丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
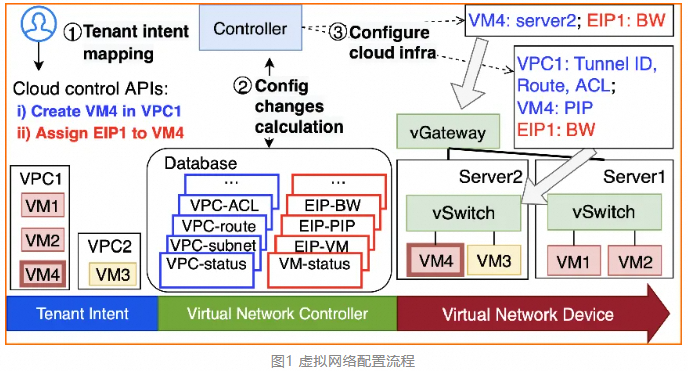
NSDI'24 | 阿里云飞天洛神云网络论文解读——《Poseidon》揭秘新型超高性能云网络控制器
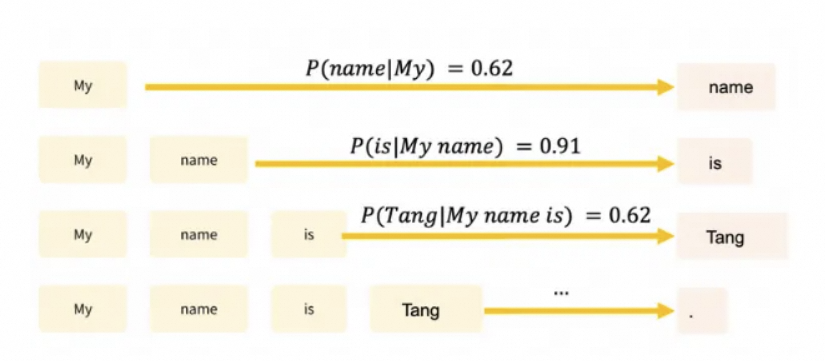
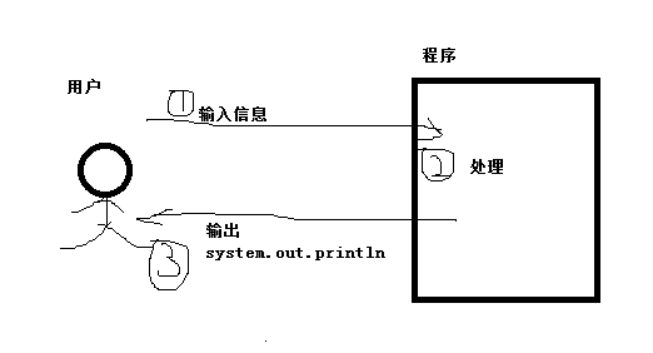
一篇关于DeepSeek模型先进性的阅读理解
一招解决数据库中报表查询慢的痛点
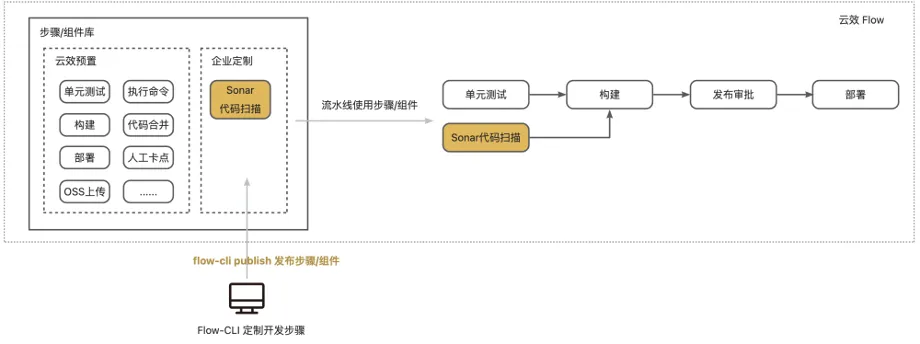
Flow-CLI 全新升级,轻松对接 Sonar 实现代码扫描和红线卡点
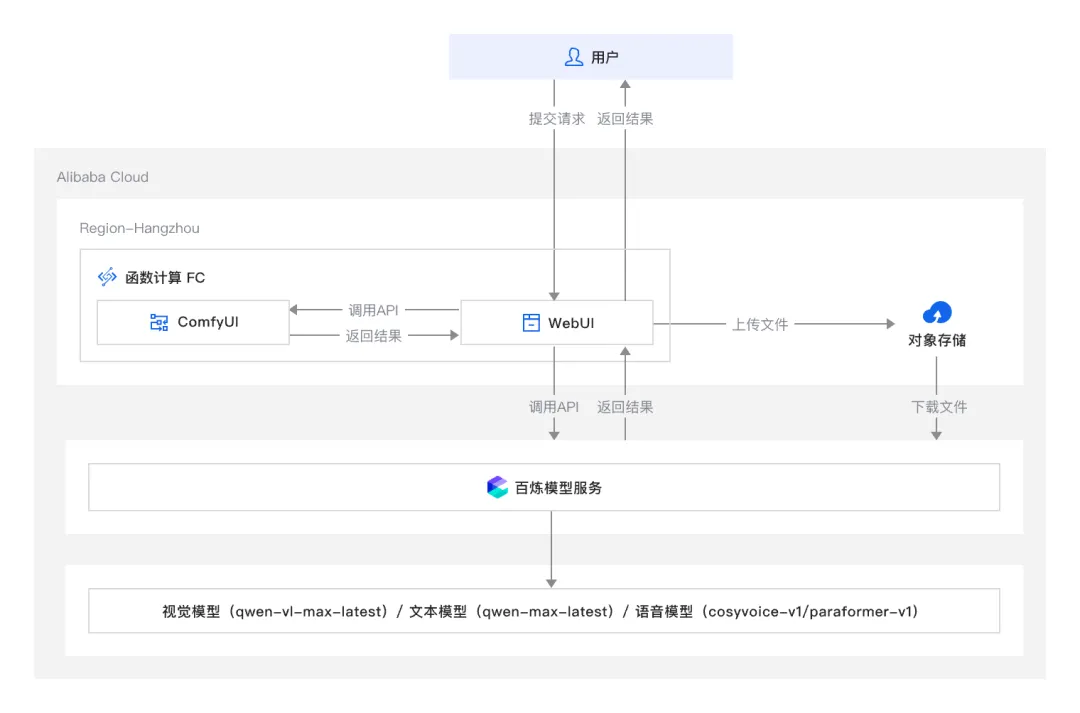
AI 短剧遇上函数计算,一键搭建内容创意平台
海外泼天流量|浅谈全球化技术架构
