本节书摘来自华章出版社《面向机器智能的TensorFlow实践》一书中的第3章,第3.2节,作者 山姆·亚伯拉罕(Sam Abrahams)丹尼亚尔·哈夫纳(Danijar Hafner)[美] 埃里克·厄威特(Erik Erwitt)阿里尔·斯卡尔皮内里(Ariel Scarpinelli),更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.2 在TensorFlow中定义数据流图
在本书中,你将接触到多样化的以及相当复杂的机器学习模型。然而,不同的模型在TensorFlow中的定义过程却遵循着相似的模式。当掌握了各种数学概念,并学会如何实现它们时,对TensorFlow核心工作模式的理解将有助于你脚踏实地开展工作。幸运的是,这个工作流非常容易记忆,它只包含两个步骤:
1)定义数据流图。
2)运行数据流图(在数据上)。
这里有一个显而易见的道理,如果数据流图不存在,那么肯定无法运行它。头脑中有这种概念是很有必要的,因为当你编写代码时会发现TensorFlow功能是如此丰富。每次只需关注上述工作流的一部分,有助于更周密地组织自己的代码,并有助于明确接下来的工作方向。
本节将专注于讲述在TensorFlow中定义数据流图的基础知识,下一节将介绍当数据流图创建完毕后如何运行。最后,我们会将这两个步骤进行衔接,并展示如何创建在多次运行中状态不断发生变化并接收不同数据的数据流图。
3.2.1 构建第一个TensorFlow数据流图
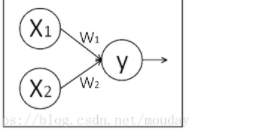
通过上一节的介绍,我们已对如下数据流图颇为熟悉。
用于表示该数据流图的TensorFlow代码如下所示:
下面来逐行解析这段代码。首先,你会注意到下列导入语句:
毫不意外,这条语句的作用是导入TensorFlow库,并赋予它一个别名—tf。按照惯例,人们通常都是以这种形式导入TensorFlow的,因为在使用该库中的各种函数时,键入“tf”要比键入完整的“tensorflow”容易得多。
接下来研究前两行变量赋值语句:
这里定义了“input”节点a和b。语句第一次引用了TensorFlow Operation:tf.constant()。在TensorFlow中,数据流图中的每个节点都被称为一个Operation(简记为Op)。各Op可接收0个或多个Tensor对象作为输入,并输出0个或多个Tensor对象。要创建一个Op,可调用与其关联的Python构造方法,在本例中,tf.constant()创建了一个“常量”Op,它接收单个张量值,然后将同样的值输出给与其直接连接的节点。为方便起见,该函数自动将标量值6和3转换为Tensor对象。此外,我们还为这个构造方法传入了一个可选的字符串参数name,用于对所创建的节点进行标识。
如果暂时还无法充分理解什么是Operation,什么是Tensor对象,请不必担心,本章稍后还会对这些概念进行详细介绍。
这两个语句定义了数据流图中的另外两个节点,而且它们都使用了之前定义的节点a和b。节点c使用了tf.mul Op,它接收两个输入,然后将它们的乘积输出。类似地,节点d使用了tf.add,该Op可将它的两个输入之和输出。对于这些Op,我们均传入了name参数(今后还将有大量此类用法)。请注意,无需专门对数据流图中的边进行定义,因为在Tensorflow中创建节点时已包含了相应的Op完成计算所需的全部输入,TensorFlow会自动绘制必要的连接。
最后的这行代码定义了数据流图的终点e,它使用tf.add的方式与节点d是一致的。区别只在于它的输入来自节点c和节点d,这与数据流图中的描述完全一致。
通过上述代码,便完成了第一个小规模数据流图的完整定义。如果在一个Python脚本或shell中执行上述代码,它虽然可以运行,但实际上却不会有任何实质性的结果输出。请注意,这只是整个流程的数据流图定义部分,要想体验一个数据流图的运行效果,还需在上述代码之后添加两行语句,以将数据流图终点的结果输出。
如果在某个交互环境中运行这些代码,如Python shell或Jupyter/iPython Notebook,则可看到正确的输出:
下面通过一个练习来实践上述内容。
练习:在TensorFlow中构建一个基本的数据流图
动手实践的时间已到!在这个练习中,你将编码实现第一个TensorFlow数据流图,运行它的各个部件,并初步了解极为有用的工具—TensorBoard。完成该练习后,你将能够非常自如地构建基本的TensorFlow数据流图。
下面让我们在TensorFlow中实际定义一个数据流图吧!请确保已成功安装TensorFlow,并启动Python依赖环境(如果使用的话),如Virtualenv、Conda、Docker等。此外,如果是从源码安装TensorFlow,请确保控制台的当前工作路径不同于TensorFlow的源文件夹,否则在导入该库时,Python将会无所适从。现在,启动一个交互式Python会话(既可通过shell命令jupyter notebook使用Jupyter Notebook,也可通过命令python启动简易的Python shell)。如果有其他偏好的方式交互式地编写Python代码,也可放心地使用!
