2.3 Spark算子
本节介绍Spark算子的分类及其功能。
2.3.1 算子简介
Spark应用程序的本质,无非是把需要处理的数据转换为RDD,然后将RDD通过一系列变换(transformation)和操作(action)得到结果,简单来说,这些变换和操作即为算子。
Spark支持的主要算子如图2-4所示。

根据所处理的数据类型及处理阶段的不同,算子大致可以分为如下三类:
1) 处理Value数据类型的Transformation算子;这种变换并不触发提交作业,处理的数据项是Value型的数据。
2) 处理Key-Value数据类型的Transfromation算子;这种变换并不触发提交作业,处理的数据项是Key-Value型的数据对。
3) Action算子:这类算子触发SparkContext提交作业。
2.3.2 Value型Transmation算子
对于处理Value类型数据的Transformation算子,依据RDD的输入分区与输出分区的对应关系,可以将该类算子分为5类,如表2-1所示。
如表2-1所示,Value型的Transformation算子分类具体如下:
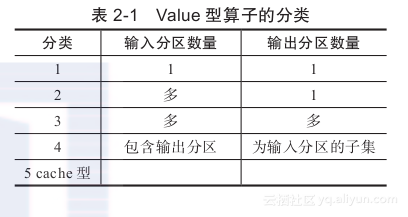
1) 输入分区与输出分区1对1型。
2) 输入分区与输出分区多对1型。
3) 输入分区与输出分区多对多型。
4) 输出分区为输入分区子集。
5) Cache型,对RDD的分区缓存。
下面详细介绍这五种分类。
1.输入分区与输出分区1对1型
1) map算子:map是对RDD中的每个元素都执行一个指定函数来产生一个新的RDD。任何原RDD中的元素在新RDD中都有且只有一个元素与之对应,如图2-5所示。
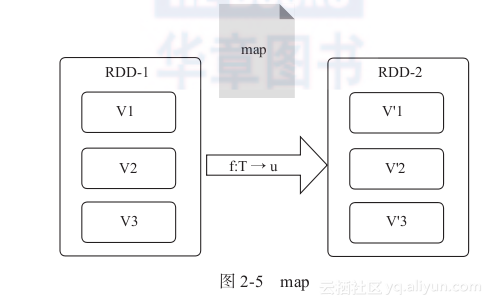
在图2-5中,RDD-1中的元素V1经过函数映射后,变为新的元素V'1,最终构成新的RDD-2。输入输出分区1对1型不会产生任何变化。注意,事实上,只有Action算子被触发后,这些操作才会被真正执行。
2) flatMap: 与map类似,将原RDD中的每个元素通过函数f转换为新的元素,并将这些元素放入一个集合,构成新的RDD,如图2-6所示。
