这篇文章是Apache Kafka的作者之一Michael G. Noll写的,他的博客地址在[这里]。
优化Storm计算拓扑性能的过程有助于我们理解Storm内部消息队列的配置和使用,在这篇简短的文章中,我将向大家解释并说明Storm(0.8或0.9版本)的一个工作进程(worker process)和与其相关的多个执行器线程是如何完成内部通信的。
Storm工作进程(Worker processes)的内部消息机制
在以下各章节中,我会交替地使用消息(message)和元组(tuple)两个关键字。
本文中当我提到“内部消息”时,它指的是发生在Storm的单个工作进程内部的消息通信,这类通信只在Storm集群的单台主机(节点)上展开。Storm使用由LMAX Disruptor提供的很多消息队列来完成通信,LMAX Disruptor是一个高性能的线程间消息通信库。
需要注意的是单个工作进程内多个线程之间的通信不同于Storm的多个工作进程之间的通信,工作进程间的通信通常都需要跨主机通过网络完成,对于工作进程间的通信Storm默认采用
ZeroMQ作为基础通信组件(在Storm 0.9版本中开始实验性地支持
Netty),也就是说,当一个工作进程中的任务(Task)想要发送数据到集群中另外一台主机的某个工作进程的某个任务时,Storm将使用ZeroMQ或Netty进行通信。
所以有如下结论供大家参考:
- Storm工作进程内部的通信(同一个Storm工作节点(主机)的线程之间):LMAX Disruptor
- 工作进程之间的通信(通过网络的工作节点(主机)之间):ZeroMQ或者Netty
- 计算拓扑之间的通信:Storm并不原生支持,需要自己实现和维护,可以使用消息系统,比如:Kafka,RabbitMQ和数据库等等。
图片说明
在下一节讨论具体细节前,我们先来看看如下这幅图(参考原图):
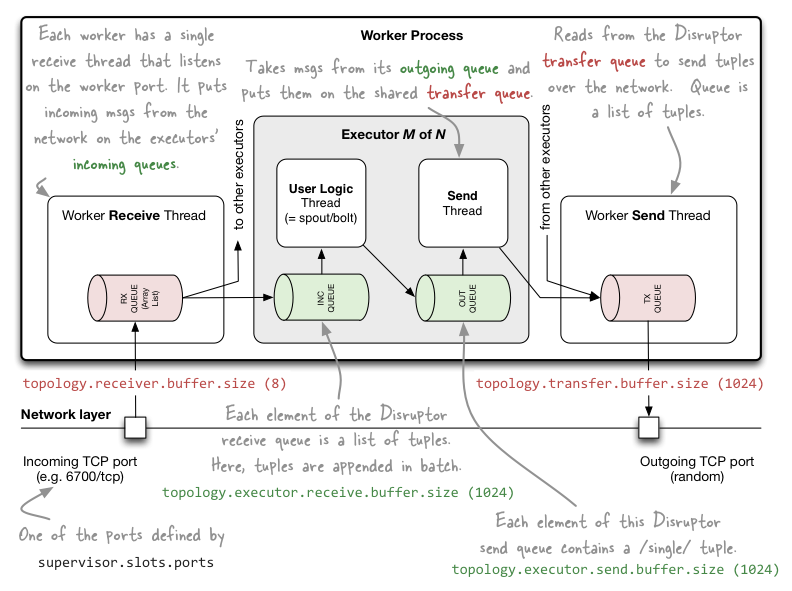
图1:Storm的单个工作进程的内部消息队列概览,与工作进程相关的队列都被标记为红色,与工作进程中的多个执行器线程相关的队列都被标记为绿色,为了看起来清晰,这里只展示了一个工作进程(一般在Storm集群的单个节点上运行着多个工作进程)和这个工作进程中的一个执行器中的所有线程(一个工作进程中一般也存在多个执行器)。
详细描述
现在我们对Storm的工作进程内部的消息机制有了一定了解,接下来可以深入讨论细节了。
工作进程(Worker processes)
为了管理自己的输入消息和输出消息,每个工作进程都有一个消息接收线程和一个消息发送线程,消息接收线程监听工作进程的TCP端口(通过supervisor.slots.ports参数进行配置),消息接收线程还会将收到的消息批量地发送到执行器线程的输入队列中(从recieve缓冲区中读取消息进行发送),topology.receiver.buffer.size参数用于指定接收线程的缓冲区大小,同样的,消息发送线程负责从所有执行器发送线程共享的transfer缓冲区中读取消息,并将消息发送给网络上的其他消息消费者,transfer缓冲区的大小通过topology.transfer.buffer.size参数控制。
- “topology.receiver.buffer.size”参数是工作进程中的接收线程批量向执行线程的输入队列发送数据时的缓冲区内消息数的最大值(接收线程从网络读取消息),此参数如果设置过大可能会造成一些问题(心跳线程挂掉然后吞吐率直线下降),默认值是8条消息,设置的值必须是2的幂(N次方),这是为了兼容LMAX Disruptor组件。
// 示例: 通过Java API配置
Config conf = new Config();
conf.put(Config.TOPOLOGY_RECEIVER_BUFFER_SIZE, 16); // 默认值为8topology.receiver.buffer.size参数不是配置LMAX Disruptor队列的大小,它是配置的一个ArrayList的长度,这个List用来作为输入消息的缓冲,它不需要被多个线程访问,它仅仅是工作进程所专有的,但是因为这个List的元素最终被用来填充基于Disruptor的队列(执行器输入对列),所以这个参数必须是2的幂,参考backtype.storm.messaging.loader.clj的launch-receive-thread!详细信息。
- 使用“topology.transfer.buffer.size”参数配置的transfer缓冲区中的每一个元素实际上是一个tuple的列表,多个Executor中的消息发送线程将批量地把消息从outgoing发送到多个Executor共享的transfer缓冲区(Executor中包含用户逻辑线程和消息发送线程),transfer缓冲区的大小默认是1024个元素。
// 示例: 通过JavaAPI配置
