在一个怡人的午后,我开始尝试着用通俗易懂的语言向我妈妈解释随机性对于深度学习的重要性。尽管我妈妈还是对于深度学习一知半解,但是我认为我的努力部分成功了,我迷上了这种方式并将它应用在了我的实际工作中。
我想将这篇稍具技术性的小文章送给在深度学习领域的实践者,希望大家能够对神经网络内部的运行过程有更好的理解。
* * *
如果你是一个刚刚入门的新手,那么你有可能会觉得一大堆技术被随意的一股脑的用在了训练神经网络上,例如dropout正则化、扩增梯度噪声、异步随机下降。那这些技术有什么相同的呢?答案是他们都利用了随机性!
随机性是深度神经网络正常运行的关键:
· 随机噪声使得神经网络在单输入的情况下产生多输出的结果;
· 随机噪音限制了信息在网络中的流向,促使网络学习数据中有意义的主要信息;
· 随机噪声在梯度下降的时候提供了“探索能量”,使得网络可以寻找到更好的优化结果。
单输入多输出
* * *
(单进多出)
让我们假设你正在训练一个深度神经网络去实现分类。
对于图中的每一个区域,网络会学习将图像映射到一系列的词语标签上,例如“狗”或者“人”。
这样的分类表现很不错,并且这样的深度神经网络不需要在推理模型中加入随机性。毕竟任何一张狗的图片应该被映射到“狗”这个词语标签上,这没有任何的随机性。
现在让我们来假设你在训练一个深度神经网络下围棋,在下图这样的情况下,深度神经网络需要落下第一个棋子。如果我们还是使用确定不变的策略,那么将无法得出一个好的结果。你可能会问,为什么啊?因为在这样的情况下最优的“第一步”选择不是唯一的,对于棋盘上的每一个位置来说,他们都和对面位置具有旋转对称性,所以具有相同的机会成为较优的选择。这是一个多元最优问题。如果神经网络的策略是确定并且是单输入单输出的话,优化过程会迫使网络选择移向所有最佳答案的平均位置,而这个结果不偏不倚的落在了棋盘的中心,这恰恰在围棋里被认为是一个糟糕的先手。
所以,随机性对于一个想输出多元最优估计的网络十分重要,而不是一遍遍重复输出相同的结果。当行动空间暗含对称性的情况下,随机性一个十分关键的因素,在随机性的帮助下,我们可以打破夹杂中间不能自拔的对称悖论。
同样的,如果我们想训练一个神经网络去作曲或者画画,我们当然不希望它总是演奏相同的音乐,描绘单调重复的场景。我们期待得到变化的韵律,惊喜的声音和创造性的表现。在结合随机性的深度神经网络中,一方面保持了网络的确定性,但是另一方面将其输出变成为概率分布的参数,使得我们可以利用卷积采样方法画出具有随机输出特性的样例图片。
DeepMind的阿法狗采用了这样的原则:基于一个给定的围棋盘图片,输出每一种走棋方式的获胜的概率。这种网络输出的分布建模被广泛应用与其他深度强化学习领域。
随机性与信息论
* * *
在刚刚接触概率论与数理统计时,我十分纠结于理解随机性的物理含义。抛一枚硬币时,结果的随机性来自哪里?随机性是否仅仅是确定性混沌?是否可以做到绝对的随机?
老实地说,我还是没有完全弄明白这些问题。
信息论中将随机性定义为信息的缺失。具体来说一个物体的信息便是在计算机程序里能确定描述它的最小字节数。例如π的前一百万个字节可以被表示为字节长度为1,000,002个字符,但是同样也可以被完整的用70个字符表示出来,如下用莱布尼茨公式所示:
上面的公式是π的一百万个数据的压缩表示。而更为精确的公式可以将π的前一百万个数据表示为更少的比特。从这个角度去解释的话,随机性是不可以被压缩的量。π的前一百万个量可以被压缩说明它们不是随机的。经验证据表明π是一个正规数(normal number),π中编码的信息是无穷的。
我们现在考虑用数字a表示π的前万亿个位数,如a=3.14159265...。如果我们在其中加上一个随机数r属于(-0.01,0.01),我们将会得到一个处于3.14059...和3.14259...之间的数。那么a+r里的有效信息只有三位数,因为加性随机噪声破坏了百位小数以后数位携带的信息。
迫使深度神经网络学到简洁表示
* * *
这个随机性的定义(指“随机性是不可以被压缩的量”,译者注)与随机性有什么联系呢?