云端问道18期实践教学-AI 浪潮下的数据安全管理实践
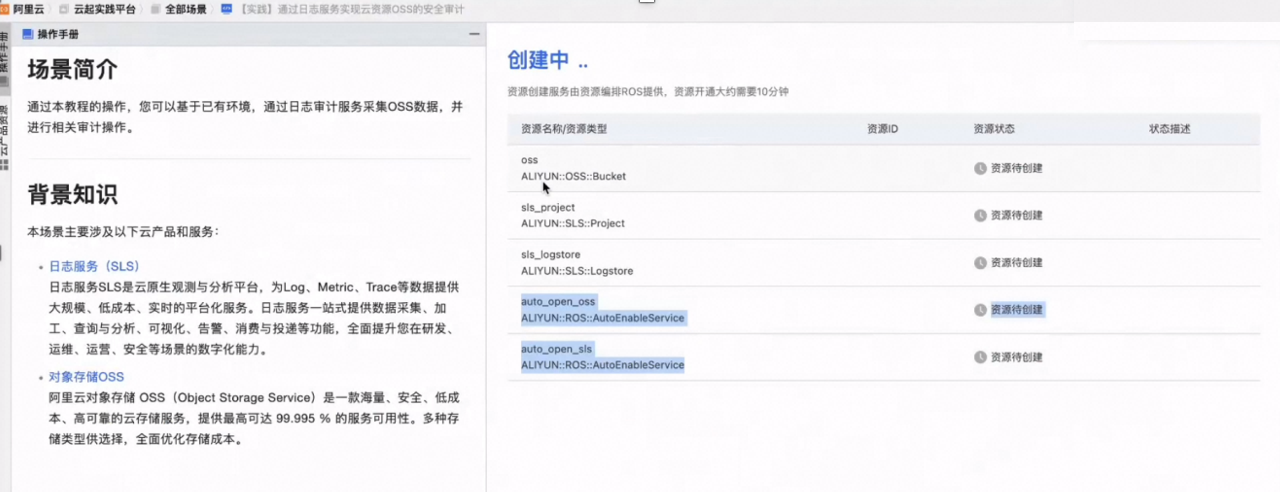
网络安全视角:从地域到账号的阿里云日志审计实践
云端问道11期实践教学-创建专属AI助手
OpenAI故障复盘 - 阿里云容器服务与可观测产品如何保障大规模K8s集群稳定性
探索大型语言模型LLM推理全阶段的JSON格式输出限制方法
高弹性、低成本的云消息队列RabbitMQ 版
体验云数据库RDS通用云盘核心能力
云端问道9期方案教学
10 分钟打造你的专属 AI 客服
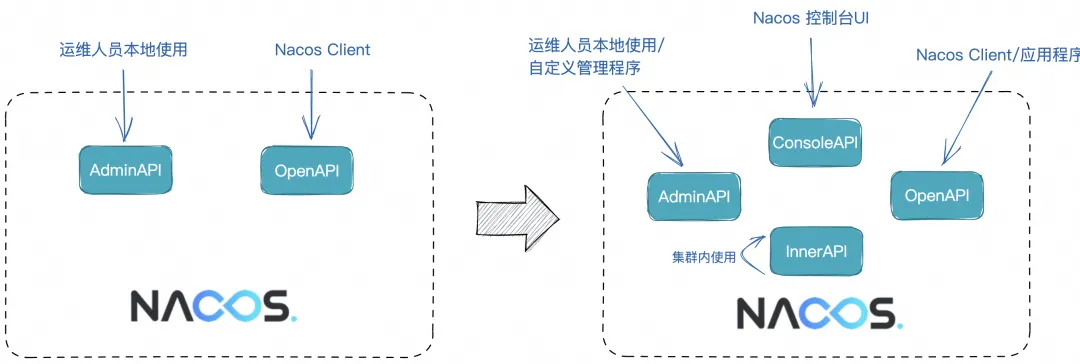
Nacos 3.0 Alpha 发布,在安全、泛用、云原生更进一步
SpringCloud 应用 Nacos 配置中心注解
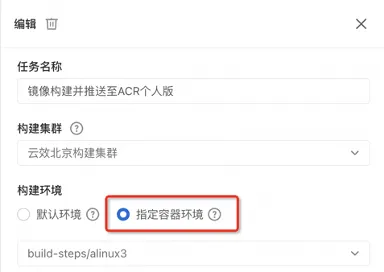
更快、更灵活、场景更丰富,云效镜像构建能力升级啦
阿里云“山海计划”:基于UE引擎的“中国特色”城市场景AIGC方案
C5GAME 游戏饰品交易平台借助 RocketMQ Serverless 保障千万级玩家流畅体验
HarmonyOS NEXT - ArkUI: Text组件
# 【Java全栈学习笔记-U1-day02】变量+数据类型+运算符
智能手表续航太短?聊聊可穿戴设备的能耗管理黑科技
大模型也能当“运维警察”?——大模型技术在异常检测中的应用
Hadoop生态系统:从小白到老司机的入门指南
HarmonyOS NEXT - 页面路由
HarmonyOS NEXT - Stage模型和应用/组件级配置
HarmonyOS NEXT函数和自定义构建函数
HarmonyOS NEXT条件语句和循环迭代
模型即产品:万字详解RL驱动的AI Agent模型如何巨震AI行业范式
HarmonyOS NEXT数据类型和类
鸿蒙开发:Canvas绘制之画笔对象Brush
算法为舟 思想为楫:AI时代,创作何为?
