本节书摘来自华章出版社《循序渐进学Spark》一书中的第3章,第3.3节,作者 小象学院 杨 磊,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.3 Spark存储与I/O
前面已经讲过,RDD是按照partition分区划分的,所以RDD可以看作由一些分布在不同节点上的分区组成。由于partition分区与数据块是一一对应的,所以RDD中保存了partitionID与物理数据块之间的映射。物理数据块并非都保存在磁盘上,也有可能保存在内存中。
3.3.1 Spark存储系统概览
Spark I/O机制可以分为两个层次:
1)通信层:用于Master与Slave之间传递控制指令、状态等信息,通信层在架构上也采用Master-Slave结构。
2)存储层:同于保存数据块到内存、磁盘,或远端复制数据块。
下面介绍几个Spark存储方面的功能模块。
1)BlockManager:Spark提供操作Storage的统一接口类。
2)BlockManagerMasterActor:Master创建,Slave利用该模块向Master传递信息。
3)BlockManagerSlaveActor:Slave创建,Master利用该模块向Slave节点传递控制命令,控制Slave节点对block的读写。
4)BlockManagerMaster: 管理Actor通信。
5)DiskStore:支持以文件方式读写的方式操作block。
6)MemoryStore: 支持内存中的block读写。
7)BlockManagerWorker: 对远端异步传输进行管理。
8)ConnectionManager:支持本地节点与远端节点数据block的传输。
图3-8概要性地揭示了Spark存储系统各个主要模块之间的通信。
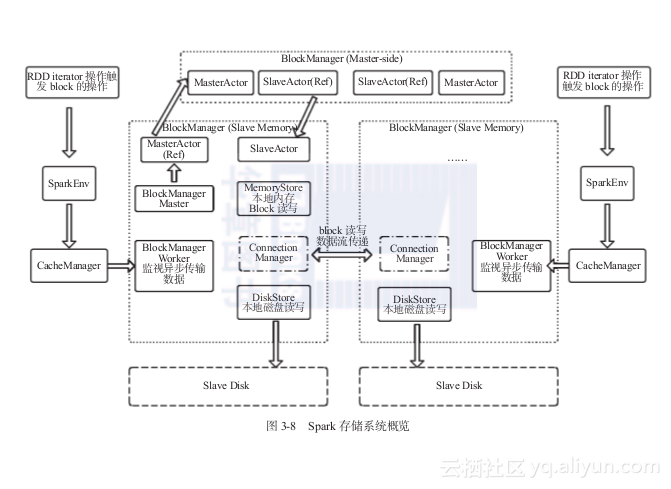
图3-8 Spark存储系统概览
3.3.2 BlockManager中的通信
存储系统的通信仍然类似Master-Slave架构,节点之间传递命令与状态。总体而言,Master向Slave传递命令,Slave向Master传递信息和状态。这些Master与Slave节点之间的信息传递通过Actor对象实现(关于Actor的详细功能会在下一节Spark通信机制中讲述)。但在BlockManager中略有不同,下面分别讲述。
1)Master节点上的BlockManagerMaster包含内容如下:
①BlockManagerMasterActor的Actor引用。
②BlockManagerSlaveActor的Ref引用。
2)Slave节点上的BlockManagerMaster包含内容如下:
①BlockManagerMasterActor的Ref引用。
②BlockManagerSlaveActor的Actor引用。
其中,在Ref与Actor之间的通信由BlockManagerMasterActor和BlockManagerSlave-Actor完成。这个部分相关的源码篇幅较多,此处省略,感兴趣的读者请自行研究。