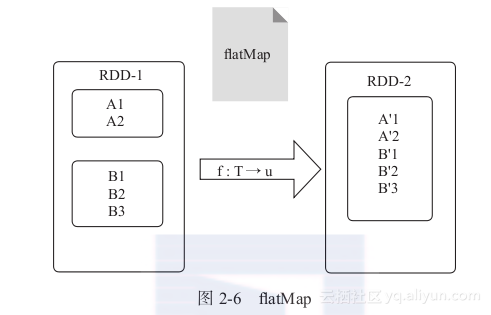
在图2-6中,外面大的矩形表示分区,小的矩形表示元素集合。如元素A1、A2在RDD-1中属于一个集合,B1、B2、B3属于另一个集合。RDD-1经过flatMap变换为新的RDD-2,此时A'与B'处于同一集合中。
3) mapPartitions:mapPartitions是map的一个变种。map的输入函数应用于RDD中的每个元素,而mapPartitions的输入函数应用于每个分区,也就是把每个分区中的内容作为整体来处理的。
mapPartitions的函数定义为:
def mapPartitions[U: ClassTag](f: Iterator[T] => Iterator[U], preservesPartitioning: Boolean = false): RDD[U]
f 即为输入函数,它处理每个分区中的内容。每个分区中的内容将以Iterator[T]传递给输入函数f,f的输出结果是Iterator[U]。最终的RDD由所有分区经过输入函数处理后的结果合并起来的,如图2-7所示。
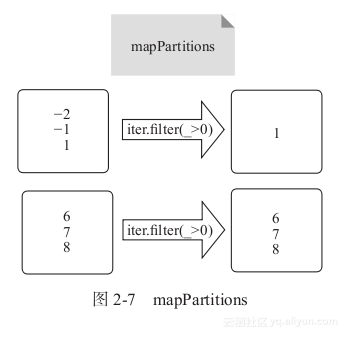
在图2-7中,用户通过f(iter)=>iter.filter(_>0)对元素过滤,保留大于0的元素。其中方框为分区,虽然过滤了元素,但原有分区保持不变。
4) glom:将每个分区内的元素组成一个数组,分区不变,如图2-8所示。
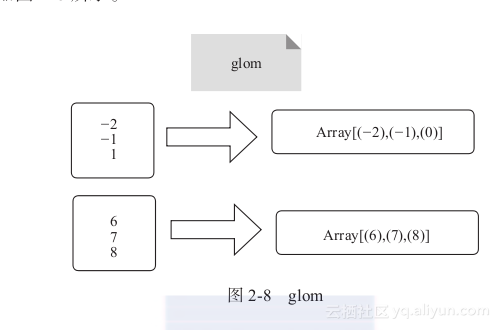
图2-8中的方框代表分区,glom算子将每个分区内的元素组成一个数组。
2.输入分区与输出分区多对1型
1) union:合并同一数据类型元素,但不去重。合并后返回同类型的数据元素,如图2-9所示。
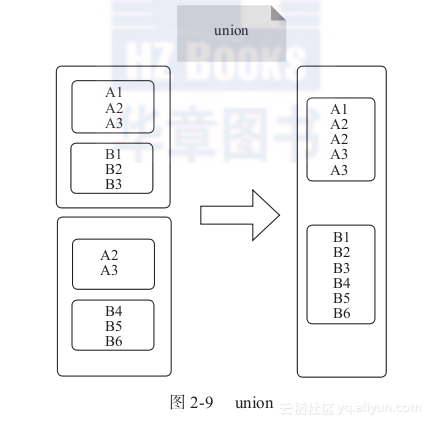
图2-9中的大方框代表RDD,内部小方框代表RDD分区,合并后同一类型元素位于同一分区中。
2) cartesian:对输入RDD内的所有元素计算笛卡尔积,如图2-10所示。
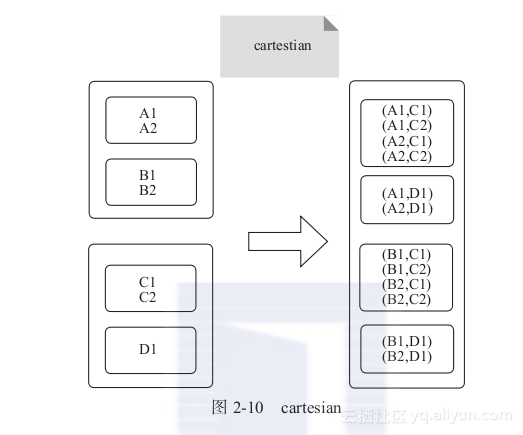
3.输入分区与输出分区多对多型
