本项目是 Hortonworks开发者认证官方文档的中文翻译版,Hortonworks致力于打造一个全新的大数据处理平台来满足大数据处理和分析的各个使用场景,它组合了大数据平台使用的各个组件, 比如Hadoop、Hbase、Hive、Spark等等一些列的组件, 它安装方便使用便捷, 而且已经在2000节点以上的节点上商用. 本次翻译主要针对对Hortonworks感兴趣和致力于从事大数据方法开发的人员提供有价值的中文资料,希望能够对大家的工作和学习有所帮助。
由于我公司鼓励大家考Hortonworks认证(呵呵,公司出费用),于是今天简单的看了下官方考试大纲,感觉还不错,故翻译了下供大家参考学习,本次翻译并没有咬文嚼字, 而是根据我个人的理解进行翻译, 由于本人能力有限难免有些地方翻译不到位,还希望大家谅解,同时也鼓励大家去看官方文档。
基于真才实学的认证
认证概述
Hortonworks重新设计了它的开发者认证程序, 为了创建一个通过在Hortonworks(HDP)集群上亲自操作所获取的专业知识的认证体系, 而不是回答多项选择问题. HDP开发者认证考试(HDPCD)第一个比较新颖的地方是亲自实践的, 基于性能的考试, 它设计的目的面向那些工作中经常使用像 Pig, Hive, Sqoop and Flume的开发者.
认证(考试)目的
开发者认证的目的是为了给组织和公司提供一种辨别是否是一个合格的大数据应用开发者, 这种认证实在开源的HDP平台对Pig, Hive, Sqoop and Flume组件对数据的存储、运行和分析的应用.
考试描述
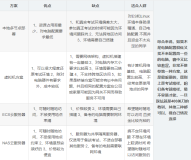
考试主要涉及到三个分类:
- 数据获取
- 数据转换
- 数据分析
考试是在HDP2.2版本上面进行, 通过 Ambari 1.7.0来进行管理, HDP2.2包括 Pig 0.14.0, Hive 0.14.0, Sqoop 1.4.5, 和Flume 1.5.0. 每位考生都可以访问HDP 2.2 集群并在集群上进行一些列任务操作.
考试目的
浏览完成下面任务, 它包括一些指向文档和资源的连接
怎么注册
在 www.examslocal.com 网站创建一个帐号. 注册之后登陆, 选择“Schedule an Exam”, 然后进入“Search Here”输入“Hortonworks”进行搜索,然后选择Hortonworks开发者认证考试.
考试卷购买之后一年之内有效.
时间
2小时
模拟考试
Hortonworks官方提供考生的模拟考试和认证考试的环境和任务是相似的 . 点击 [Practice Exam] 下载安装开始模拟考试.
考试及格情况说明
通过 (MQC)认证的考生需要通过开源的Hortonworks数据平台中的Pig、Hive、Sqoop和Flume对数据进行提取,转换和分析
Prerequisites
想获取HDPCD认证的考生需要完成考试大纲下面的所有任务.
语言
考试语言是英文
Hortonworks大学
Hortonworks 大学是你的专业指导对于Hadoop培训和认证. 考生可以通过公开课程和非公开课程是进行学习. 课程结合通过真实的Hadoop环境演示动手试验来进行.
HDP开发者考试的目的
HDPCD考试的考试需要完成下面每项操作:
| 类型 | 任务 | 源(s) |
| 数据获取 | 通过Hadoop Shell把本地文件上传到HDFS | http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html#put |
| 使用Hadoop Shell在HDFS上创建一个新的目录 | http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html#mkdir | |
| 从一个关系型数据库中导入数据到HDFS | http://sqoop.apache.org/docs/1.4.5/SqoopUserGuide.html#_literal_sqoop_import_literal | |
| 导入关系型数据的查询结果到HDFS | http://sqoop.apache.org/docs/1.4.5/SqoopUserGuide.html#_free_form_query_imports | |
| 从一个关系型数据库中导入数据到一个新的或者已经存在的Hive表里 | http://sqoop.apache.org/docs/1.4.5/SqoopUserGuide.html#_importing_data_into_hive | |
| 从 HDFS里面插入和更新数据到关系型数据库里面 | http://sqoop.apache.org/docs/1.4.5/SqoopUserGuide.html#_literal_sqoop_export_literal | |
| 给你一个Flume配置文件,启动一个 Flume agent | https://flume.apache.org/FlumeUserGuide.html#starting-an-agent | |
| 给你一个配置好的 sink 和source, 配置一个 Flume 固定容量的内存 channel | https://flume.apache.org/FlumeUserGuide.html#memory-channel |
| 类别 | 任务 | 源(s) |
| 数据转换 | 写出并执行一个pig脚本 | https://pig.apache.org/docs/r0.14.0/start.html#run |
| 加载一个没有schema信息数据到Pig | https://pig.apache.org/docs/r0.14.0/basic.html#load | |
| 加载数据到Pig里面并关联一个schema | https://pig.apache.org/docs/r0.14.0/basic.html#load | |
| 从Hive表里面加载数据到Pig | https://cwiki.apache.org/confluence/display/Hive/HCatalog+LoadStore | |
| 通过Pig把加载的数据格式化 | https://pig.apache.org/docs/r0.14.0/basic.html#foreach | |
| 转换数据匹配一个给定的Hive schema | https://pig.apache.org/docs/r0.14.0/basic.html#foreach | |
| 对 Pig 中数据进行分组 | https://pig.apache.org/docs/r0.14.0/basic.html#group | |
| 使用Pig移除记录里面关联的空值 | https://pig.apache.org/docs/r0.14.0/basic.html#filter | |
| 把 Pig 中的数据保存到HDFS中指定目录里面 | https://pig.apache.org/docs/r0.14.0/basic.html#store |
| 把 Pig中的数据保存到Hive表里 | https://cwiki.apache.org/confluence/display/Hive/HCatalog+LoadStore | |
| 对Pig数据进行排序输出 | https://pig.apache.org/docs/r0.14.0/basic.html#order-by | |
| 把Pig中关联重复数据移除 | https://pig.apache.org/docs/r0.14.0/basic.html#distinct | |
| 对Pig MapReduce指定reduce任务数量 | https://pig.apache.org/docs/r0.14.0/perf.html#parallel | |
| 使用Pig进行关联操作 | https://pig.apache.org/docs/r0.14.0/basic.html#join-inner andhttps://pig.apache.org/docs/r0.14.0/basic.html#join-outer | |
| 通过Pig join操作生成一个副本 | https://pig.apache.org/docs/r0.14.0/perf.html#replicated-joins | |
| 运行一个Pig 任务通过 Tez | https://pig.apache.org/docs/r0.14.0/perf.html#tez-mode | |
| 在一个Pig 脚本内,通过注册一个Jar来使用定义的函数 | https://pig.apache.org/docs/r0.14.0/basic.html#register andhttps://pig.apache.org/docs/r0.14.0/udf.html#piggybank | |
| 在Pig 脚本内, 使用定义的函数定义一个别名 | https://pig.apache.org/docs/r0.14.0/basic.html#define-udfs | |
| 在一个Pig 脚本内, 执行一个用户定义函数 | https://pig.apache.org/docs/r0.14.0/basic.html#register |