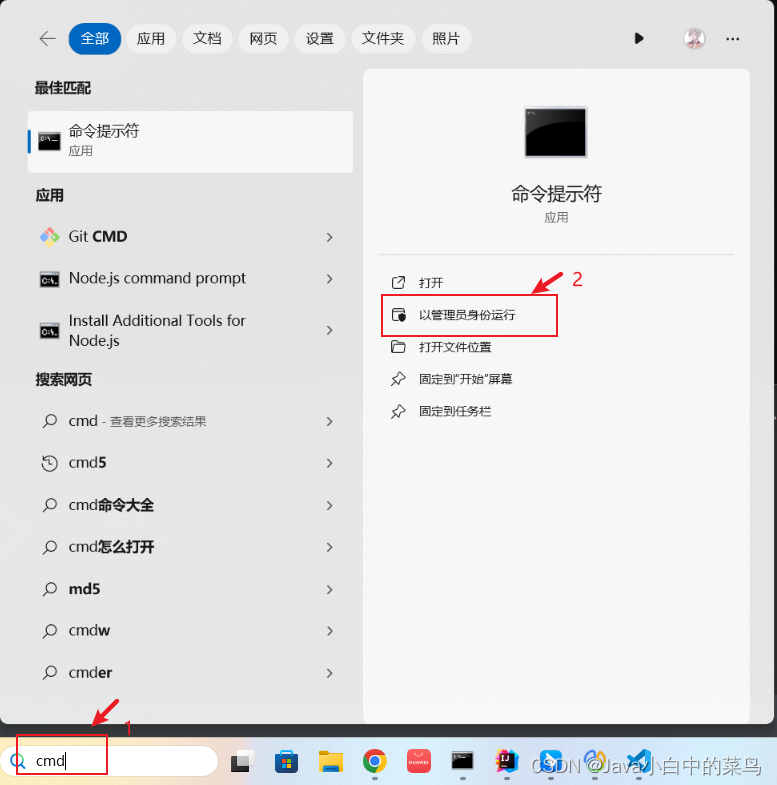
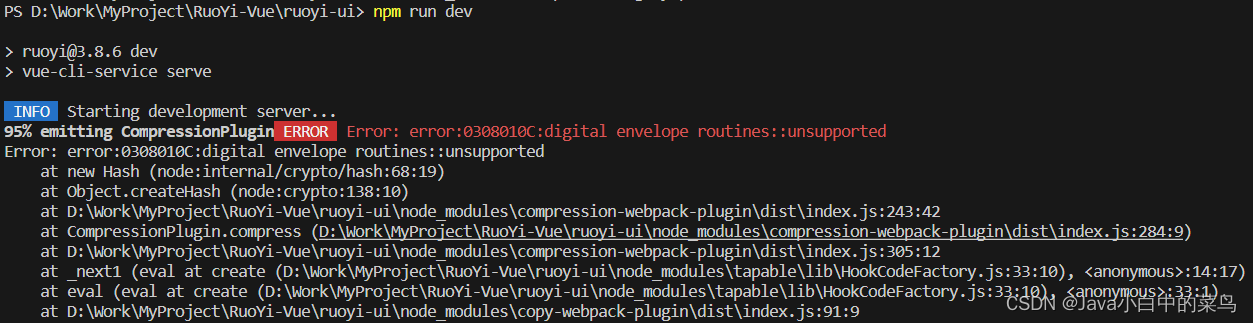
解决Error: error:0308010C:digital envelope routines::unsupported最快速方案
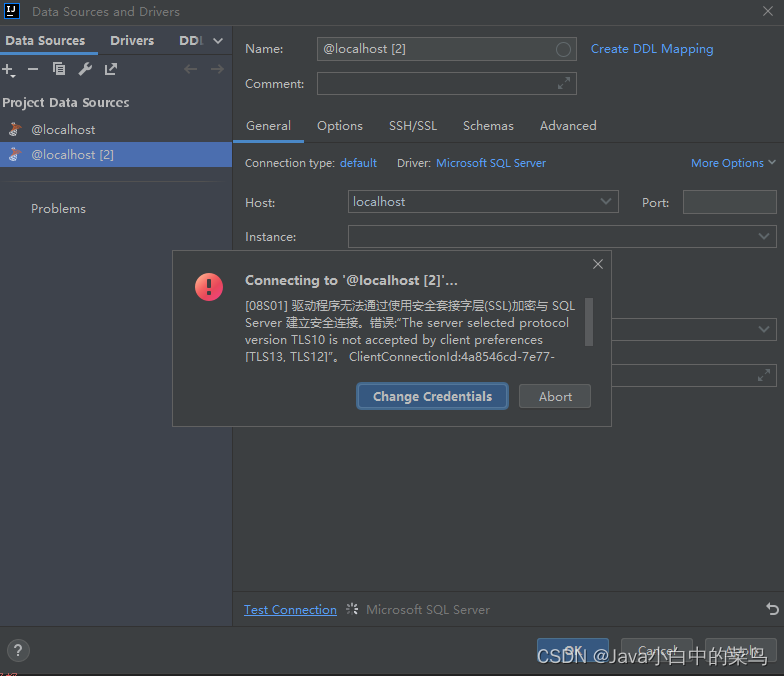
