本节书摘来自华章出版社《云数据管理:挑战与机遇》一书中的第一章,第1节,作者[美] 迪卫艾肯特·阿格拉沃尔(Divyakant Agrawal) 苏迪皮托·达斯(Sudipto Das)阿姆鲁·埃尔·阿巴迪(Amr El Abbadi) 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
‖第1章
简 介
当代技术的快速发展导致大规模数据中心(也称为云)中的用户应用、服务和数据的数量急剧增加。云计算已经使得计算基础设施商品化,就像日常生活中的许多其他实用工具一样,并且大大减少了创新型应用及其大规模部署之间的基础设施障碍,从而可以支持分布在世界各地的大规模用户。在云计算出现之前,对一个拥有大规模用户群的新应用的市场验证,往往需要在计算基础设施方面进行大规模前期投资才能使得应用可用。由于云基础设施的即用即付收费机制和弹性特征,即根据工作负载动态地增加或减少服务器数量,大部分基础设施风险都转移到了云基础设施提供商身上,从而使得一个应用或服务能够支持全球范围内的用户,影响更多人。例如Foursquare、Instagram、Pinterest以及很多其他应用,在全世界范围内有数百万用户访问,正是云计算基础设施才使得如此大规模的部署成为可能。
虽然云平台简化了应用程序的部署,但是服务提供商面临着前所未有的技术和研究挑战,即,开发以服务器为中心的应用程序平台,能够实现无限数量用户的7×24小时的网络访问。过去10年,很多技术领先的网络服务提供商(如Google、Amazon和Ebay)积累的经验表明,云环境下的应用程序基础设施必须满足高可靠性、高可用性和高可扩展性。可靠性是确保一个服务能够连续访问的关键。同样,可用性是指一个给定系统能够正常工作的时间百分比。可扩展性需求代表系统处理逐渐增加的负载的能力,或者随着额外资源的增加(尤其是硬件资源),系统提高吞吐量的能力。可扩展性既是云计算环境下的关键要求,同时也是一个重大挑战。
一般来说,一个计算系统的硬件增加以后,如果其性能能够随增加的资源成比例提高的话,该系统就是一个可扩展的系统。系统有两种典型的硬件扩展方式。第一种方式是垂直扩展(vertically,或称scale-up),垂直扩展是指增加单个服务器的资源,或者用功能更强大的服务器进行替换,一般涉及更多的处理器、内存和服务器有更强的I/O能力。垂直扩展能够有效地为现有的操作系统和应用模块提供更多的资源,但是需要对硬件进行替换。此外,一旦超过一定规模以后,服务器能力的线性增加会导致开销的超线性增加,从而导致基础设施代价大幅度增加。另外一种系统扩展方式是水平增加硬件资源,又称为横向扩展(horizontally,或称水平扩展,scale-out)。水平扩展意味着无缝地增加更多的服务器,并进行工作负载的分配。新服务器可以逐渐添加到系统当中,这样可以保证基础设施的开销(几乎)是线性增加的,从而可以很经济地构建大规模的计算基础设施。但是,水平扩展需要高效的软件方法来无缝地管理这些分布式系统。
