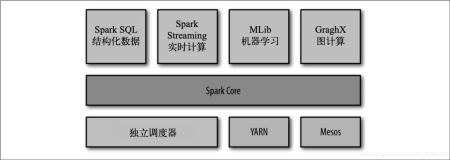
Spark是一个由加州大学伯克利分校(UC Berkeley AMP)开发的一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient distributed datasets),提供了比Hadoop更加丰富的MapReduce模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图计算算法。
Spark使用Scala开发,使用Mesos作为底层的调度框架,可以和hadoop和Ec2紧密集成,直接读取hdfs或S3的文件进行计算,并把结果写回hdfs或S3,是Hadoop和Amazon云计算生态圈的一部分。
Spark的第一个版本是2011年5月份发布,到如今已经1年。去年下半年有段时间国内比较活跃,豆瓣基于它克隆了一个DPark,但是不支持hdfs的读取,后来又沉寂下去。原因之一是0.4版本的Spark,基于的mesos版本太低,稳定性不足,而本身也尚未成熟,一旦部署会发现颇多问题。经过半年的开发者不断努力,昨天(6月12日)发布的0.5.0正式版本,有了不小的提升,而且基于的mesos版本也升级为0.9正式版,稳定性可以支持生产级别。
有鉴于此,开始将最近研究的一些心得,分成几个随谈系列发布,希望对Spark在业界的应用,有良好的促进作用,为基于大数据的快速数据挖掘,提供多一种优秀的解决方案。
随谈分成6个部分
一、总体框架
二、安装攻略
三、开发指南
四、寻找Scala语法糖
五、核心RDD模型之妙
六、链式MapReduce模型的挖掘算法
本文来源于"阿里中间件团队播客",原文发表时间" 2012-06-13 "