本节书摘来自华章出版社《循序渐进学Spark》一书中的第3章,第3.4节,作者 小象学院 杨 磊,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.4 Spark通信机制
前面介绍过,Spark的部署模式可以分为local、standalone、Mesos、YARN等。
本节以Spark部署在standalone模式下为例,介绍Spark的通信机制(其他模式类似)。
3.4.1 分布式通信方式
先介绍分布式通信的几种基本方式。
1. RPC
远程过程调用协议(Remote Procedure Call Protocol,RPC)是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发分布式应用更加容易。RPC采用C/S架构。请求程序就是一个Client,而服务提供程序就是一个Server。首先,Client调用进程发送一个有进程参数的调用信息到Service进程,然后等待应答信息。在Server端,进程保持睡眠状态直到调用信息到达为止。当一个调用信息到达时,Server获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,Client调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
2. RMI
远程方法调用(Remote Method Invocation,RMI)是Java的一组拥护开发分布式应用程序的API。RMI使用Java语言接口定义了远程对象,它集合了Java序列化和Java远程方法协议(Java Remote Method Protocol)。简单地说,这样使原先的程序在同一操作系统的方法调用,变成了不同操作系统之间程序的方法调用。由于J2EE是分布式程序平台,它以RMI机制实现程序组件在不同操作系统之间的通信。比如,一个EJB可以通过RMI调用Web上另一台机器上的EJB远程方法。RMI可以被看作是RPC的Java版本,但是传统RPC并不能很好地应用于分布式对象系统。Java RMI 则支持存储于不同地址空间的程序级对象之间彼此进行通信,实现远程对象之间的无缝远程调用。
3. JMS
Java消息服务(Java Message Service,JMS)是一个与具体平台无关的API,用来访问消息收发。JMS 使用户能够通过消息收发服务(有时称为消息中介程序或路由器)从一个 JMS 客户机向另一个JMS客户机发送消息。消息是 JMS 中的一种类型对象,由两部分组成:报头和消息主体。报头由路由信息以及有关该消息的元数据组成。消息主体则携带着应用程序的数据或有效负载。JMS定义了5种消息正文格式,以及调用的消息类型,允许发送并接收以一些不同形式的数据,提供现有消息格式的一些级别的兼容性。
StreamMessage:Java原始值的数据流。
MapMessage:一套名称–值对。
TextMessage:一个字符串对象。
ObjectMessage:一个序列化的 Java对象。
BytesMessage:一个未解释字节的数据流。
4. EJB
JavaEE服务器端组件模型(Enterprise JavaBean,EJB)的设计目标是部署分布式应用程序。简单来说就是把已经编写好的程序打包放在服务器上执行。EJB定义了一个用于开发基于组件的企业多重应用程序的标准。EJB的核心是会话Bean(Session Bean)、实体Bean(Entity Bean)和消息驱动Bean(Message Driven Bean)。
5. Web Service
Web Service是一个平台独立的、低耦合的、自包含的、基于可编程的Web应用程序。可以使用开放的XML(标准通用标记语言下的一个子集)标准来描述、发布、发现、协调和配置这些应用程序,用于开发分布式的应用程序。Web Service技术能使得运行在不同机器上的不同应用无须借助第三方软硬件, 就可相互交换数据或集成。Web Service减少了应用接口的花费。Web Service为整个企业甚至多个组织之间的业务流程的集成提供了一个通用机制。
3.4.2 通信框架AKKA
AKKA是一个用Scala语言编写的库,用于简化编写容错的、高可伸缩性的Java和Scala的Actor模型应用。它分为开发库和运行环境,可以用于构建高并发、分布式、可容错、事件驱动的基于JVM的应用。AKKA使构建高并发的分布式应用变得更加容易。Akka已经被成功运用在众多行业的众多大企业,从投资业到商业银行、从零售业到社会媒体、仿真、游戏和赌博、汽车和交通系统、数据分析等。任何需要高吞吐率和低延迟的系统都是使用AKKA的候选,因此Spark选择AKKA通信框架来支持模块间的通信。
Actor模型常见于并发编程,它由Carl Hewitt于20世纪70年代早期提出,目的是解决分布式编程中的一系列问题。其特点如下:
1) 系统中的所有事物都可以扮演一个Actor。
2) Actor之间完全独立。
3) 在收到消息时Actor采取的所有动作都是并行的。
4) Actor有标识和对当前行为的描述。
Actor可以看作是一个个独立的实体,它们之间是毫无关联的。但是,它们可以通过消息来通信。当一个Actor收到其他Actor的信息后,它可以根据需要做出各种响应。消息的类型和内容都可以是任意的。这点与Web Service类似,只提供接口服务,不必了解内部实现。一个Actor在处理多个Actor的请求时,通常先建立一个消息队列,每次收到消息后,就放入队列。Actor每次也可以从队列中取出消息体来处理,而且这个过程是可循环的,这个特点让Actor可以时刻处理发送来的消息。
AKKA的优势如下:
1) 易于构建并行与分布式应用(simple concurrency & distribution):AKKA采用异步通信与分布式架构,并对上层进行抽象,如Actors、Futures、STM等。
2) 可靠性(resilient by design):系统具备自愈能力,在本地/远程都有监护。
3) 高性能(high performance):在单机中每秒可发送5000万个消息。内存占用小,1GB内存中可保存250万个actors。
4) 弹性,无中心(elastic — decentralized):自适应的负责均衡、路由、分区、配置。
5) 可扩展性(extensible):可以使用Akka扩展包进行扩展。
3.4.3 Client、Master 和 Worker之间的通信
Client、Master与Worker之间的交互代码实现位于如下路径:
(spark-root)/core/src/main/scala/org/apache/spark/deploy
主要涉及的类包括Client.scala、Master.scala和Worker.scala。这三大模块之间的通信框架如图3-9所示:
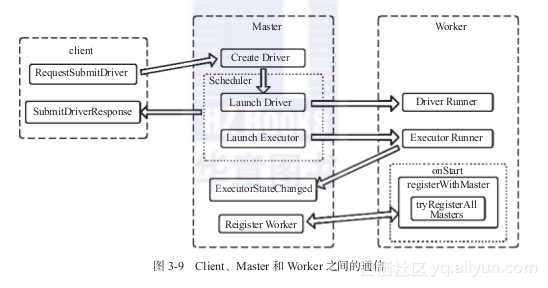
图3-9 Client、Master和Worker之间的通信
以Standalone部署模式为例,三大模块分工如下:
1)Client:提交作业给Master。
2)Master:接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
3)Worker:负责管理本节点的资源,定期向Master汇报心跳信息,接收Master的命令,如启动Driver和Executor。
下面列出Client、Master与Worker的实现代码,读者可以从中看到三个模块间的通信交互。
1. Client端通信
private class ClientEndpoint(
override val rpcEnv: RpcEnv,
driverArgs: ClientArguments,
masterEndpoints: Seq[RpcEndpointRef],
conf: SparkConf)
extends ThreadSafeRpcEndpoint with Logging {
<限于篇幅,此处代码省略……>