可将代码写入一个Python文件,然后以非交互方式运行,但运行数据流图所产生的输出在默认情况下是不会显示出来的。为了使所定义的数据流图的运行结果可见,同时获得Python解释器对输入的句法的即时反馈(如果使用的是Jupyter Notebook),并能够在线修正错误和修改代码,强烈建议在交互式环境中完成这些例子。此外,你还会发现使用交互式TensorFlow乐趣无穷!
首先需要加载TensorFlow库。可按照下列方式编写导入语句:
导入过程需要持续几秒钟,待导入完成后,交互式环境便会等待下一行代码的到来。如果安装了有GPU支持的TensorFlow,你可能还会看到一些输出信息,提示CUDA库已被导入。如果得到一条类似下面的错误提示:
请确保交互环境不是从TensorFlow的源文件夹启动的。而如果得到一条类似下面的错误提示:
请复查TensorFlow是否被正确安装。如果使用的是Virtualenv或Conda,请确保启动交互式Python软件时,TensorFlow环境处于活动状态。请注意,如果运行了多个终端,则将只有一个终端拥有活动状态的TensorFlow环境。
假设上述导入语句在执行时没有遇到任何问题,则可进入下一部分代码:
这与在上面看到的代码完全相同,可随意更改这些常量的数值或name参数。在本书中,为了保持前后一致性,笔者会始终使用相同的数值。
这样,代码中便有了两个实际执行某个数学函数的Op。如果对使用tf.mul和tf.add感到厌倦,不妨将其替换为tf.sub、tf.div或tf.mod,这些函数分别执行的是减法、除法和取模运算。
[tf.div](https://www.tensorflow.org/versions/master/api_docs/python/math_ops.html#div)或者执行整数除法,或执行浮点数除法,具体取决于所提供的输入类型。如果希望确保使用浮点数除法,请使用tf.truediv。
接下来定义数据流图的终点:
你可能已经注意到,在调用上述Op时,没有显示任何输出,这是因为这些语句只是在后台将一些Op添加到数据流图中,并无任何计算发生。为运行该数据流图,需要创建一个TensorFlow Session对象:
Session对象在运行时负责对数据流图进行监督,并且是运行数据流图的主要接口。在本练习之后,我们还将对Session对象进行更为深入的探讨,但现在只需了解在TensorFlow中,如果希望运行自己的代码,必须定义一个Session对象。上述代码将Session对象赋给了变量sess,以便后期能够对其进行访问。
关于InteractiveSession
tf.Session有一个与之十分相近的变体—tf.InteractiveSession。它是专为交互式Python软件设计的(例如那些可能正在使用的环境),而且它采取了一些方法使运行代码的过程更加简便。不利的方面是在Python文件中编写TensorFlow代码时用处不大,而且它会将一些作为TensorFlow新手应当了解的信息进行抽象。此外,它不能省去很多的按键次数。本书将始终使用标准的tf.Session类。
至此,我们终于可以看到运行结果了。执行完上述语句后,你应当能够看到所定义的数据流图的输出。对于本练习中的数据流图,输出为23。如果使用了不同的函数和输入,则最终结果也可能不同。然而,这并非我们能做的全部,还可尝试着将数据流图中的其他节点传入sess.run()函数,如:
通过这个调用,应该能够看到中间节点c的输出(在本例中为15)。TensorFlow不会对你所创建的数据流图做任何假设,程序并不会关心节点c是否是你希望得到的输出!实际上,可对数据流图中的任意Op使用run()函数。当将某个Op传入sess.run()时,本质上是在通知TensorFlow“这里有一个节点,我希望得到它的输出,请执行所有必要的运算来求取这个节点的输出”。可反复尝试该函数的使用,将数据流图中其他节点的结果输出。