groupBy:先将元素通过函数生成Key,元素转为“Key-Value”类型之后,将Key相同的元素分为一组,如图2-11所示。
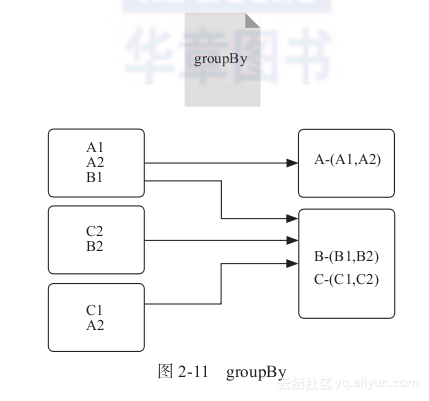
在图2-11中可以看到三个分区,经过groupBy变换后,Key相同的元素被合并到一组。
4.输出分区为输入分区子集
1) filter:对RDD中的元素进行过滤,过滤函数返回true的元素保留,否则删除,如图2-12所示。
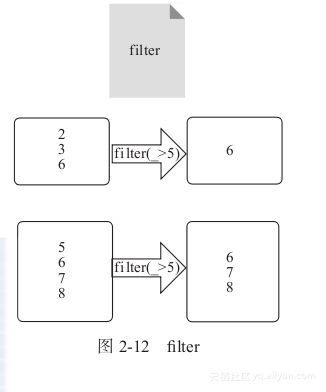 图2-12中的方框为RDD的分区。
图2-12中的方框为RDD的分区。
2) distinct:对RDD中的元素进行去重操作,重复的元素只保留一份。
3) substract:对集合进行差操作,即RDD1中去除RDD1与RDD2的交集。
4) sample: 对RDD集合内的元素采样。
5) takesample:与sample算子类似,可以设定采样个数。
5. Cache型(RDD持久化操作)
1) cache:将RDD元素从磁盘缓存到内存。
2) persist:与cache类似,但比cache功能更强大,persist函数可以指定存储级别。完整的存储级别列表如表2-2所示。
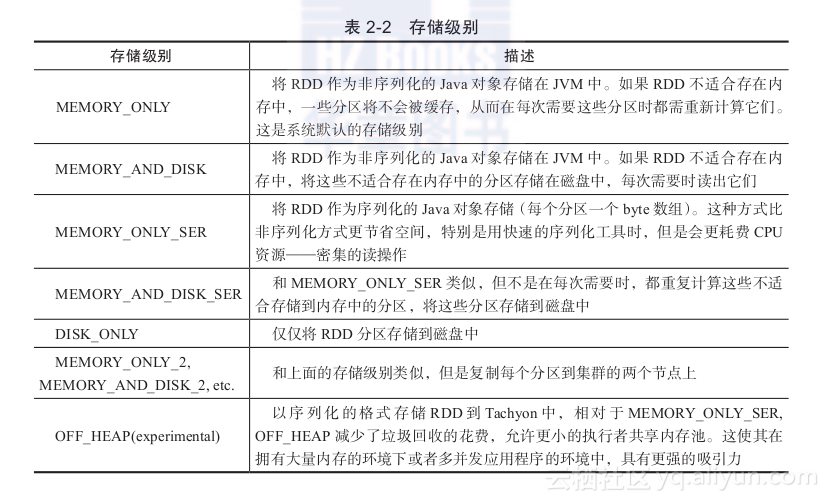
表2-2 存储级别
存储级别 描述
MEMORY_ONLY 将RDD作为非序列化的Java对象存储在JVM中。如果RDD不适合存在内存中,一些分区将不会被缓存,从而在每次需要这些分区时都需重新计算它们。这是系统默认的存储级别
MEMORY_AND_DISK 将RDD作为非序列化的Java对象存储在JVM中。如果RDD不适合存在内存中,将这些不适合存在内存中的分区存储在磁盘中,每次需要时读出它们
MEMORY_ONLY_SER 将RDD作为序列化的Java对象存储(每个分区一个byte数组)。这种方式比非序列化方式更节省空间,特别是用快速的序列化工具时,但是会更耗费CPU资源——密集的读操作
MEMORY_AND_DISK_SER 和MEMORY_ONLY_SER类似,但不是在每次需要时,都重复计算这些不适合存储到内存中的分区,将这些分区存储到磁盘中
DISK_ONLY 仅仅将RDD分区存储到磁盘中
MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. 和上面的存储级别类似,但是复制每个分区到集群的两个节点上
OFF_HEAP(experimental) 以序列化的格式存储RDD到Tachyon中,相对于MEMORY_ONLY_SER, OFF_HEAP减少了垃圾回收的花费,允许更小的执行者共享内存池。这使其在拥有大量内存的环境下或者多并发应用程序的环境中,具有更强的吸引力
2.3.3 Key-Value型Transmation算子
处理数据类型为Key-Value的Transmation算子,大致可以分为三类:
1.输入输出分区1对1
mapValues顾名思义就是输入函数应用于RDD中KV(Key-Value)类型元素中的Value,原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素。因此,该函数只适用于元素为Key-Value对的RDD,如图2-13所示。
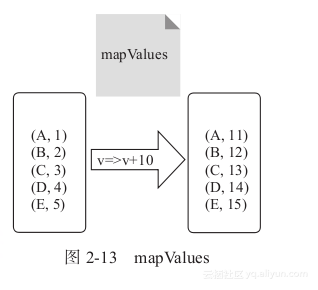
图2-13中的输入函数对Value分别进行加10操作,形成新的RDD,包含KV类型新元素。
2.聚集操作
(1) 对一个RDD聚集
1) reduceByKey:对元素为KV对的RDD中Key相同的元素的Value进行reduce操作,即两个值合并为一个值。因此,Key相同的多个元素的值被合并为一个值,然后与原RDD中的Key组成一个新的KV对,如图2-14所示。
2) combineByKey: 与reduceByKey类似,相当于将元素(int,int)KV对变换为(int,Seq[int])新的KV对,如图2-15所示。
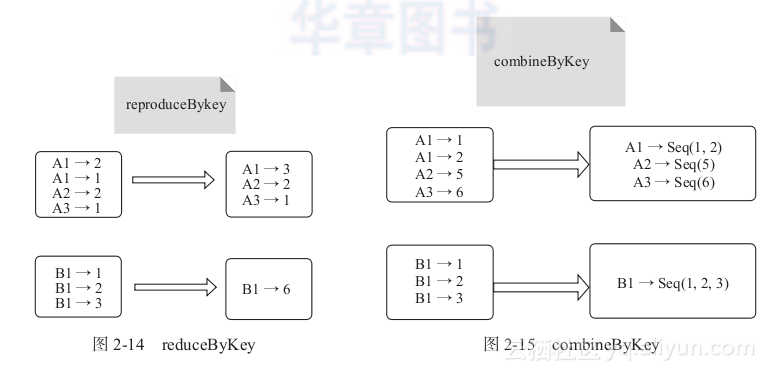
图2-14 reduceByKey 图2-15 combineByKey
3) partitionBy:根据KV对的Key对RDD进行分区,如图2-16所示。
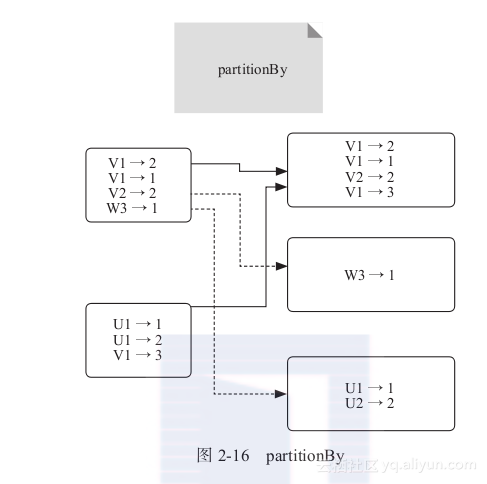
图2-16 partitionBy
(2) 对两个RDD聚集
