大家可能对关系型计算比较陌生,但是对结构化查询语言(SQL)比较熟悉,SQL被广泛用于关系型数据的查询和处理,它能告诉数据引擎完成什么样的计算,而不是如何完成这些计算。离线的意思是数据一旦进入系统就不会被改变,数据写入的过程中也不会被读取,读取的过程中也不会被删除。实际应用中,离线场景会极大地降低系统实现难度。
关系型计算基本原理
关系型计算是由行、列两个维度组成的二维数据,每行都包含所有列的数据且对应列的数据类型都相同,主要的计算包括纵向切、横向切、聚合、连接、窗口以及集合运算。聚合计算一般情况下会先按照不同的值分组,然后再在每一组上计算结果。关于如何定义窗口,比较重要的三个要素是:如何将整个数据集分组?在组内数据如何排序?在组内数据如何计算?
逻辑查询计划和SQL
前面介绍了关系型计算的几种常见操作,这些操作组织起来构成的操作序列可以理解为逻辑查询计划。比如要获取各个不同年龄段、不同性别的用户在各个类目的消费总额统计,消费总额少于10000¥的除外。为了完成这个目标,我们首先需要纵向切Users表,切出来{ID, Age, Gender},纵向切Orders表,切出来{UserID, Cost, Category}。然后根据Users.ID = Orders.UserID的原则将这两个表连接起来,再按照年龄段、性别、类目聚合出消费总额,最后横向切,留下消费总额大于10000¥的行。
逻辑查询计划有特定的查询方式,最典型的是SQL。SQL是一种描述逻辑执行计划的方法,它提供了各种“语法糖”和“语义糖”。SQL的计算顺序可以参考网站:http://en.wikipedia.org/wiki/Select_(SQL)#Query_evaluation_ANSI。
例如如下SQL:
SELECT GetAgeGroup(u.Age) AgeGroup, u.Gender, o.Category, SUM(Cost) TotalCost
FROM
Users u
INNER JOIN
Orders o
ON u.ID = o.UserID
GROUP BY GetAgeGroup(u.Age), u.Gender, o.Category
HAVING SUM(Cost) > 10000;其计算顺序是:
1、<from>子句
对于本例来说是连接。Users u INNER JOIN Orders o ON u.ID = o.UserID。
2、<where>子句,对应的是横向切,本例中没有
3、聚合
首先,按照<group by>子句指定的方式对数据集分组;然后为每一组数据,计算出一个聚合结果;最后,聚合的输出是<group by>子句中的每一项和聚合函数计算结果。
4、<having>子句,HAVING SUM(Cost) > 10000。
5、生成<select list>,GetAgeGroup(u.Age) AgeGroup, u.Gender, o.Category, SUM(Cost) TotalCost。
物理查询计划
物理查询计划,根据数据分布、执行引擎特性/状态、逻辑查询计划的计算逻辑生成的在指定执行引擎上的计算逻辑。比如:
- 算法选择,对于连接来说,有三种不同的算法,完全无序的两个数据集,一个很大一个很小,此时选择HashJOIN;若两个数据集都很大且有序,则使用MergeJoin更有效;如果两个数据集一大一小做连接,大表已经排序,则使用NestedLoop更有效。
- 计算顺序选择,改变inner JOIN的顺序会不会更快?
- 在传统关系型数据库上,Users表和Oders表是否有索引?数据按照什么分块?
- 分布式文件系统中,Users表和Oders表的存储有什么特点?数据量分别有多大?
- 分布式系统上,需要Shuffle吗?Shuffle谁?如何Shuffle?
- 系统负载情况?为此我们要优化吞吐量还是执行时间?
- 执行引擎是基于文件系统还是内存加网络?
- 作业调度系统有哪些特性?