还可将运行数据流图所得到的结果保存下来。下面将节点e的输出保存到一个名为output的Python变量中:
棒极了!既然我们已经拥有了一个活动状态的Session对象,且数据流图已定义完毕,下面来对它进行可视化,以确认其结构与之前所绘制的数据流图完全一致。为此可使用TensorBoard,它是随TensorFlow一起安装的。为利用TensorBoard,需要在代码中添加下列语句:
下面分析这行代码的作用。我们创建了一个TensorFlow的SummaryWriter对象,并将它赋给变量writer。虽然在本练习中不准备用SummaryWriter对象完成其他操作,但今后会利用它保存来自数据流图的数据和概括统计量,因此我们习惯于将它赋给一个变量。为对SummaryWriter对象进行初始化,我们传入了两个参数。第一个参数是一个字符串输出目录,即数据流图的描述在磁盘中的存放路径。在本例中,所创建的文件将被存放在一个名为my_graph的文件夹中,而该文件夹位于运行Python代码的那个路径下。我们传递给SummaryWriter构造方法的第二个输入是Session对象的graph属性。作为在TensorFlow中定义的数据流图管理器,tf.Session对象拥有一个graph属性,该属性引用了它们所要追踪的数据流图。通过将该属性传入SummaryWriter构造方法,所构造的SummarWriter对象便会将对该数据流图的描述输出到“my_graph”路径下。SummaryWriter对象初始化完成之后便会立即写入这些数据,因此一旦执行完这行代码,便可启动TensorBoard。
回到终端,并键入下列命令,确保当前工作路径与运行Python代码的路径一致(应该能看到列出的“my_graph”路径):
从控制台中,应该能够看到一些日志信息打印出来,然后是消息“Starting Tensor-Board on port 6066”。刚才所做的是启动一个使用来自“my_graph”目录下的数据的TensorBoard服务器。默认情况下,TensorBoard服务器启动后会自动监听端口6006—要访问TensorBoard,可打开浏览器并在地址栏输入http://localhost:6006,然后将看到一个橙白主题的欢迎页面:
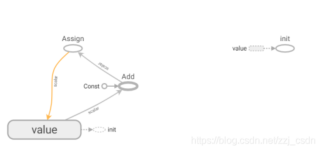
请不要为警告消息“No scalar data was found”紧张,这仅仅表示我们尚未为Tensor-Board保存任何概括统计量,从而使其无法正常显示。通常,这个页面会显示利用SummaryWriter对象要求TensorFlow所保存的信息。由于尚未保存任何其他统计量,所以无内容可供显示。尽管如此,这并不妨碍我们欣赏自己定义的美丽的数据流图。单击页面顶部的“Graph”链接,将看到类似下图的页面:
这才说得过去!如果数据流图过小,则可通过在TensorBoard上向上滚动鼠标滚轮将其放大。可以看到,图中的每个节点都用传给每个Op的name参数进行了标识。如果单击这些节点,还会得到一些关于它们的信息,如它们依赖于哪些节点。还会发现,输入节点a和b貌似重复出现了,但如果单击或将鼠标悬停在标签为“input_a”的任何一个节点,会发现两个节点同时高亮。这里的数据流图在外观上与之前所绘制的并不完全相同,但它们本质上是一样的,因为“input”节点不过是显示了两次而已,效果还是相当惊艳的!
就是这样!现在已经正式地编写并运行了第一个TensorFlow数据流图,而且还在TensorBoard中对其进行了检查!只用这样少的几行代码就完成如此多的任务真是棒极了!