随机性嵌入到深度神经网络的另一种途径是直接将噪声嵌入到网络本身,这与用深度神经网络去模拟一个分布不同。这种途径使得学习任务变得更加困难,因为网络需要克服这些内在的“扰动”。
我们到底为什么想要在网络中引入噪声?一个基本的直觉是噪声能够限制数据通过网络传输的信息容量。
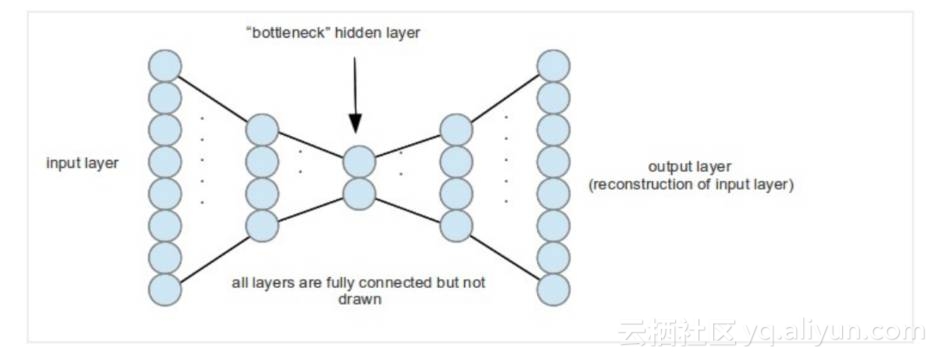
我们可以参考自动编码(auto-encoder)模型,这种神经网络结构尝试通过“压缩”输入数据、在隐含层得到更低维度的表示来得到有效的编码,并且在输出层重构原始数据。下面是一个示意图:
在训练过程中,输入数据从左边通过网络的节点,在右边出来,非常像一个管道。
假设我们有一个理论上存在的神经网络,其可以在实数(而不是浮点数)上训练。如果该网络中没有噪声,那么深度神经网络的每一层实际上都在处理无穷多的信息量。尽管自动编码网络可以把一个1000维的数据压缩到1维,但是这个1维的数可以用实数去编码任意一个无穷大维度的数,如3.14159265……
因此网络不需要压缩任何数据,也学不到任何有意义的特征。尽管计算机不会真的把数字以无穷维精度表示,但它倾向于给神经网络提供远远超过我们原本希望的数据量。
通过限制网络中的信息容量,我们可以迫使网络从输入特征里学到简洁的表示。现在已经有几种方法是这么做的:
• 变分自动编码(VAE) – 其在隐含层里加入高斯噪声,这种噪声会破坏“过剩信息”,迫使网络学习到训练数据的简洁表示。
• Dropout正则化与变分自动编码的噪声紧密相关(可能等价?) - 其随机将网络中的部分单元置为0,使其不参与训练。与变分自动编码相似,dropout噪声迫使网络在有限的数据里学习到有用的信息。
• 随机深度的深度网络 – 思想与dropout类似,但不是在单元层面上随机置0,而是随机将训练中的某些层删除,使其不参与训练。
• 有一篇非常有趣的文章是《二值化神经网络》(Binarized Neural Networks)。作者在前向传播中使用二进制的权重和激活,但在后向传播中使用实值的梯度。这里网络中的噪声来自于梯度—— 一种带噪声的二值化梯度。二进制网络(BinaryNets)不需要比常规的深度神经网络更加强大,每个单元只能编码一个比特的信息,这样正则是为了防止两个特征通过浮点编码被压缩在一个单元里。
更加有效的压缩方案意味着测试阶段的更好的泛化能力,这也解释了为什么dropout对防止过拟合如此有效。如果你决定用常规的自动编码而不是变分自动编码,你必须用随机正则化技巧,比如dropout,去控制压缩后的特征的比特数,不然你的网络将非常可能过拟合。
客观地说,我觉得变分自动编码网络(VAEs)更有优势,因为它们容易实现,并且允许你精确指定每层网络有多少比特的信息通过。
在训练中避免局部最小值
* * *
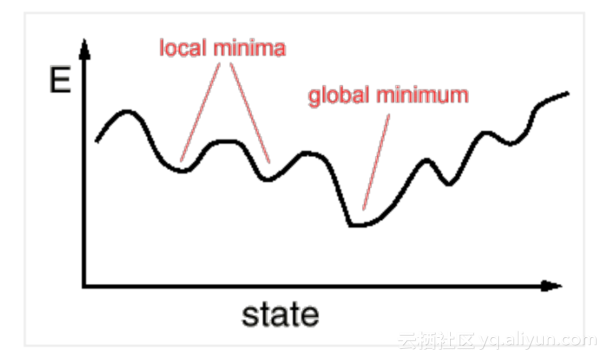