了解HarmonyOS NEXT IDE: DevEco Studio
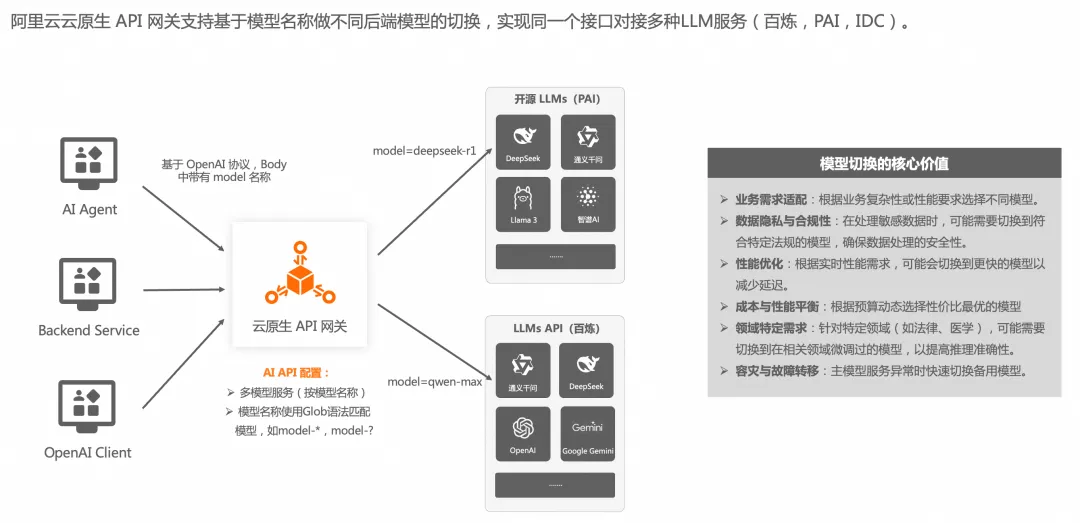
帮你整理好了,AI 网关的 8 个常见应用场景
了解HarmonyOS NEXT工程目录结构
linux常用命令详细说明以及案例
linux命令详细说明以及案例
为什么学习HarmonyOS NEXT?