要想更多地实践,可尝试在数据流图中添加更多节点,并试验一些之前介绍过的不同数学运算,然后添加少量tf.constant节点,运行所添加的不同节点,确保真正理解了数据在数据流图中的流动方式。
完成数据流图的构造之后,需要将Session对象和SummarWriter对象关闭,以释放资源并执行一些清理工作:
从技术角度讲,当程序运行结束后(若使用的是交互式环境,当关闭或重启Python内核时),Session对象会自动关闭。尽管如此,笔者仍然建议显式关闭Session对象,以避免任何诡异的边界用例的出现。
下面给出本练习对应的完整Python代码:
3.2.2 张量思维
在学习数据流图的基础知识时,使用简单的标量值是很好的选择。既然我们已经掌握了“数据流”,下面不妨熟悉一下张量的概念。
如前所述,所谓张量,即n维矩阵的抽象。因此,1D张量等价于向量,2D张量等价于矩阵,对于更高维数的张量,可称“N维张量”或“N阶张量”。有了这一概念,便可对之前的示例数据流图进行修改,使其可使用张量。
现在不再使用两个独立的输入节点,而是换成了一个可接收向量(或1阶张量)的节点。与之前的版本相比,这个新的流图有如下优点:
1)客户只需将输入送给单个节点,简化了流图的使用。
2)那些直接依赖于输入的节点现在只需追踪一个依赖节点,而非两个。
3)这个版本的流图可接收任意长度的向量,从而使其灵活性大大增强。我们还可对这个流图施加一条严格的约束,如要求输入的长度必须为2(或任何我们希望的长度)。
按下列方式修改之前的代码,便可在TensorFlow中实现这种变动:
除了调整变量名称外,主要改动还有以下两处:
1)将原先分离的节点a和b替换为一个统一的输入节点(不止包含之前的节点a)。传入一组数值后,它们会由tf.constant函数转化为一个1阶张量。
2)之前只能接收标量值的乘法和加法Op,现在用tf.reduce_prod()和tf.reduce_sum()函数重新定义。当给定某个张量作为输入时,这些函数会接收其所有分量,然后分别将它们相乘或相加。
在TensorFlow中,所有在节点之间传递的数据都为Tensor对象。我们已经看到,TensorFlow Op可接收标准Python数据类型,如整数或字符串,并将它们自动转化为张量。手工创建Tensor对象有多种方式(即无需从外部数据源读取),下面对其中一部分进行介绍。
注意:本书在讨论代码时,会不加区分地使用“张量”或“Tensor对象”。
1. Python原生类型
TensorFlow可接收Python数值、布尔值、字符串或由它们构成的列表。单个数值将被转化为0阶张量(或标量),数值列表将被转化为1阶张量(向量),由列表构成的列表将被转化为2阶张量(矩阵),以此类推。下面给出一些例子。
TensorFlow数据类型
到目前为止,我们尚未见到布尔值或字符串,但可将张量视为一种以结构化格式保存任意数据的方式。显然,数学函数无法对字符串进行处理,而字符串解析函数也无法对数值型数据进行处理,但有必要了解TensorFlow所能处理的数据类型并不局限于数值型数据!下面给出TensorFlow中可用数据类型的完整清单。
数据类型(dtype) 描 述
tf.float32 32位浮点型
tf.float64 64位浮点型
tf.int8 8位有符号整数
tf.int16 16位有符号整数
tf.int32 32位有符号整数
tf.int64 64位有符号整数
tf.uint8 8位无符号整数
tf.string 字符串(作为非Unicode编码的字节数组)
tf.bool 布尔型
tf.complex64 复数,实部和虚部分别为32位浮点型
tf.qint8 8位有符号整数(用于量化Op)
tf.qint32 32位有符号整数(用于量化Op)
tf.quint8 8位无符号整数(用于量化Op)
利用Python类型指定Tensor对象既容易又快捷,且对为一些想法提供原型非常有用。然而,很不幸,这种方式也会带来无法忽视的不利方面。TensorFlow有数量极为庞大的数据类型可供使用,但基本的Python类型缺乏对你希望使用的数据类型的种类进行明确声明的能力。因此,TensorFlow不得不去推断你期望的是何种数据类型。对于某些类型,如字符串,推断过程是非常简单的,但对于其他类型,则可能完全无法做出推断。例如,在Python中,所有整数都具有相同的类型,但TensorFlow却有8位、16位、32位和64位整数类型之分。当将数据传入TensorFlow时,虽有一些方法可将数据转化为恰当的类型,但某些数据类型仍然可能难以正确地声明,例如复数类型。因此,更常见的做法是借助NumPy数组手工定义Tensor对象。
2. NumPy数组
TensorFlow与专为操作N维数组而设计的科学计算软件包NumPy是紧密集成在一起的。如果之前没有使用过NumPy,笔者强烈推荐你从大量可用的入门材料和文档中选择一些进行学习,因为它已成为数据科学的通用语言。TensorFlow的数据类型是基于NumPy的数据类型的。实际上,语句np.int32==tf.int32的结果为True。任何NumPy数组都可传递给TensorFlow Op,而且其美妙之处在于可以用最小的代价轻易地指定所需的数据类型。
字符串数据类型
对于字符串数据类型,有一个“特别之处”需要注意。对于数值类型和布尔类型,TenosrFlow和NumPy dtype属性是完全一致的。然而,在NumPy中并无与tf.string精确对应的类型,这是由NumPy处理字符串的方式决定的。也就是说,TensorFlow可以从NumPy中完美地导入字符串数组,只是不要在NumPy中显式指定dtype属性。
有一个好处是,在运行数据流图之前或之后,都可以利用NumPy库的功能,因为从Session.run方法所返回的张量均为NumPy数组。下面模仿之前的例子,给出一段用于演示创建NumPy数组的示例代码:
虽然TensorFlow是为理解NumPy原生数据类型而设计的,但反之不然。请不要尝试用tf.int32去初始化一个NumPy数组!