随着服务器价格的下降以及性能需求的不断增加,可以用低成本的系统来构建大规模的计算基础设施,部署高性能的应用系统,如网络搜索和其他基于网络的服务。可以用数百台普通服务器构建一个集群系统,其计算能力往往可以超过很多强大的超级电脑。这种模型也得益于高性能连接器的出现。水平扩展模型还促使对高I/O性能的共享数据中心的需求日益增加,这种数据中心也是大规模数据处理所需要的。除了硬件和基础设施的上述发展趋势外,虚拟化(virtualization)也为大规模基础设施的共享提供了优雅的解决方案,包括对单个服务器的共享。水平扩展模式是当今大规模数据中心的基础,构成了云计算的关键基础设施。谷歌、亚马逊和微软等技术引领者都证明,由于很多应用能够共享相同的基础设施,因此数据中心能够带来前所未有的规模效应。这3家公司不仅对公司内部的应用实现共享,同时还在各自的数据中心中提供Amazon Web Services(AWS)、Google AppEngine和Microsoft Azure等框架来为第三方应用提供服务,这样的数据中心称为公有云。
图1-1展示了部署在云基础设施中的网络应用的软件栈示意图。应用程序客户端通过互联网连接到应用程序(或服务)。应用程序接口往往是通过应用程序网关或者负载均衡服务器来把请求路由到网络和应用服务器层的相应服务器上。网络层主要负责处理访问请求并对应用逻辑进行封装。为了加快访问速度,频繁访问的数据一般都存储在由多个服务器构成的缓冲层上。这种类型的缓冲一般是分布式的,并且由应用层来负责显式管理。应用程序的持久化数据存储在一个或多个数据库服务器中(这些服务器组成数据库层)。存储在数据库管理系统(DBMS)中的数据构成了基准数据,即应用程序正常操作所依赖的数据。部署在大规模云基础设施中的大部分应用程序都是数据驱动的。数据和数据库管理系统在整个云软件栈中都是不可或缺的组成部分。由于数据管理系统是整个软件栈中的重要组成部分,所以数据往往被复制多份(参见图中的虚线部分)。这种复制机制在一个DBMS服务器宕机的情况下也能够提供高可用性。另外一个挑战是如何应对日益增长的数据量和访问请求。本书将主要关注云软件栈的数据库层设计中面临的诸多挑战。
云计算领域中数据库管理系统广泛使用的主要原因在于DBMS的成功,尤其是关系型数据库管理系统(RDBMS)的巨大成功能够满足不同类型应用程序在数据建模、存储、检索和查询方面的要求。DBMS成功的关键因素在于其所具备的诸多特性:完善的功能(用简单、直观的关系模型对不同类型应用程序进行建模),一致性(能有效地处理并发负载并保持同步),性能(高吞吐、低延迟和超过25年的工程应用经历),以及可靠性(在各种失效情况下确保数据的安全性和持久性)。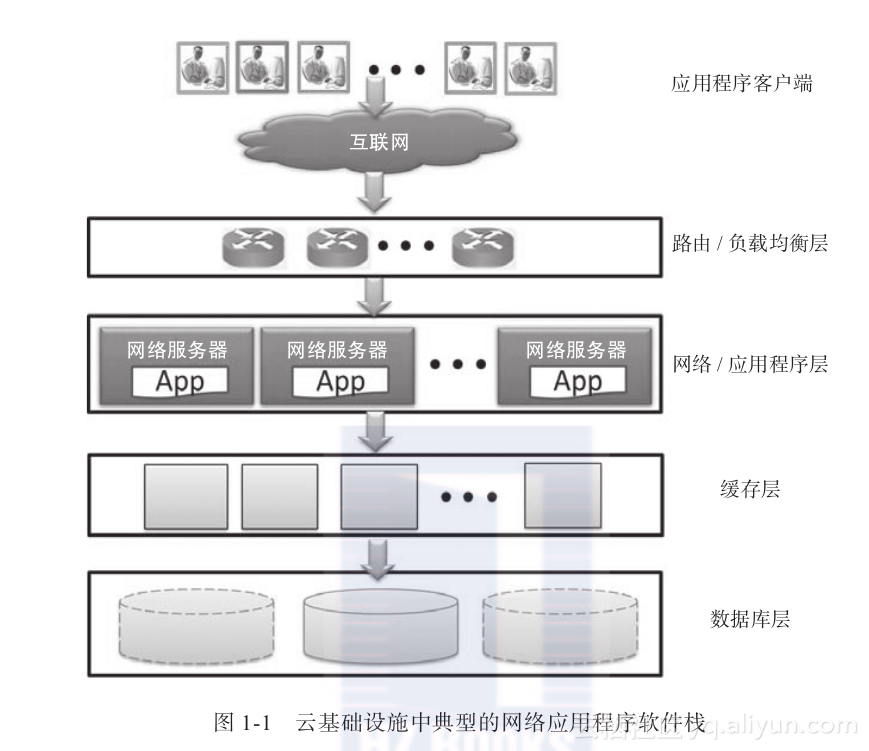
虽然取得了巨大的成功,但是在过去10年间人们一直认为DBMS和RDBMS并不适合云计算。主要原因在于,和云服务中的网络服务器、应用程序服务器等组件不同(网络服务器、应用程序服务器可以很容易从少数服务器扩展到成百上千甚至上万台服务器),DBMS不容易扩展。实际上,现有的DBMS技术无法提供足够的工具和方法来对一个现有数据库部署进行横向扩展(从几台机器扩展为很多机器)。
在云计算平台中确保基于Web的应用程序具有可扩展性的基本要求是能够支持无限数量的终端用户。因为系统的可扩展性仅能保证系统能够扩展到更多的服务器或用户请求,所以可扩展性只是一个静态属性。即,可扩展性无法确保系统的规模能随着用户负载的浮动而动态变化。相反,系统弹性则是动态属性,因为弹性允许系统在不宕机的情况下通过增加服务器进行动态扩展或者通过减少服务器缩减规模。弹性是系统的一个重要属性,其得益于底层云基础设施的弹性。