安全体检评测
鸿蒙开发:事件订阅EventHub
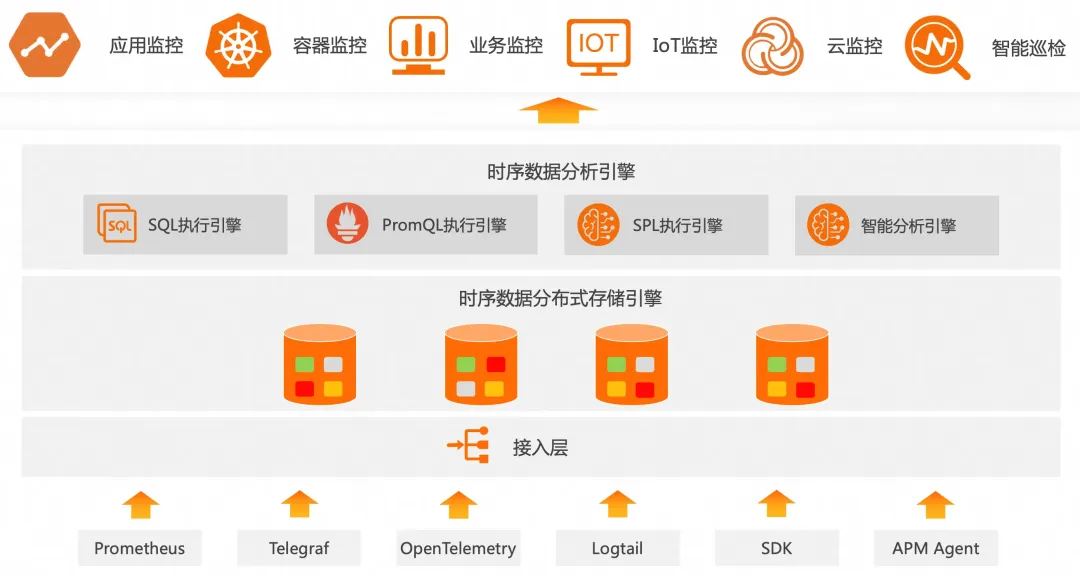
阿里云下一代可观测时序引擎-MetricStore 2.0
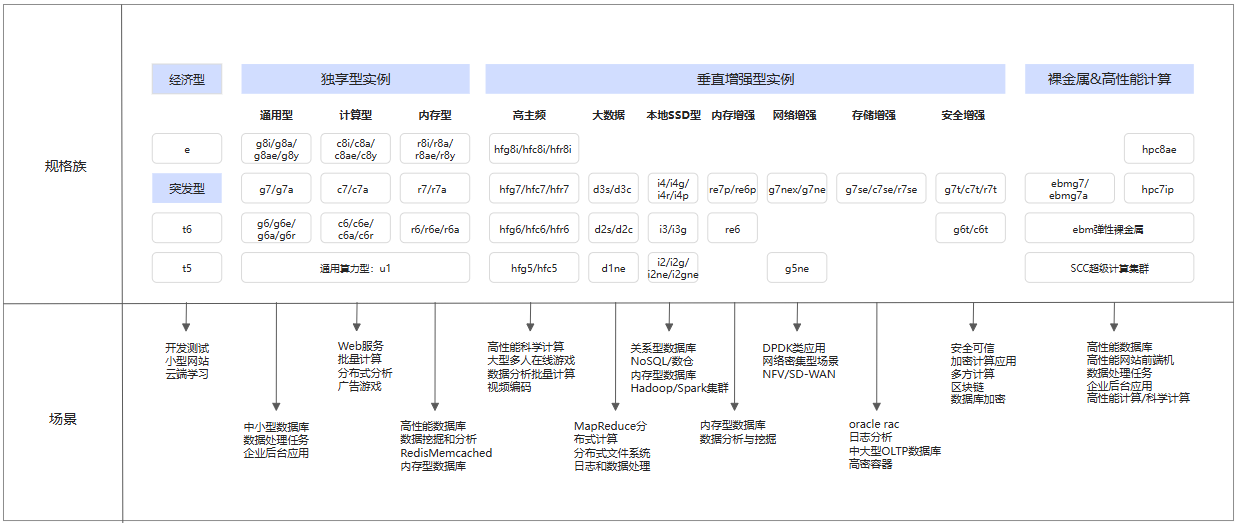
云服务器规格与带宽选型
破界·共生:生成式人工智能(GAI)认证重构普通人的AI进化图谱
Deepseek证明了“人工智能发展一日千里”!
