分布式编程模型的背景
编程模型是指编程的方法而不是特指某一种编程语言,如面向对象的编程就是一种编程模型。编程模型大致分为两类:命令式编程和声明式编程。前者最典型的是面向过程的编程语言,如C语言;后者与前者差异较大,如常见的SQL语言就是一种典型的声明式语言。

上图是命令式和声明式语言统计文件(表)内行数的具体程序,可以看出两者存在明显的差距。在命令式编程中,会有很多细节,需要告诉程序每一步做什么,中间状态怎么维护以及如何得到最终结果;而声明式编程相对更加简洁,更加注重结果而不考虑过程。
分布式编程模型
一个高效、可用的分布式编程模型首先能够处理TB以及PB以上的数据量,因此编程模型需要以数据为中心;其次应该能够处理现实生活中的各类异构数据格式;同时,需要具有较高的数据处理效率,能够在几小时甚至几分钟内处理上PB的数据,因此必须使用多机并行计算能力;此外,在分布式环境下的编程模型需要尽可能简单易用,可以对用户隐藏盘古和伏羲之类的底层系统。
在分布式计算领域,从数据处理的时效性出发,为在线数据应用和离线数据计算两大类,如同样的SQL语言,在在线数据应用领域可以处理类似于“小明买了一只手机”之类的操作,也可以完成“最近5年所有手机商城成交量”的计算需求,本文主要侧重于后者——分布式离线数据计算。
MapRedue编程模型
MapReduce模型对输入格式的要求较灵活,可以是关系型数据,也可是其他格式的数据。其编程思想来自于函数式编程,函数式编程里的两个函数(Map和Reduce)组合构成MapReduce模型。Map函数是将一个Key-Value队映射到一组新的Key-Value队,可以是一对一、一对多甚至一对零的映射;Reduce函数是将同一个Key以及它对应的一组Value映射到一组新的Key和Value。
MapReduce模型中Map和Reduce都是函数式编程语言里的高阶函数,它们的输入是另外一个做数据变换的函数。WordCount程序是最有名的MapReduce程序,它相当于分布式编程界的HelloWorld程序。

上面是Hadoop MapReduce 中的Map函数的具体代码,可以看到,Map函数有四个参数,除了最核心的Key和Value两个参数外,还有专门用来搜集输出结果的Output参数,还有一个参数Reporter用来记录程序的进度或者其他信息。这里的Key和Value的数据类型可以自定义,上图的输入Value是Text类型,每一个value是一行文本数据,输入的Key在WordCount中没有意义,可以忽略。首先把Value转换成字符串,然后再把String用Tokenizer的方法切分成单词,然后通过While循环把单词及数字1作为Key和Value输出,其中数字1是指单词在该行里只出现过一次。