为了能够水平扩展到数千台服务器、具备弹性、可以跨越多个地理区域和具备高可用性,很多技术引领者都开发了具有自主知识产权的数据管理技术。从历史来看,由于需求的巨大不同,数据管理任务往往被宽泛地分成两大类。第一类是在线事务处理(OLTP),或者是数据服务负载(主要侧重于短小、简单的读/写操作或事务)。另一类是决策支持系统(DSS),或者称为数据分析负载(主要侧重于长时间的、只读的、复杂的分析处理操作)。两类不同的任务负载对系统有不同的要求,针对每种工作负载,历史上出现不同的系统架构。因此,为了应对不同种类的工作负载,两种技术路线共同得以发展。本书主要关注前一个问题(OLTP)在云环境下是如何解决的。分析处理也得到了云数据管理的重要推动,并且产生了很多重要的技术和系统。尤其是谷歌公司提出的MapReduce编程模型[Dean and Ghemawat, 2004],该编程模型适合用来在计算机集群中对大规模数据集进行分析。简单来说,MapReduce模式对大规模数据集进行划分,并把每一块映射到不同的服务器上。每个服务器负责处理一小块数据,并把处理结果传到一个reducer上,reducer负责收集来自不同mapper的所有结果,并对这些结果进行合并得到最终的输出结果。由于谷歌公司的广泛推广以及开源系统Hadoop[Apache Hadoop]的大受欢迎,MapReduce模式成为云时代最受关注的新兴技术。然而关于MapReduce和RDBMS的争论一直不断[Dean and Ghemawat,2010,Stonebraker et al.,2010],广泛深入的研究也促进了MapReduce和基于Hadoop的分析平台的快速发展。本书的剩余章节将主要关注云环境的数据服务系统。
早期开发的可扩展的数据服务系统是一类称为“键–值存储”的系统。Bigtable [Chang et al., 2006]、Dynamo [DeCandia et al.,2007]和PNUTS [Cooper et al., 2008]等系统起到了引领作用,紧接着一系列开源系统涌现出来,这些开源系统或者是复制了这些内部(in-house)系统的设计思想,或者是受到这些内部系统的启发。键–值存储系统与RDBMS的主要区别在于,传统RDMS数据库中的所有数据都被视为是一个整体,DBMS的主要职责是确保所有数据的一致性。然而,在键–值存储系统中,这种关系被分隔成主键和其相关的值,键–值对被视为独立的数据单元或信息单元。应用程序的原子性和一致性以及用户访问仅仅在单个主键级别得以保证。这种细粒度的一致性允许键–值存储系统对数据库进行水平扩展,很方便地把数据从一台机器迁移到其他机器,能够把数据分布到数千台服务器上,同时能避免繁重的分布式同步,在部分数据不可用的情况仍然能够继续为用户提供服务。此外,键–值存储系统设计的目的是具有弹性,而传统的DBMS一般是用于具有静态配置的企业基础设施,其主要目的是对于给定的硬件和服务器设施实现最高的性能。
所有最初的内部系统都是根据良好的需求而定制的,能够适应特定应用的特点。例如,Bigtable主要是用来进行索引结构的创建和维护,从而为谷歌搜索引擎服务。同样,Dynamo的设计初衷是为亚马逊电子商务网站的购物篮服务,雅虎的社交属性促使了PNUTS的诞生。因此,虽然这些系统都属于键–值存储系统,但是每个系统也都有自己的独特设计。在本书后面的内容中,我们将详细分析每一个系统,从而理解这些设计原则及其权衡。然而,可扩展性、系统弹性和高可用性等关键特点使得这些系统在各自的应用领域大受欢迎,在其他领域,HBase、Cassandra、Voldemort及其他开源系统也得到了广泛使用。键–值系统的广泛使用也预示着NoSQL运动的到来[NoSQL]。虽然单个键–值对粒度的原子性和一致性已经能够满足实际应用的需求,但是在很多其他应用场景下这种访问模式还远远无法满足实际要求。在这种情况下,需要由应用程序开发者来保证多个数据的原子性和一致性。这就导致在不同的应用栈中重复使用多实体同步机制。针对多个数据的访问控制的实现机制在很多开发者博客[Obasanjo,2009]及相关论坛中都有所讨论[Agrawal et al.,2010,Dean,2010,Hamilton,2010]。