手工指定Tensor对象时,使用NumPy是推荐的方式。
3.2.3 张量的形状
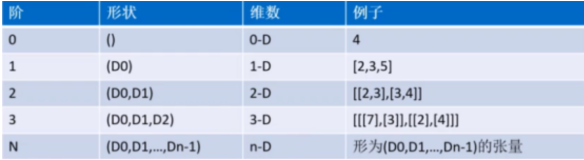
在整个TensorFlow库中,会经常看到一些引用了某个张量对象的“shape”属性的函数和Op。这里的“形状”是TensorFlow的专有术语,它同时刻画了张量的维(阶)数以及每一维的长度。张量的形状可以是包含有序整数集的列表(list)或元组(tuple):列表中元素的数量与维数一致,且每个元素描述了相应维度上的长度。例如,列表[2, 3]描述了一个2阶张量的形状,其第1个维上的长度为2,第2个维上的长度为3。注意,无论元组(用一对小括号包裹),还是列表(用一对方括号包裹),都可用于定义张量的形状。下面通过更多的例子来说明这一点:
除了能够将张量的每一维指定为固定长度,也可将None作为某一维的值,使该张量具有可变长度。此外,将形状指定为None(而非使用包含None的列表或元组)将通知TensorFlow允许一个张量为任意形状,即张量可拥有任意维数,且每一维都可具有任意长度。
如果需要在数据流图的中间获取某个张量的形状,可以使用tf.shape Op。它的输入为希望获取其形状的Tensor对象,输出为一个int32类型的向量:
请记住,与其他Op一样,tf.shape只能通过Session对象得到执行。
再次提醒:张量只是矩阵的一个超集!
3.2.4 TensorFlow的Operation
上文曾经介绍过,TensorFlow Operation也称Op,是一些对(或利用)Tensor对象执行运算的节点。计算完毕后,它们会返回0个或多个张量,可在以后为数据流图中的其他Op所使用。为创建Op,需要在Python中调用其构造方法。调用时,需要传入计算所需的所有Tensor参数(称为输入)以及为正确创建Op的任何附加信息(称为属性)。Python构造方法将返回一个指向所创建Op的输出(0个或多个Tensor对象)的句柄。能够传递给其他Op或Session.run的输出如下:
无输入、无输出的运算
是的,这意味着从技术角度讲,有些 Op既无任何输入,也无任何输出。Op的功能并不只限于数据运算,它还可用于如状态初始化这样的任务。本章中,我们将回顾一些这样的非数学Op,但请记住,并非所有节点都需要与其他节点连接。
除了输入和属性外,每个Op构造方法都可接收一个字符串参数—name,作为其输入。在上面的练习中我们已经了解到,通过提供name参数,可用描述性字符串来指代某个特定Op:
在这个例子中,我们为加法Op赋予了名称“my_add_op”,这样便可在使用如Tensor-Board等工具时引用该Op。
如果希望在一个数据流图中对不同Op复用相同的name参数,则无需为每个name参数手工添加前缀或后缀,只需利用name_scope以编程的方式将这些运算组织在一起便可。在本章最后的练习中,将简要介绍名称作用域(name scope)的基础知识。
运算符重载
TensorFlow还对常见数学运算符进行了重载,以使乘法、加法、减法及其他常见运算更加简洁。如果运算符有一个或多个参数(操作对象)为Tensor对象,则会有一个TensorFlow Op被调用,并被添加到数据流图中。例如,可按照下列方式轻松地实现两个张量的加法:
# 假设a和b均为Tensor对象,且形状匹配
下面给出可用于张量的重载运算符的完整清单。
一元运算符
运算符 相关TensorFlow运算 描 述
-x tf.neg() 返回x中每个元素的相反数
~x tf.logical_not() 返回x中每个元素的逻辑非。只适用于dtype为tf.bool的Tensor对象
abs(x) tf.abs() 返回x中每个元素的绝对值
二元运算符
运算符 相关TensorFlow运算 描 述
x+y tf.add() 将x和y逐元素相加
x-y tf.sub() 将x和y逐元素相减
x*y tf.mul() 将x和y逐元素相乘
x/y (Python 2.x) tf.div() 给定整数张量时,执行逐元素的整数除法;给定浮点型张量时,将执行浮点数(“真正的”)除法
x/y (Python 3.x) tf.truediv() 逐元素的浮点数除法(包括分子分母为整数的情形)
x//y (Python 3.x) tf.floordiv() 逐元素的向下取整除法,不返回余数
x%y tf.mod() 逐元素取模
x**y tf.pow() 逐一计算x中的每个元素为底数,y中相应元素为指数时的幂
x<y tf.less() 逐元素地计算x<y的真值表