Reduce函数代码如上图所示,同样是四个参数,其中输入的Key是刚才Map输出的Key;输入的Value列表是用迭代器Iterator来表示。Reduce的输入参数表示一个Key对应了多个Value。编程框架已经聚合完毕,编程人员无需知晓聚合是怎么发生的。函数内部的逻辑比较简单,依次读入Value的值并把它们加起来得到一个总数,最后把原始的Key和计算得到的总数作为Value输出。
在分布式编程的领域中,MapReduce具有很好功能和特点解决了底层系统的复杂度的问题:
▪️并发性方面,MapReduce程序可以多线程或者多进程并发执行,并且需要跨多台机器。MapReduce框架将数据根据数据量进行了自动切分,很好地实现了负载均衡。Map任务依赖于输入数据, 而Reduce任务只依赖于前面的Map任务的输出,各个任务之间相互没有影响,所以任何一个Map或者Reduce函数都可以独立运行。
▪️容错性方面,因为分布式文件系统的数据都有副本,一台机器的问题只影响部分任务的执行而不影响任务输入数据的完整性,所以每个任务都可以重新启动并且根据函数式编程的特点重新计算任务并不影响结果;另外MapReduce框架的Master结点可以监控到失败任务,自动在其他机器上重新运行失败的任务。
▪️数据本地化方面,利用伏羲的调度功能,MapReduce框架把任务启动到输入数据所在的机器上,完美地解决了数据本地化问题。
MapReduce模型的应用场景也非常广泛,常用于网站日志分析和流量统计、商业数据分析、机器学习和数据挖掘以及分布式索引等方面。
扩展MapReduce
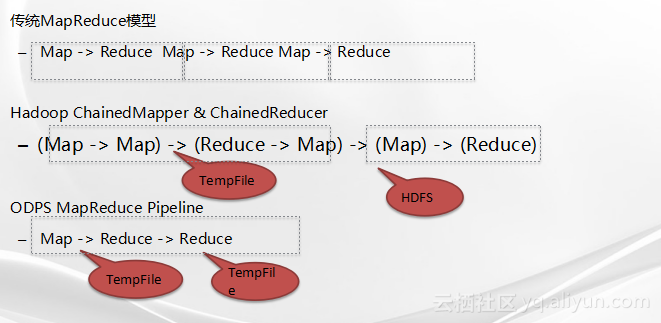
传统的MapReduce任务一般是很规整的Map加Reduce的形式,如果分析程序或者算法比较复杂,则可能需要多道MapReduce程序,也就是Map加Reduce,接着Map加Reduce,再接着Map加Reduce;如果用户想突破这个限制,比如让多个Map连接在一起或者Reduce后面还有Reduce,实现起来还是比较复杂的。在开源软件Hadoop里,有Train the map和Train the reduce的两个类帮助用户考虑了这个问题,但是因为Hadoop MapReduce框架的限制,Train the Map只能在一个Map后面再跟另外一个Map或者在Reduce的前面加上一个或者多个Map,而做不到Reduce后面直接跟一个Reduce;但是ODPS的MapReduce框架可以做到多个Reduce运算符串联的操作,这和ODPS MapReduce底层伏羲的DAG调度模型有关。
关系型数据编程模型