总体来说,所面临的关键挑战是如何在保证较高性能、可扩展性和系统弹性的同时实现针对数据库中多个数据片段访问的原子性。因此,在大规模数据中心中也要支持经典的事务[Eswaran et al.,1976,Gray,1978]概念。分布式事务已经有很多研究成果[通常是服务器的大集群)性能。这些基本的设计原则和各种设计方案是本书剩余章节的主要讨论内容。特别是我们会分析各种各样的系统和方法,其中有些是学术中的原型系统,有些是工业级的产品。这些方法经常利用一些巧妙的特性和应用程序的访问模式,或者对提供给应用层的功能加以限制。关键挑战在于如何在增强键–值存储系统功能的同时不降低系统性能、弹性和可扩展性。实际上,云平台成功的主要原因在于其能够在云环境下保证数据管理的简洁性、可扩展性、一致性和系统弹性。
把DBMS扩展到具有大规模并发访问用户的大型应用尚存在一些挑战,很多云平台在为大量小规模应用提供服务时也面临诸多挑战。例如,Microsoft Windows Azure、Google AppEngine和Salesforce.com等云平台一般都要为成千上万个应用提供服务,但是大部分应用可能只占用一小部分存储空间,并发请求的数量也只占整个云平台的很小比例。关键的挑战在于如何以一种高性价比的方式来为这些应用提供服务。这就导致了多租户技术的出现,多个租户可以共享资源并在一个系统中共存。多租户数据库已经成为云平台软件栈中重要且关键的组成部分。这些租户数据库一般不是很大,因此可以在单个服务器中运行。因此,DBMS的全部功能都可以得到实现,包括SQL操作和事务。然而,系统弹性、资源的有效共享和大量小租户的统一管理等问题也非常重要。为了满足这些需求,在数据库层已经产生了多种虚拟化方法。硬件和系统软件的虚拟化主要用于对大规模数据中心基础设施进行共享和管理。然而,数据库内部的虚拟化可以支持和隔离多个独立的租户数据库,该技术引起了数据库学术界和工业界的广泛关注。本书后面的部分将主要讨论设计灵活的多租户数据库系统面临的诸多挑战。
云计算和大规模数据中心的数据管理主要建立在基础的计算机科学研究之上,包括分布式系统和数据库管理。第2章中,我们主要提供分布式计算和数据库的一些基本背景资料,尤其是分布式数据库。第2章中涉及的很多主题都非常重要,有助于理解后面章节中的一些高级概念。但是对这些领域的文献资料比较熟悉的读者可以直接跳到第3章,第3章介绍云环境下关于数据管理的早期研究工作,特别介绍了基本的技术发展趋势以及取得的经验教训,并对一些特定的系统进行了重点讲述。接下来讨论了如何在云环境下支持原子操作(事务)。第4章讨论了一些新的尝试,试图将所需要的数据托管到一个地方,这样就可以避免复杂的分布式同步协议,也能够确保访问操作的原子性。第5章针对分布式事务和跨站点甚至跨数据中心的数据访问提供了通用的解决方案。第6章讨论多租户的问题,并对云环境下的实时迁移方法进行了探讨。第7章对相关经验教训进行了总结,并指出了未来的研究方案。