conf.put(Config.TOPOLOGY_TRANSFER_BUFFER_SIZE, 32); // 默认值为1024
执行器(Executors)
每个工作进程控制着一个或多个执行器线程,每个执行器都有一个输入队列 (incoming queue)和一个输入队列(outcoming queue),如上所述,工作进程有它自己专有的消息接收线程,该线程将(从网络接收到的)消息发送到执行器线程的输入消息队列(在选择发送到哪个执行器线程的输入消息队列时,应该是会存在一定的算法进行选择)。同样的,每个执行器都有它自己专有的发送线程,该线程负责将本执行器的输出消息从输出消息队列发送到执行器所在的工作进程的transfer缓冲区,执行器的输入队列和输出队列的大小分别通过“topology.executor.receive.buffer.size”和“topology.executor.send.buffer.size”参数进行配置。
每个执行器都有一个单独的线程用于处理Spout或Bolt中的用户逻辑,另外还有一个发送线程将消息从执行器的消息输出队列批量发送到工作进程的transfer缓冲区。
- topology.executor.receive.buffer.size,该参数是执行器的输入消息队列的配置参数,队列的每个元素是一个tuple列表,tuple被批量地加入到队列元素中,此参数的默认配置是1024个元素,修改配置时的值必须是2的幂(适配于LMAX Disruptor)。
// 示例: 通过Java API配置
conf.put(Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE, 16384); // 批量加入tuple; 默认值是1024 - topology.executor.send.buffer.size,该参数是执行器输入消息队列的配置参数,这个队列的每个元素是一个单独的tuple,默认值为1024,修改配置时的值必须是2的幂(适配于LMAX Disruptor)。
// 示例: 通过Java API配置
conf.put(Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE, 16384); // 单独的tuple; 默认值是1024
更进一步
如何配置Storm的内部消息缓冲
上面提到的各种默认参数配置都可以在
conf/defaults.yaml中找到,你可以通过配置Storm集群的conf/storm.yaml文件全部覆盖这些默认配置信息,你也可以在创建一个Topology时通过Java API中的
backtype.storm.Config 类单独地配置这些参数。
如何配置Storm的parallelism(并行)参数(实际上就是配置集群中工作进程数,各个Spout和Bolt的实例数和线程数)
正确配置Storm集群的消息缓冲与集群的工作负载模式以及Storm集群的并行配置紧密相关,关于Storm集群的并行配置可以看看这篇文章:
Understanding the Parallelism of a Storm Topology
搞明白Storm的拓扑内部在做什么
Storm UI是你观察运行中集群的各项关键指标的一个好的入口,比如:它向你说明了一个Spout或Bolt所谓的“容量”,这各项运行指标可以帮助你决定是否需要修改本文提到的各项与缓冲相关的参数的配置,这些参数的变动将会影响集群的计算性能,这篇文章可以看看:
Running a Multi-Node Storm Cluster
除了这些,你还可以使用像Graphite这样的工具生成各项运行指标并监控这些指标,可以看看下面两篇我写的文章:
Sending Metrics From Storm to Graphite
Installing and Running Graphite via RPM and Supervisord
ooyala放在Github上的metrics_storm项目也是值得参考的(但我还没有用过这个工具)。
性能优化的建议
可以看看Nathan Marz(Storm作者)的演讲:
Tuning and Productionization of Storm.
最开始,可以试试如下参数配置,看看是否能够提升Storm集群的性能。
1 |
conf.put(Config.TOPOLOGY_RECEIVER_BUFFER_SIZE, 8); |
2 |
conf.put(Config.TOPOLOGY_TRANSFER_BUFFER_SIZE, 32); |
3 |
conf.put(Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE, 16384); |
4 |
conf.put(Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE, 16384); |




{kind=link}