coGroup:一组强大的函数,可以对多达3个RDD根据key进行分组,将每个Key相同的元素分别聚集为一个集合,如图2-17所示。
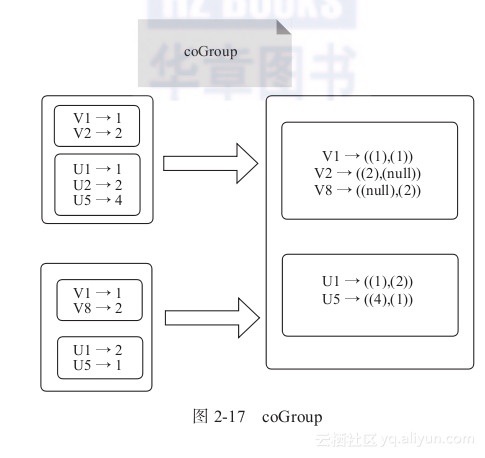
图2-17 coGroup
图2-17中的大方框为RDD,内部小方框为RDD中的分区。
3.连接
1) join:本质是对两个含有KV对元素的RDD进行coGroup算子协同划分,再通过flatMapValues将合并的数据分散。
2) leftOutJoin与rightOutJoin :相当于在join基础上判断一侧的RDD是否为空,如果为空,则填充空,如果有数据,则将数据进行连接计算,然后返回结果。
2.3.4 Action算子
Action算子可以依据其输出空间划分为:无输出、HDFS、Scala集合及数据类型。
1.无输出
foreach是对RDD中的每个元素执行无参数的f函数,返回Unit。定义如下:
def foreach(f: T => Unit)
foreach功能示例如图2-18所示。
图2-18中定义了println打印函数,打印RDD中的所有数据项。
2. HDFS
1) saveAsTextFile:函数将RDD保存为文本至HDFS指定目录,每次输出一行。功能示例如图2-19所示。
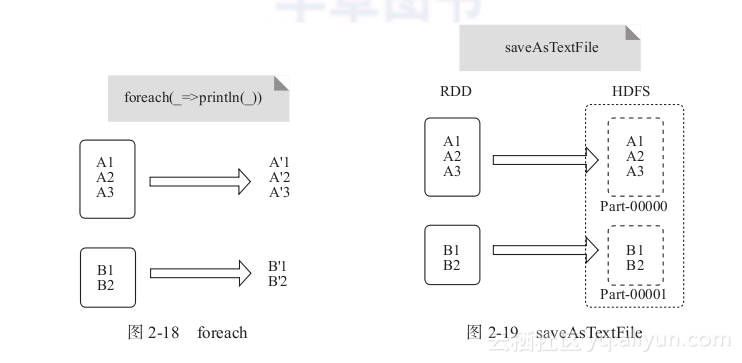
图2-18 foreach 图2-19 saveAsTextFile
在图2-19中,通过函数将RDD中的每个元素映射为(null,x.toString),然后写入HDFS 块。RDD的每个分区存储为HDFS中的数据块Block。
2) saveAsObjectFile:将RDD分区中每10个元素保存为一个数组并将其序列化,映射为(null,BytesWritable(Y))的元素,以SequenceFile的格式写入HDFS,如图2-20所示。
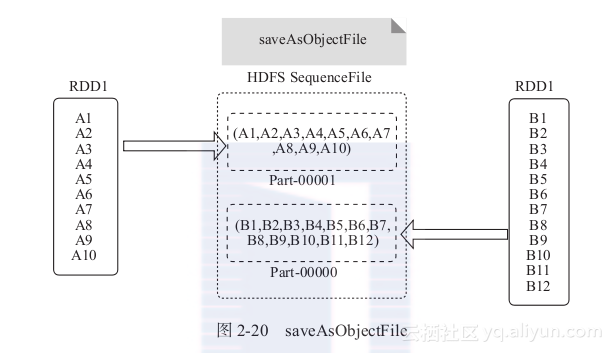
图2-20 saveAsObjectFile
3. Scala集合及数据类型
1) collect:将RDD分散存储的元素转换为单机上的Scala数组并返回,类似于toArray功能,如图2-21所示。
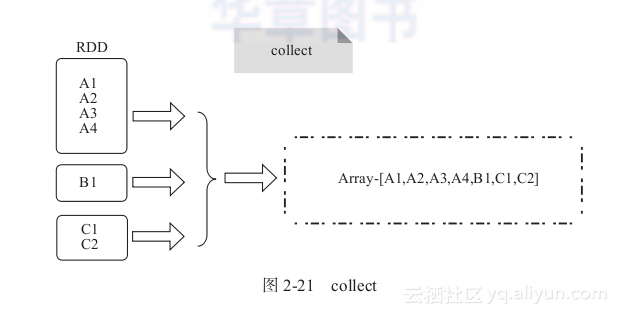