IDEA DataGrip连接sqlserver 提示驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接的解决方法
对引用拷贝,浅拷贝,深拷贝的理解
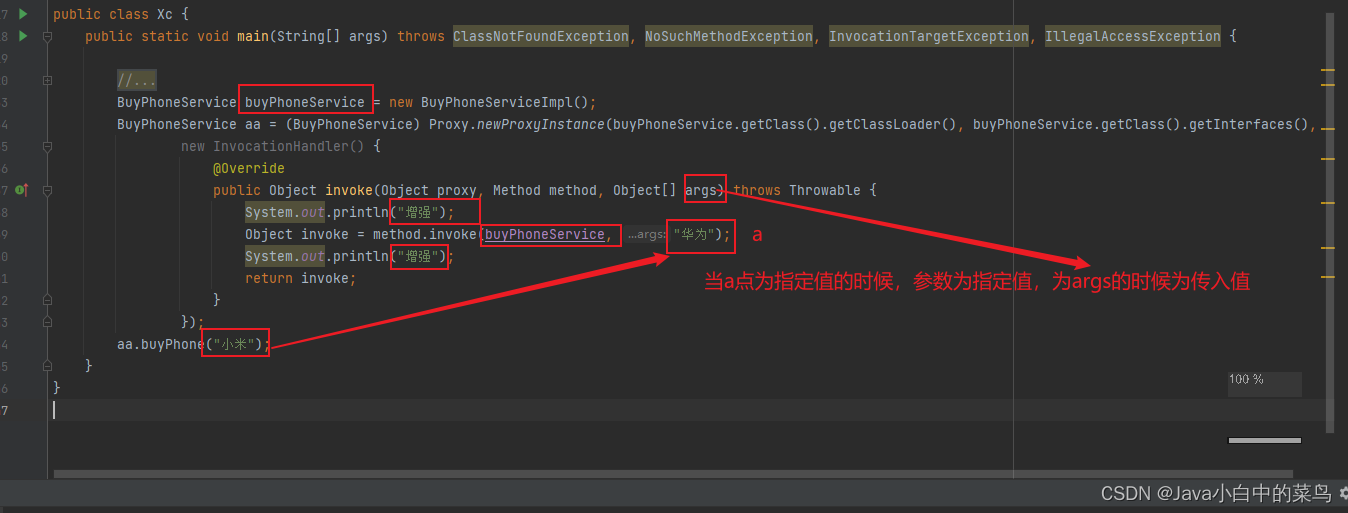
动态代理的实现(基于匿名内部类)
动态代理为什么能称之为动态
视图函数中创建模型, 并设置外键
反射的笔记