x<=y tf.less_equal() 逐元素地计算x≤y的真值表
x>y tf.greater() 逐元素地计算x>y的真值表
x>=y tf.greater_equal() 逐元素地计算x≥y的真值表
x&y tf.logical_and() 逐元素地计算x & y的真值表,每个元素的dtype属性必须为tf.bool
x|y tf.logical_or() 逐元素地计算x|y的真值表,每个元素的dtype属性必须为tf.bool
x^y tf.logical_xor() 逐元素地计算x^y的真值表,每个元素的dtype属性必须为tf.bool
利用这些重载运算符可快速地对代码进行整合,但却无法为这些Op指定name值。如果需要为Op指定name值,请直接调用TensorFlow Op。
从技术角度讲,==运算符也被重载了,但它不会返回一个布尔型的Tensor对象。它所判断的是两个Tensor对象名是否引用了同一个对象,若是,则返回True,否则,返回False。这个功能主要是在TensorFlow内部使用。如果希望检查张量值是否相同,请使用tf.equal()和tf.not_equal()。
3.2.5 TensorFlow的Graph对象
到目前为止,我们对数据流图的了解仅限于在TensorFlow中无处不在的某种抽象概念,而且对于开始编码时Op如何自动依附于某个数据流图并不清楚。既然已经接触了一些例子,下面来研究TensorFlow的Graph对象,学习如何创建更多的数据流图,以及如何让多个流图协同工作。
创建Graph对象的方法非常简单,它的构造方法不需要接收任何参数:
Graph对象初始化完成后,便可利用Graph.as_default()方法访问其上下文管理器,为其添加Op。结合with语句,可利用上下文管理器通知TensorFlow我们需要将一些Op添加到某个特定Graph对象中:
你可能会好奇,为什么在上面的例子中不需要指定我们希望将Op添加到哪个Graph对象?原因是这样的:为方便起见,当TensorFlow库被加载时,它会自动创建一个Graph对象,并将其作为默认的数据流图。因此,在Graph.as_default()上下文管理器之外定义的任何Op、Tensor对象都会自动放置在默认的数据流图中:
如果希望获得默认数据流图的句柄,可使用tf.get_default_graph()函数:
在大多数TensorFlow程序中,只使用默认数据流图就足够了。然而,如果需要定义多个相互之间不存在依赖关系的模型,则创建多个Graph对象十分有用。当需要在单个文件中定义多个数据流图时,最佳实践是不使用默认数据流图,或为其立即分配句柄。这样可以保证各节点按照一致的方式添加到每个数据流图中。
1.正确的实践—创建新的数据流图,将默认数据流图忽略
2.正确的实践—获取默认数据流图的句柄
3.错误的实践—将默认数据流图和用户创建的数据流图混合使用
此外,从其他TensorFlow脚本中加载之前定义的模型,并利用Graph.as_graph_def()和tf.import_graph_def()函数将其赋给Graph对象也是可行的。这样,用户便可在同一个Python文件中计算和使用若干独立的模型的输出。本书后续章节将介绍数据流图的导入和导出。
3.2.6 TensorFlow Session
在之前的练习中,我们曾经介绍过,Session类负责数据流图的执行。构造方法tf.Session()接收3个可选参数:
target指定了所要使用的执行引擎。对于大多数应用,该参数取为默认的空字符串。在分布式设置中使用Session对象时,该参数用于连接不同的tf.train.Server实例(本书后续章节将对此进行介绍)。
graph参数指定了将要在Session对象中加载的Graph对象,其默认值为None,表示将使用当前默认数据流图。当使用多个数据流图时,最好的方式是显式传入你希望运行的Graph对象(而非在一个with语句块内创建Session对象)。
config参数允许用户指定配置Session对象所需的选项,如限制CPU或GPU的使用数目,为数据流图设置优化参数及日志选项等。
在典型的TensorFlow程序中,创建Session对象时无需改变任何默认构造参数。
请注意,下列两种调用方式是等价的:
一旦创建完Session对象,便可利用其主要的方法run()来计算所期望的Tensor对象的输出:
Session.run()方法接收一个参数fetches,以及其他三个可选参数:feed_dict、options和run_metadata。本书不打算对options和run_metadata进行介绍,因为它们尚处在实验阶段(因此以后很可能会有变动),且目前用途非常有限,但理解feed_dict非常重要,下文将对其进行讲解。