图2-21 collect
2) collectAsMap:与collect类似,将元素类型为key-value对的RDD,转换为Scala Map并返回,保存元素的KV结构。
3) lookup:扫描RDD的所有元素,选择与参数匹配的Key,并将其Value以Scala sequence的形式返回,如图2-22所示。
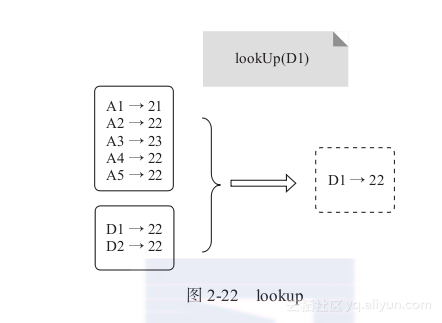
图2-22 lookup
4) reduceByKeyLocally:先reduce,然后collectAsMap。
5) count:返回RDD中的元素个数。
6) reduce:对RDD中的所有元素进行reduceLeft操作。
例如,当用户函数定义为:f:(A,B)=>(A._1+"@"+B._1,A._2+B._2)时,reduce算子的计算过程如图2-23所示。
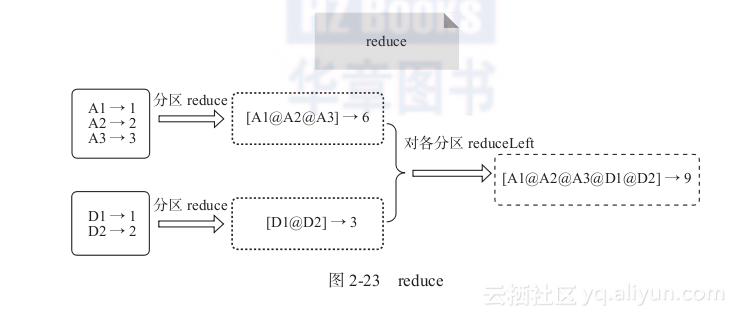
图2-23 reduce
7) top/take:返回RDD中最大/最小的K个元素。
8) fold:与reduce类似,不同的是每次对分区内的value聚集时,分区内初始化的值为zero value。
例如,当用户自定义函数为:fold(("A0",0))((A,B)=>A._1+"@"+B._1, A._2 + B._2 ))时,fold算子的计算过程如图2-24所示。
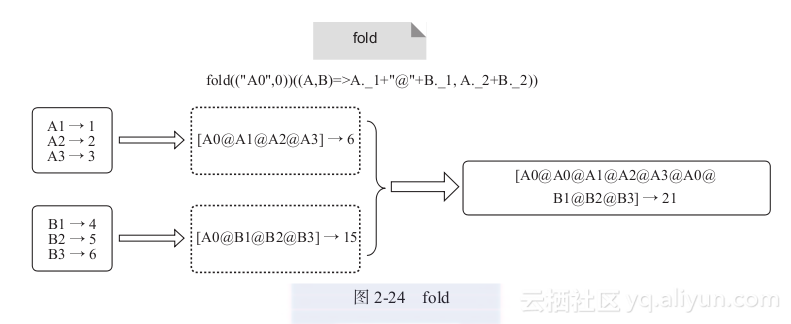
图2-24 fold
9) aggregate:允许用户对RDD使用两个不同的reduce函数,第一个reduce函数对各个分区内的数据聚集,每个分区得到一个结果。第二个reduce函数对每个分区的结果进行聚集,最终得到一个总的结果。aggregate相当于对RDD内的元素数据归并聚集,且这种聚集是可以并行的。而fold与reduced的聚集是串行的。
10) broadcast(广播变量):存储在单节点内存中,不需要跨节点存储。Spark运行时,将广播变量数据分发到各个节点,可以跨作业共享。
11) accucate:允许全局累加操作。accumulator被广泛用于记录应用运行参数。