乘AI之势,劲吹正能量之风:生成式人工智能(GAI)认证引领新时代
人工智能发展一日千里:生成式人工智能(GAI)认证引领未来新篇章
开源免费真香!Star 1.4k 这款开源在线教育系统让万人学习零压力,企业培训系统一键搭建神器
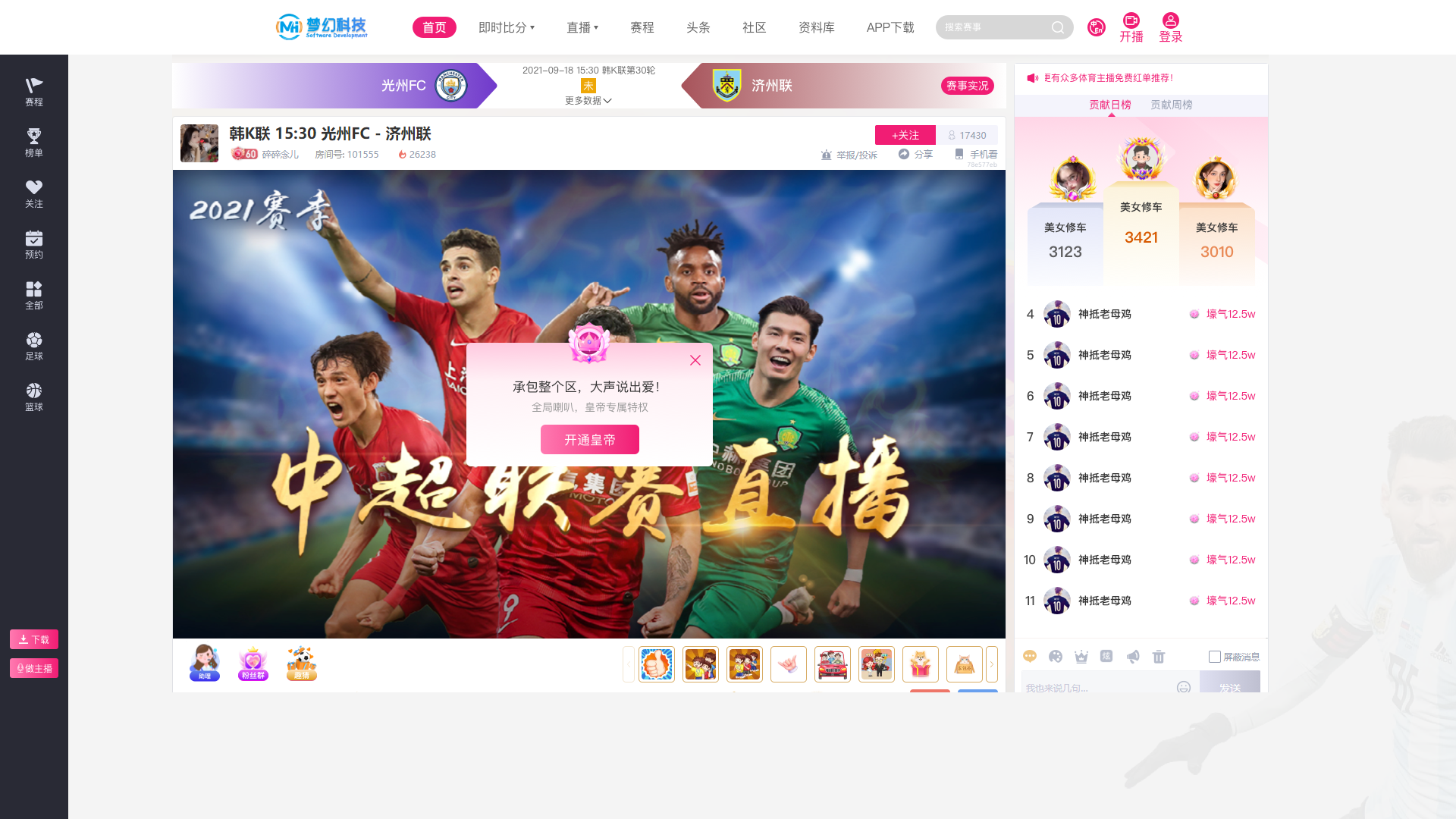
开发体育赛事直播系统:炫彩弹幕直播间界面技术实现方案
社区积分兑好礼