1. fetches参数
fetches参数接收任意的数据流图元素(Op或Tensor对象),后者指定了用户希望执行的对象。如果请求对象为Tensor对象,则run()的输出将为一NumPy数组;如果请求对象为一个Op,则输出将为None。
在上面的例子中,我们将fetches参数取为张量b(tf.mul Op的输出)。TensorFlow便会得到通知,Session对象应当找到为计算b的值所需的全部节点,顺序执行这些节点,然后将b的值输出。我们还可传入一个数据流图元素的列表:
当fetches为一个列表时,run()的输出将为一个与所请求的元素对应的值的列表。在本例中,请求计算a和b的值,并保持这种次序。由于a和b均为张量,因此会接收到作为输出的它们的值。
除了利用fetches获取Tensor对象输出外,还将看到这样的例子:有时也会赋予fetches一个指向某个Op的句柄,这是在运行中的一种有价值的用法。tf.initialize_all_variables()便是一个这样的例子,它会准备将要使用的所有TensorFlow Variable对象(本章稍后将介绍Variable对象)。我们仍然将该Op传给fetches参数,但Session.run()的结果将为None:
2. feed_dict参数
参数feed_dict用于覆盖数据流图中的Tensor对象值,它需要Python字典对象作为输入。字典中的“键”为指向应当被覆盖的Tensor对象的句柄,而字典的“值”可以是数字、字符串、列表或NumPy数组(之前介绍过)。这些“值”的类型必须与Tensor的“键”相同,或能够转换为相同的类型。下面通过一些代码来展示如何利用feed_dict重写之前的数据流图中a的值:
请注意,即便a的计算结果通常为7,我们传给feed_dict的字典也会将它替换为15。在相当多的场合中,feed_dict都极为有用。由于张量的值是预先提供的,数据流图不再需要对该张量的任何普通依赖节点进行计算。这意味着如果有一个规模较大的数据流图,并希望用一些虚构的值对某些部分进行测试,TensorFlow将不会在不必要的计算上浪费时间。对于指定输入值,feed_dict也十分有用,在稍后的占位符一节中我们将对此进行介绍。
Session对象使用完毕后,需要调用其close()方法,将那些不再需要的资源释放:
或者,也可以将Session对象作为上下文管理器加以使用,这样当代码离开其作用域后,该Session对象将自动关闭:
也可利用Session类的as_default()方法将Session对象作为上下文管理器加以使用。类似于Graph对象被某些Op隐式使用的方式,可将一个Session对象设置为可被某些函数自动使用。这些函数中最常见的有Operation.run()和Tensor.eval(),调用这些函数相当于将它们直接传入Session.run()函数。
关于InteractiveSession的进一步讨论
在本书之前的章节中,我们提到InteractiveSession是另外一种类型的TensorFlow会话,但我们不打算使用它。InteractiveSession对象所做的全部内容是在运行时将其作为默认会话,这在使用交互式Python shell的场合是非常方便的,因为可使用a.eval()或a.run(),而无须显式键入sess.run([a])。然而,如果需要同时使用多个会话,则事情会变得有些棘手。笔者发现,在运行数据流图时,如果能够保持一致的方式,将会使调试变得更容易,因此我们坚持使用常规的Session对象。
既然已对运行数据流图有了切实的理解,下面来探讨如何恰当地指定输入节点,并结合它们来使用feed_dict。
3.2.7 利用占位节点添加输入
之前定义的数据流图并未使用真正的“输入”,它总是使用相同的数值5和3。我们真正希望做的是从客户那里接收输入值,这样便可对数据流图中所描述的变换以各种不同类型的数值进行复用,借助“占位符”可达到这个目的。正如其名称所预示的那样,占位符的行为与Tensor对象一致,但在创建时无须为它们指定具体的数值。它们的作用是为运行时即将到来的某个Tensor对象预留位置,因此实际上变成了“输入”节点。利用tf.placeholder Op可创建占位符:
调用tf.placeholder()时,dtype参数是必须指定的,而shape参数可选:
dtype指定了将传给该占位符的值的数据类型。该参数是必须指定的,因为需要确保不出现类型不匹配的错误。
