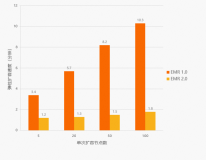
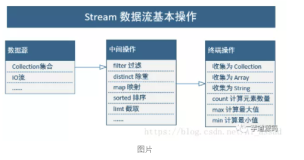
《大数据计算服务MaxCompute产品最新动态》,首先介绍了MaxCompute的发展历程和技术架构,然后对MaxCompute 2.0版本新特性和新技术进行了详细介绍。
热点热议
作者:大数据史记
作者:薯条酱
知识整理
作者:bucky
C语言的5种存储类以及关键字volatile、restrict
作者:bucky
作者:封神 发表在:阿里云E-MapReduce
Spring Boot 整合 Elasticsearch,实现 function score query 权重分查询
作者:bysocket
作者:cadem
美文回顾
作者:【云行】
日志服务(原SLS) 2.5发布:支持SQL进行日志实时分析
如何在 Ubuntu 上使用 pm2 和 Nginx 部署 Node.js 应用
作者:王二辉
作者:茶花盛开
《Spark大数据分析:核心概念、技术及实践》大数据技术一览
作者:华章计算机
往期精选回顾