最近几年分布式领域涌现了各种关系型语言,如Google论文里的FlumeJava以及它的开源实现Crunch、Hadoop的开源社区内的Cascading、Pig Spark等语言。这类语言的数据源是关系型数据,如Table、Relations 、PCollection、RDD等;此外,关系型语言包含了一系列的关系运算符,如FlumeJava内的Primitive Operations、Cascading里的Pipes以及Pig中的Pig Latin。
下面以Pig为例,具体解释。Pig最大的特点是定义了一系列的算子(关系型运算符)。采用Pig编写的WordCount包括输入和输出只有五行代码:

第一步是读入一个文件产生一个关系数据集A;第二步是将A通过ForEach算子转换为单词的列表;第三步再把单词通过CgroupBy进行聚合;第四步是对每个Group做计数,也采用Foreach算子;最后一步是把结果数据集D存储到文件中。
在该Pig的例子中隐藏了不少细节,比如其中TOKENIZE方法其实是扩展自Pig内制的I will founk类并实现了exec的方法,在方法中加入了自己的处理逻辑。函数内部的细节有点类似于MapReduce版的WhatCount里面的Map函数,这个函数加上Foreach算子就是典型的函数式编程的例子,其中输出只依赖于输入参数,函数不会改变外部的状态。
下面来看另一个例子:

该例由SQL语言编写,目的是找出计算机系学生来源前十名的省份及学生数目,观察其中的SQL的关键词,再结合上文提到的关系型语言,可以看出SQL是一种关系型编程语言,SELECL 、JOIN、 GROUPBY、WHILE等算子在其他关系型语言中都能找到而且语意大同小异。
MapReduce是一种简化的关系型语言,对外只暴露了Map和Reduce两种接口,整个MapReduce框架用其他的关系语言来表示会更加清楚。
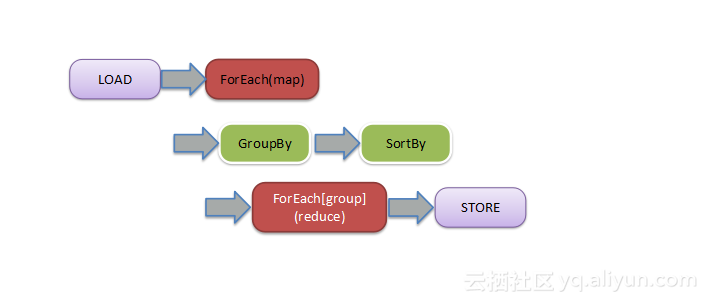
首先是读取文件对应于LOAD运算符;接着对每一条数据做Map操作,对应于ForEach运算符,ForEach是一个高阶函数,它的输入是一个具体的Map函数;接下来的两步对用户透明,分别是GroupBy和SortBy运算符,经过这两个操作,把相同Key的记录聚合,得到了Key加上Valuelist的结构,即Ruduce的输入;下一步的运算符又是ForEach,参数是Reduce函数,最后采用STORE运算符得到最后结果。
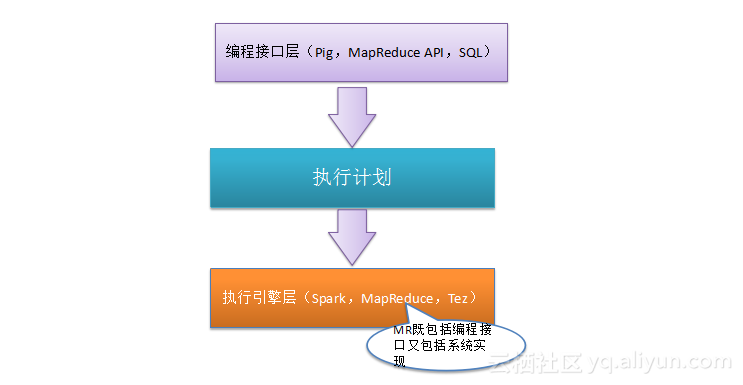
如上图所示,分布式编程模型一般分为三层:最上层是面向用户的编程接口层,如Pig Latin、MapReduce API或SQL等;中间是执行计划层;最下面的是执行引擎,常见的执行引擎由Spark、 MapReduce、Tez等。执行计划层非常关键,它负责将用户的逻辑代码转换为真正在分布式系统上执行的代码,因此,程序可以编写的很简洁但是实际表达能力却非常强;整体在执行计划上实现,执行计划生成器会收集信息,基于规则或者历史信息对执行过程做优化,以期待得到更高效的执行程序;有时执行引擎和编程接口的区别并不十分明显,例如MapReduce既出现在接口层(MapReduce API),又出现在引擎层。
