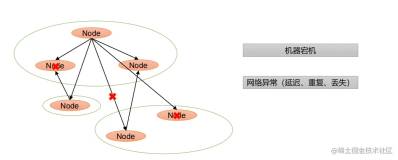
Master Slave (or Single Master)Model
Under this model, each data partition has a single master and multiple slaves.
All update requests has to go to the master where update is applied and then asynchronously propagated to the slaves. Notice that there is a time window of data lost if the master crashes before it propagate its update to any slaves, so some system will wait synchronously for the update to be propagated to at least one slave.
Read requests can go to any replicas if the client can tolerate some degree of data staleness. This is where the read workload is distributed among many replicas. If the client cannot tolerate staleness for certain data, it also need to go to the master.
Master Slave model works very well in general when the application has a high read/write ratio. It also works very well when the update happens evenly in the key range. So it is the predominant model of data replication.
主从模式, 最传统和简单的模式
写操作, 所有写操作通过master, master写成功即返回, 然后master负责异步propagate到各个slave节点. 为了增强可靠性, 也可以等master至少propagate一个slave后再返回.
读操作, 如果可以容忍旧数据, 从任一节点读. 如果不能容忍, 所有读操作也要通过master
缺点, 单点问题, 以及master负载过重
解决办法, 参考Google的设计, GFS, Bigtable
去中心化的方案, Quorum Based 2PC
由于主从模式比较成熟和简单
对于分布式的场景, 去中心化的设计(无固定master), 如何保证一致性? 这才是近年来, 研究的难点和热点
JimGray在“Notes on Database Operating Systems” (1979)中描述了两阶段提交(2PC)
二阶段提交(2PC)协议
传统的2PC协议用于保证分布式事务的原子性, 分布式存放的数据, 必须要保证同时更新成功或失败.
所以coordinator必须在第一阶段, 发送prepare请求保证所有的数据复本当前都是ready for update, 在得到所有复本回应后再开始第二阶段, 正真的commit
这里就比基于master复杂, 不是仅仅master同意, 而是要所有的node都同意, 才能commit
To provide "strict consistency", we can use a traditional 2PC protocol to bring all replicas to the same state at every update.
Lets say there is N replicas for a data.
When the data is update, there is a "prepare" phase where the coordinator ask every replica to confirm whether each of them is ready to perform the update.
Each of the replica will then write the data to a log file and when success, respond to the coordinator.
After gathering all replicas responses positively, the coordinator will initiate the second "commit" phaseand then ask every replicas to commit.
Each replica then write another log entry to confirm the update.
Notice that there are some scalability issue as the coordinator need to "synchronously" wait for quite a lot of back and forth network roundtrip and disk I/O to complete.
On the other hand, if any one of the replica crashes, the update will be unsuccessful. As there are more replicas, chance of having one of them increases. Therefore, replication is hurting the availability rather than helping. This make traditional 2PC not a popular choice for high throughput transactional system.
2PC协议的最大的问题是没有考虑节点fail的case, 任意的节点的fail都会导致block.
Dale Skeen在“NonBlocking Commit Protocols” (1981)中指出,对于一个分布式系统, 需要3阶段的提交算法来避免2PC中的阻塞(block)问题, 但问题关键很难找到一个好的3PC算法
对于阻塞问题, 其实想当然的是可用通过timeout来解决, 当然问题没有那么简单,
问题的核心在于,你无法区分一个进程到底是终止了还是正在以极低的速度执行,这使得在异步系统中的错误处理几乎是不可能的
Fischer, Lynch 和 Paterson在"Impossibility of distributed consensus with one faulty process” (1985) 中证明了这一点
对于一个异步系统来说即使只有一个进程出错,分布式一致性也是不可能达到的,这就是著名的FLP结论
人们意识到一个分布式算法具有两个属性: 安全性(safety)和活性(liveness), 2PC极具安全性,却缺乏活性
在1986年的会议上, 分布式事务被认为是一个新的一致性问题,称为uniform consensus (参见“Uniform consensus is harder than consensus” (2000))
With uniform consensus all processes must agree on a value, even the faulty ones - a transaction should only commit if all RMs are prepared to commit. Most forms of consensus are only concerned with having the non-faulty processes agree. Uniform consensus is more difficult than general consensus.
个人理解, 在节点或进程失效的时候, 仍然可以达成一致性, 而不会存在2PC的block的情况
Paxos, quorum based 2PC
最终Lamport在“The Part-Time Parliament” (submitted in 1990, published 1998)中提出了Paxos一致性算法, 后来Lamport又发表了“Paxos Made Simple (2001).
用于解决uniform consensus的问题.
Paxos的核心, 在于quorum based 2PC, 在分布式环境既然无法要求所有节点能够正常响应
那么Paxos只需要majority(多数派)正常响应, 就可以达成一致性决议, 从而避免任一节点fail导致的block
但问题在于, 那些没有响应的节点(因为fail或网络等原因)怎样保证其一致性?
答案是, 任何一致性决议的达成都需要majority的accept, 任意两个majority集合都一定有交集(至少一个节点)
而任一节点都只能accept一次proposal(除非具有相同的value), 所以当一个一致性决议达成的情况下, 不可能有不同value新决议被达成(即使在部分节点fail的情况下)
从而即使fail的节点wake-up后, 仍然可以简单的从其他majority节点learn并保证一致性
这就是为什么叫quorum based 2PC, 其实本质就是 R +W > N
并且在一段时间内无法获得majority的响应时, 可以随时主动放弃现有提案, 并提出更高编号的提案, 进一步避免block
传统2PC只是Paxos的一种特殊case (当W = N and R = 1)
A more efficient way is to use the quorum based 2PC (e.g. PAXOS).
In this model, the coordinator only need to update W replicas (rather than all N replicas) synchronously. The coordinator still write to all the N replicas but only wait for positive acknowledgment for any W of the N to confirm. This is much more efficient from a probabilistic standpoint.
As you can see, the quorum based 2PC can be considered as a general 2PC protocol where the traditional 2PC is a special case where W = N and R = 1. The general quorum-based model allow us to pick W and R according to our tradeoff decisions between read and write workload ratio.
本文章摘自博客园,原文发布日期:2013-04-03