训练深度神经网络通常是通过梯度下降的变体来完成,基本意味着网络是通过降低在整个训练数据集上的平均损失误差来迭代参数。这就像从山上向山下走,当你走到山谷最底部的时候,你会找到神经网络的最优参数。
这种方法的问题是,神经网络的损失函数表面有很多个局部最小值和高原(因为网络拟合的函数通常非凸,译者注)。网络的损失函数很容易陷入一个小坑里,或者陷入一个斜率几乎为0的平坦区域(局部最小值),但你觉得此时还没有得到满意的结果。
随机性到底如何帮助深度学习模型?我的第三点解释是基于探索的想法。
因为用于训练深度神经网络的数据集通常都非常大,如果我们在每次梯度下降中对上千兆的数据通通计算梯度,这个计算量实在是太大了!事实上,我们可以使用随机梯度下降算法(SGD)。在这个算法里,我们只需要从数据集中随机挑选小部分数据,并且计算其平均梯度就可以了。
在进化中,如果物种的成功延续用随机变量X模拟,那么随机的突变或噪声会增加X的方差,其子孙可能会远远变得更好(适应性,防毒能力)或者远远变得更差(致命弱点,无法生育)。
在数值优化中,这种“基因突变”被称为“热力学能量”或“温度”,其允许参数的迭代轨迹并非总走“下山路”,而是偶尔地从局部最小值跳出来或者通过“穿山隧道”。
这些都与增强学习里的“探险-开采”平衡紧密相关。训练一个纯确定性的、没有梯度噪声的深度神经网络,其“开采”能力为0、直接收敛到最近的局部最小点,而且网络是浅层的。
使用随机梯度(通过小批量样本或在梯度本身加入噪声)是一个允许优化方法去做一些“搜索”和从局部最小值“跳出”的有效途径。异步随机梯度下降算法是另一个可能的噪声源,其允许多个机器并行地计算梯度下降。
这种“热力学能量”保证可以破坏训练的早期阶段中的对称性,从而保证每层网络中的所有梯度不同步到相同的值。噪声不仅破坏神经网络在行为空间中的对称性,而且破坏神经网络在参数空间里的对称性。
最后的思考
* * *
我发现有个现象非常有趣,即随机噪声事实上在帮助人工智能算法避免过拟合,帮助这些算法在优化或增强学习中找到解空间。这就提出了一个有趣的哲学问题:是否我们的神经编码中的固有噪声是一种特征,而不是瑕疵(bug)。
有一个理论机器学习问题让我很有兴趣:是否所有的神经网络训练技巧事实上是某些通用正则化定理的变形。也许压缩领域的理论工作将会对理解这些问题真正有所帮助。
如果我们验证不同神经网络的信息容量与手工设计的特征表示相比较,并观察这些比较如何关系到过拟合的趋势和梯度的质量,这会是一件非常有趣的事情。度量一个带有dropout或通过随机梯度下降算法训练的网络的信息容量当然不是没有价值的,而且我认为这是可以做到的。比如,构建一个合成矢量的数据集,这些矢量的信息容量(以比特,千字节等为单位)是完全已知的,我们可以通过结合类似于dropout的技巧,观察不同结构的网络如何在这个数据集上学到一个生成式模型。
-END-
本文来源于"中国人工智能学会",原文发表时间"
深度 | Google Brain研究工程师:为什么随机性对于深度学习如此重要?