关系型编程模型里大量应用了函数式编程的思想,简化了分布式环境下的编程,而且相对于MapReduce而言,关系型的编程语言的应用范围更加广泛,如SQL等。
关系型编程模型的特点可以简单总结为以下几点:
(1)所有模型都包含基本的编程算子(Operator/Primitives),只需关注数据格式及数据之间的关系。
(2)各类编程框架可以相互转化,甚至一套编程框架可以用另外一套来实现;
(3)编程模型可以是DSL语言,如SQL、Pig,也可以是通用型语言提供编程的SDK,如Spark、Cascading等,两种方式各有优势,适用于不同的场景;
(4)关系型编程模型对使用者隐藏分布式环境下的底层细节,同MapReduce相同,为使用者解决了容错性、并发性和数据本地化的问题。
分布式图计算模型
图是另一类重要的数据结构图,图的结构很简单,其难点在于如何将图的存储和计算分布式化。MapReduce和关系型运算在处理关系型的数据上具有优势,但处理图类型的数据时仍然存在很多问题,如因为IO的问题导致迭代计算效率低、数据之间只能通过Key进行关联等。
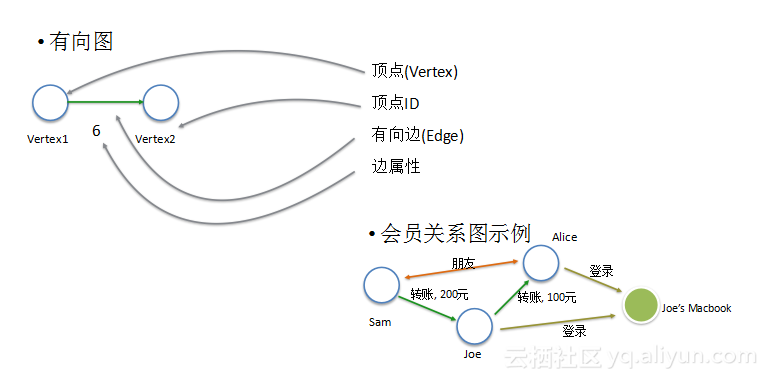
上图是一个有向图的具体结构。图中包含顶点和边两种对象,每个顶点都有ID号,边是顶点与顶点之间的关系。每个顶点和边都有它们的属性,如一条边的距离属性表示两个点之间的距离;右下角是一个实际图,表示某个支付网站中的会员关系,其中点可能是某个会员或会员登录的某台电脑,会员之间的关系可能是朋友或转账关系,都可以用关系图中的边表示。会员和电脑之间也可能发生关系,如Alice登录了Joe的电脑,则Alice顶点到Joe电脑之间会产生一条有向边。
下面来看一下典型的图计算模型——ODPS Graph计算框架。Graph计算框架实现了BSP计算模型,因此其继承了BSP模型的优点和缺点;Graph模型其中的一个核心概念是以顶点为中心的API设计。
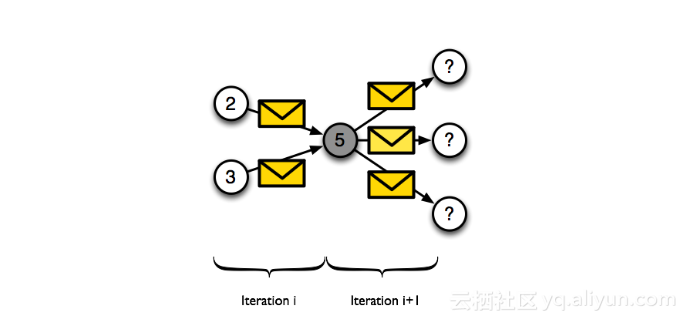
如上图所示,顶点之间的通信是通过消息传递的,每一轮迭代之前,每个顶点都会收到从它的源发来的消息;然后顶点对消息处理,并将结果发给下一个顶点,如顶点5,它收到顶点2和3发的两条消息,2和3可能是它的邻居或者上游结点,经过结点5的处理,它又发出了三条消息,可能它的另外三个邻居,也有可能是刚才的2和3两个顶点;下游的三个顶点接着做刚才的顶点5上发生的操作。整体流程和BSP流程类似,但在Graph模型里,关注的是各个顶点,因此被称为是“先要向顶点那样做思考,然后再写Graph的程序“。
