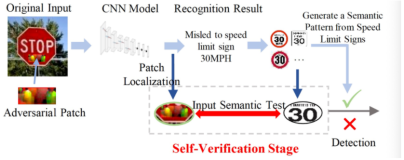
作为深入学习应用的一部分,语音识别和机器翻译领域已经产出了大量的工作,像我们所熟知的百度、Google和腾讯在这方面都有很多令人熟知的成果。虽然应用本身就是很有意思了,但更值得我们去研究的是当人们对于一些最难的机器学习问题有最新的思考时,研究人员是如何通过调整代码和系统来解决问题的。当我们想要去回溯语音识别和机器翻译的基础时,IBM给我们提供了部分最久远的历史,尽管可能这部分历史相对和深度学习相关性不是特别高。
IBM在语音和语言算法上的研究有36年的历史。IBM的Waston多模式部门高级经理Michael Picheny在很大程度上通过改变了代码和所需的系统推动了语音识别的发展。虽然像许多其他大规模机器学习玩家一样,IBM也大量部署了神经网络的GPU,但语音识别发展的道路同样还是漫长而复杂。先进的神经网络模型结合上能够实时和大规模运行的硬件,也就是这几件才出现的事。这个组合的出现致使IBM转向了语音算法的开发和部署。
Picheney回忆到,当年他加入IBM的时候,IBM是市面上唯一一家用统计和计算方法进行语音分析和识别的公司。其他公布都专注在语音潜在流程的物理建模上。“IBM是唯一一家用解决计算和数学技术来解决语音问题的公司,这是我见过的最简洁的方法。”Picheney早期在IBM的语音识别工作是在完全脱机的大型主机上完成的,后来他的工作被部署到了三个独立的IBM小型计算机并行工作以获得实时的性能。之后,在20世纪80年代初,IBM 的PC出现,实现了加速器的定制化。到了20世纪90年代,这项工作就可以完全在CPU上完成了。Picheny的语音识别团队现在则选用GPU来进行加速。即使目前来看,在硬件层面,这对于想要将采用深度学习方法来进行的语音识别提升到下一个水平是有限制的。
代码方面,IBM的语音识别领域也发生了很大变化。Picheny告诉我们最早的语言识别系统由四个部分构成,分别是一个特征提取器、一个声音模型、一个语言模型以及一个语言识别引擎。就像神经网络的进化历程一样,从内到外所有的系统构建都被融合成为一个整体,这个全局的模型需要惊人的计算资源和大规模的软硬件设施。而在这之前Picheny说为为不同的模型组件创造一个通用的高效架构十分困难,因为每一个组件都有自己的优化方法和特征需要单独考量。
“逐渐地我们看到,深度学习方法语音识别功能中占据越来越重要的地位。深度学习架构和机制在一点一滴取代过去那些难以处理大规模扩展的机制。在接下来的一些年里,我们将会看到深度学习架构将会用于所有的语音识别领域,对于图像也是同样的道理。”他还表示未来可能将很多的功能包集成到一颗芯片中去实现特殊的功能。
Picheny说,“深度学习领域的从业者对于自身学习的方向十分敏锐,这个领域的更新迭代实在太快了,新东西从这里从哪里连续不断的冒出来。然而所有的深度学习工具都有利有弊,特别是在语音领域。市面上所有主流的工具包我们都用了,有一些确实比另外一些令我们眼前一亮,但尽管如此,我们还是自己构建了一套更好的代码。”
“深度学习如今被用于语音识别的方方面面,并且将所有的功能原件整合到一个整体架构之中。这将使得技术架构十分简单,远不像面对许许多多的独立的架构和组件那般复杂头痛。在未来随着架构的成熟和标准化,我们将会看到CPU将具有对这些架构的辅助功能,可能还会出现包含这些架构的功能芯片。“
对于语音识别,IBM有自己基于客户的神经网络模型供Watson训练使用。这些模型的驱动基础是计算速度和内存,慢慢我们也发现,这正是最大的两个瓶颈,尤其是内存。
“GPU的运算速度非常快但内存是有限的,这正是训练海量语料的瓶颈。将这些元素储存在本地内存中相较于从芯片中提取具有明显的优势。也有的算法是将多个GPU的训练结果结合起来实现并行计算。然而我们最需要的还是又快内存又大的GPU。”
除了语音专用的芯片,我们还和Picheny探讨了其他可能推动语音识别技术的架构,例如深度学习公司Nervana Systems(Intel收购)。其中最具潜力的将会是神经形态芯片,IBM也研制了自己的TrueNorth。“神经形态芯片领域已经有很多出色的工作性能也十分强劲,但是这些芯片的发展瓶颈在于需要完全不同的编程语言,GPU庞大的用户群体不愿意用一个不熟悉的新语言来编程。”
FPGA也面临过同样的问题,虽然有很多中间组建的解决方案,但是编程依旧不是那么容易。在专用的芯片掌控这个领域之前,人们还是倾向于使用GPU CUDA生态系统中的库来实现一个个深度学习应用。
这里要特别提一下Watson:Pichney也觉得很难精确地说到底有多少个不同的架构和模型被用来构建Watson AI系统。所有的东西都在飞速的变化和迭代,特别是在近两年发展的速度让人应接不暇。Watson已经和当年大不相同,我们已经不需要去了解Watson系统构成的模型和软硬件架构了。看了Pichney 的故事,我们就能感受到将这门多个语音组件融合为统一的整体,并实现特定功能的便捷和强大,而这一切对于Watson来说都没有区别,通用的架构对于实现复杂的学习问题拥有十分重要的意义。
-END-
本文来源于"中国人工智能学会",原文发表时间" "