shape指定了所要传入的Tensor对象的形状。请参考前文中对Tensor形状的讨论。shape参数的默认值为None,表示可接收任意形状的Tensor对象。
与任何Op一样,也可在tf.placeholder中指定一个name标识符。
为了给占位符传入一个实际的值,需要使用Session.run()中的feed_dict参数。我们将指向占位符输出的句柄作为字典(在上述代码中,对应变量a)的“键”,而将希望传入的Tensor对象作为字典的“值”:
必须在feed_dict中为待计算的节点的每个依赖占位符包含一个键值对。在上面的代码中,需要计算d的输出,而它依赖于a的输出。如果还定义了一些d不依赖的其他占位符,则无需将它们包含在feed_dict中。
placeholder的值是无法计算的—如果试图将其传入Session.run(),将引发一个异常。
3.2.8 Variable对象
1.创建Variable对象
Tensor对象和Op对象都是不可变的(immutable),但机器学习任务的本质决定了需要一种机制保存随时间变化的值。借助TensorFlow中的Variable对象,便可达到这个目的。Variable对象包含了在对Session.run()多次调用中可持久化的可变张量值。Variable对象的创建可通过Variable类的构造方法tf.Variable()完成:
Variable对象可用于任何可能会使用Tensor对象的TensorFlow函数或Op中,其当前值将传给使用它的Op:
Variables对象的初值通常是全0、全1或用随机数填充的阶数较高的张量。为使创建具有这些常见类型初值的张量更加容易,TensorFlow提供了大量辅助Op,如tf.zeros()、tf.ones()、tf.random_normal()和tf.random_uniform(),每个Op都接收一个shape参数,以指定所创建的Tensor对象的形状:
除了tf.random_normal()外,经常还会看到人们使用tf.truncated_normal(),因为它不会创建任何偏离均值超过2倍标准差的值,从而可以防止有一个或两个元素与该张量中的其他元素显著不同的情况出现:
可像手工初始化张量那样将这些Op作为Variable对象的初值传入:
2. Variable对象的初始化
Variable对象与大多数其他TensorFlow对象在Graph中存在的方式都比较类似,但它们的状态实际上是由Session对象管理的。因此,为使用Variable对象,需要采取一些额外的步骤—必须在一个Session对象内对Variable对象进行初始化。这样会使Session对象开始追踪这个Variable对象的值的变化。Variable对象的初始化通常是通过将tf.initialize_all_variables() Op传给Session.run()完成的:
如果只需要对数据流图中定义的一个Variable对象子集初始化,可使用tf.initialize_variables()。该函数可接收一个要进行初始化的Variable对象列表:
3. Variable对象的修改
要修改Variable对象的值,可使用Variable.assign()方法。该方法的作用是为Variable对象赋予新值。请注意,Variable.assign()是一个Op,要使其生效必须在一个Session对象中运行:
对于Variable对象的简单自增和自减,TensorFlow提供了Variable.assign_add()方法和Variable.assign_sub()方法:
由于不同Session对象会各自独立地维护Variable对象的值,因此每个Session对象都拥有自己的、在Graph对象中定义的Variable对象的当前值:
如果希望将所有Variable对象的值重置为初始值,则只需再次调用tf.initialize_all_variables()(如果只希望对部分Variable对象重新初始化,可调用tf.initialize_variables()):
4. trainable参数
在本书的后续章节将介绍各种能够自动训练机器学习模型的Optimizer类,这意味着这些类将自动修改Variable对象的值,而无须显式做出请求。在大多数情况下,这与读者的期望一致,但如果要求Graph对象中的一些Variable对象只可手工修改,而不允许使用Optimizer类时,可在创建这些Variable对象时将其trainable参数设为False:
对于迭代计数器或其他任何不涉及机器学习模型计算的Variable对象,通常都需要这样设置。