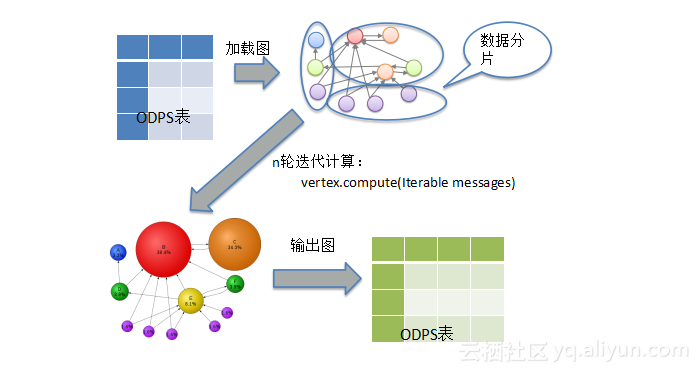
上图清晰的展示了Graph作业的生命周期:数据来自ODPS表,通过加载图的操作,该操作完成一轮从关系表到图的映射;图的存储方式连接表或连接矩阵,在ODPS表保存的就是这类结构,由于图是分布式的图,因此需要进行数据分片(分片方式可自定义,也可采用默认的哈希分片方式),把图加载到不同的计算单元中;图加载和分片之后,进行多轮的迭代运算,这里采用最简单的vertex.compute方法,输入是一系列的消息;经过多轮运算后,得到目标图结构,最后将图输出到ODPS表中。
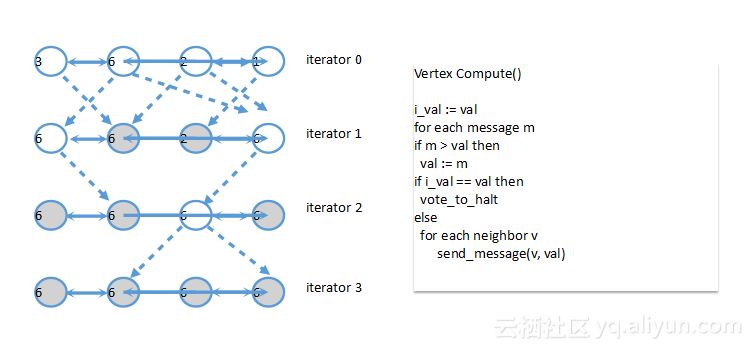
上图是找最大值顶点得Graph编程示例,图中有四个顶点,值分别是3、 6、 2、 1,它们两两之间都有联系。每一轮迭代开始,每个顶点都会向邻居结点发送消息,消息内容是顶点自己的值。因此,顶点3收到了顶点6的消息;顶点6也收到了顶点3的消息...依次类推。所有顶点收到自己消息后,开始比较当前顶点的值和消息顶点的值,如果消息顶点的值更大,
则把自己顶点的值置为收到消息的值,否则就处理下一个结点,如顶点3收到顶点6的消息后,会将自己的值置为6,其他顶点操作相同。
处理完消息和修改值之后,需要进行一轮全局的同步,以确保每个顶点都处理完消息;全局同步后,又是发消息的过程,只有那些在本轮迭代改变过值的顶点才会继续需要发送消息;经过几轮迭代,大家都没有状态更新,则全局最大值找到,也就是6。上图右侧是具体顶点Computer代码示例。
ODPS Graph从性能上看非常适合迭代计算,现在的实现中所有的内部状态都是在内存中,只有加载图、网生图或Checkpoint时,才会写磁盘,因此比较高效,并具有一定的线性扩展能力;因为运算过程中不需要锁和信息量,所以并发度非常高;其次通过Checkpoint和心跳机制保证了Graph的编程框架的容错性。除了ODPS Graph之外,其他图计算相关的编程或软件还有:
▪️Mahout,一个通用的算法库,包括图计算,是基于MapReduce实现的,代码效率并不高。
未来展望
未来分布式编程模型会更加丰富多彩,可能会在各个维度上做扩展,当前主要的编程模型
都是以处理离线数据为主,未来可能会向实时计算方向发展。当前开源社区里涌现了大量的
更加实时的编程引擎,比如Spark、 Tez 、Impala等等,这些引擎让上层编程模型变得更加高效;另外一个方向是从当前的批量计算到流式计算演化,后续处理的数据可能是源源不断地输入,因此需要编程模型能处理此类数据;最后一个方向是编程模型的融合,关系型计算、 图计算、迭代计算等编程模型,如果能融合在一起,将极大地简化编程方法。