2017-05-02
2199
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:





目录
相关文章
|
3月前
|
机器学习/深度学习
自然语言处理
数据挖掘
|
2月前
Google Earth Engine(GEE) ——如何获取指定研究区范围内的单个影像的时间,这里求具体的天数,以landsat9影像为例。
Google Earth Engine(GEE) ——如何获取指定研究区范围内的单个影像的时间,这里求具体的天数,以landsat9影像为例。
55
0
0
|
5天前
|
机器学习/深度学习
传感器
自动驾驶
基于深度学习的图像识别技术在自动驾驶系统中的应用研究
【4月更文挑战第20天】
本研究聚焦于深度学习技术在图像识别领域的应用,并探讨其在自动驾驶系统中的实际效用。文章首先回顾了深度学习与图像处理技术的基础知识,随后详细分析了卷积神经网络(CNN)在车辆环境感知中的关键作用。通过实验数据对比分析,本文验证了所提出算法在提高自动驾驶车辆对周围环境的识别准确性和实时性方面的有效性。最后,讨论了目前技术的局限性及未来可能的研究方向,旨在为进一步的技术突破提供参考。
10
0
0
|
3月前
|
机器学习/深度学习
搜索推荐
算法
|
1月前
|
机器学习/深度学习
传感器
自动驾驶
基于深度学习的图像识别技术在自动驾驶系统中的应用研究
【2月更文挑战第24天】
随着人工智能技术的飞速发展,深度学习已成为推动技术创新的核心力量之一。特别是在图像识别领域,深度学习技术凭借其卓越的特征提取和模式识别能力,已广泛应用于自动驾驶系统中,成为实现车辆环境感知的关键技术。本文旨在探讨基于深度学习的图像识别技术如何优化自动驾驶系统的性能。通过分析卷积神经网络(CNN)在道路标识检测、行人识别和障碍物分类等任务中的应用实例,评估其在提高自动驾驶安全性和可靠性方面的作用。同时,文章还将讨论当前面临的挑战及未来的发展趋势,为自动驾驶领域的进一步研究提供参考。
14
0
0
|
7月前
|
机器学习/深度学习
人工智能
自然语言处理
|
8月前
|
机器学习/深度学习
自然语言处理
算法
【论文精读】TNNLS 2022 - 基于深度学习的事件抽取研究综述
事件抽取是从海量文本数据中快速获取事件信息的一项重要研究任务。随着深度学习的快速发展,基于深度学习技术的事件抽取已成为研究热点。文献中提出了许多方法、数据集和评估指标,这增加全面更新调研的需求。
377
0
1
|
6月前
|
Android开发
iOS开发
Windows
|
6月前
|
6月前
|
Android开发
热门文章
最新文章
1
MISRA C++ 、Google C++ 、AUTOSAR Adaptive Platform编码 C++ 规范总结
2
探索基于深度学习的图像识别在自动驾驶中的应用
3
【动手学深度学习】深入浅出深度学习之线性神经网络
4
揭秘深度学习在图像识别中的创新应用
5
Anaconda+Cuda+Cudnn+Pytorch(GPU版)+Pycharm+Win11深度学习环境配置
6
基于深度学习的图像识别技术在自动驾驶汽车中的应用
7
深度学习框架-Tensorflow2:特点、架构、应用和未来发展趋势
8
从零构建现代深度学习框架(TinyDL-0.01)
9
利用深度学习进行自然语言处理的最新进展
10
深度学习框架-Pytorch:特点、架构、应用和未来发展趋势
1
深度学习赋能智能监控:图像识别技术的革新与应用
6
2
深度学习在图像识别中的应用与挑战
12
3
智能监控的革新者:基于深度学习的图像识别技术
6
4
深度学习在智能监控领域的革新:图像识别技术的崛起
7
5
MATLAB用深度学习长短期记忆 (LSTM) 神经网络对智能手机传感器时间序列数据进行分类
15
6
基于深度学习的图像识别技术在自动驾驶系统中的应用
13
7
深度学习在图像识别中的应用与挑战
14
8
基于深度学习的图像识别技术在自动驾驶系统中的应用研究
10
9
从零构建现代深度学习框架(TinyDL-0.01)
42
10
深度学习驱动下的智能监控革新:图像识别技术的前沿应用
7