关系型计算本身的计算不需要迭代,总是可以拆分到独立的相互隔离的计算节点上去并行执行。根据算法不同的要求,数据可能会需要在集群当中重新Shuffle和重新Sort。实际上用到很多计算机构成的集群计算,Shuffle和Sort是计算核心。
数据在什么地方,以什么方式存在,集群当中每台计算机的负载状况,对计算机开销的预期,包括CPU、内存、IO等,计算结果的输出方式,这些都会影响集群作业调度系统如何去调度这些作业。
分布式环境中的连接计算
案例1:1TB的“产品表”和3TB的“订单详情表”在产品ID上的连接。
假设“产品表”分布在17台计算机上,“订单详情表”分布在60台计算机上,数据分布没有特点(不能根据数据本身计算出数据在哪个机器上),随机。拆分的计算节点越多,单个节点完成的速度越快,failover成本越低;但是计算节点越多,调度成本越高,调度的轮次也会越多。为了在计算时间和调度开销之间达到平衡,我们设置每个计算节点一次最多处理256M数据。对于这种数据场景,一般选择Mergejoin,通过Shuffle把来自“产品表”、“订单详情表”相同的ID分到一台机器上去计算。然后通过sort,使进入Mergejoin算子的数据满足Mergejoin需要的排序要求。这样的话,它实际上会生成三个不同的Task,Task和Task之间的边界可以理解成进程边界,进程可能在同一台服务器上,也可能在不同的服务器上。一般情况下,我们划分进程边界就是只看要不要在集群上重新分布数据。
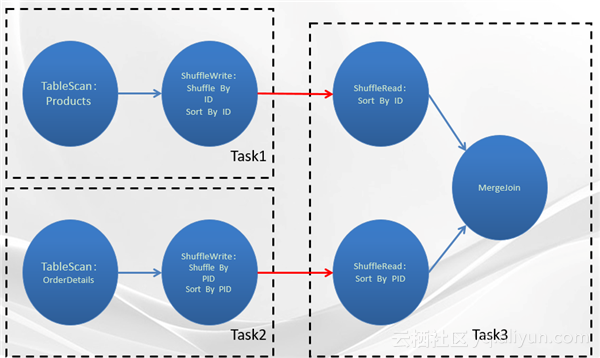
Task1它是去扫描“产品表”,然后它在ShuffleWrite operate里面Shuffle By ID、Sort By ID。这只是它逻辑上完成的工作。真正在物理上的执行方式可能是首先按照ID分片,然后对每一片去做外部排序,然后排序完成之后再把每一片的结果写到DFS上(分布式文件系统)。另外一种方式是首先做完全部的排序工作,然后再来分片。这两种方式在执行上的不同在于:一部分是全局有序,一部分是片内有序,实际上它带来的算法复杂度是完全不同的。
Task2和Task1类似, Task2扫描的是“订单详情表”,它同样是按照products ID去做Shuffle和Sort,Shuffle过后相同的ID会在同样的执行Task3的服务器上。并且因为我们前面做了Sort,那么输入到Mergejoin当中的数据实际上已经是按产品ID排过序的,后面就是标准的Mergejoin算法。
在Task3中,ShuffleRead做的是归并排序的操作。因为Task1和Task2很可能会有很多的instance,对于products表Shuffle出来的数据,如果Task1有10个instance,Task2有11个instance的话,那么Task3上面的ShuffleRead实际上要做10路的归并排序,下面的ShuffleRead它要做11路的归并排序。
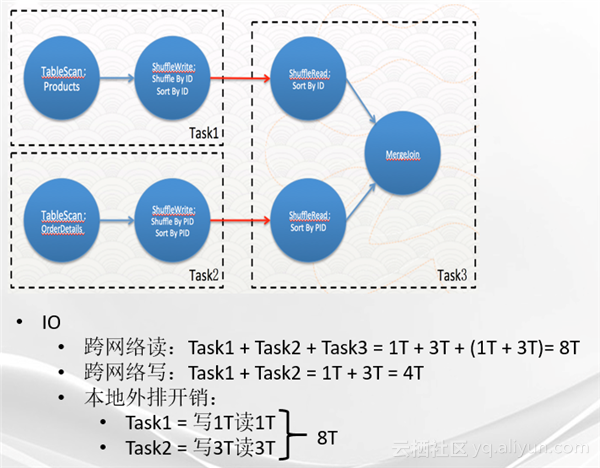
关于它的IO开销,首先看一下跨网络读,因为对于Task1来说,products表本身也是分布在很多的机器上的,用最坏的方式估计,假设所有的读全都是远程读,Task2也同理。Task3读取的数据量是Task1和Task2写给Task3的数据量的总和所以最后计算出来是8个T。跨网络写只有Task1和Task2,写出去的数据量就是他们Shuffle的数据量,大概是4个T。本地的外部排序的开销, Task1
写了1T,读了1T,Task2写了3T,读了3T,加到一起得到本地外排的开销是8个T。可以看出,本地外排的开销已经很接近于跨网络的IO,所以说外排在分布式系统当中也是一个巨大的开销。
案例2:2TB的“订单表”和100K的“省份表”在省份ID上连接。
使用的计算方式读取“省份表”并且把“省份表”向每一份读取“订单表”的worker去广播,后用“省份表”的数据去建立一张Hash表。然后用Hash算法去处理“订单表”的每一条数据。Task1实际上只有一个instances,Task2的instances数量是2TB除以256M。IO开销:跨网络读为2TB,跨网络写只有Task1的400M,没有本地的开销。HashJoin的算法的特别之处在于使用province表去建立Hash表非常的容易。
案例3:2TB的“订单表”和100GB的“用户表”在用户ID上去做连接。
如果我们用最开始的Mergejoin的算法的话,需要把2TB的“订单表”去Shuffle Sort一次,把100GB的表也Shuffle Sort一次。本地IO的开销感觉非常的吃亏。解决办法是像Mergejoin那样按照用户ID去Shuffle一次,但是不去做外排,即后面使用HashJoin算法(Shuffle HashJoin)。生成的物理查询计划如下图所示:
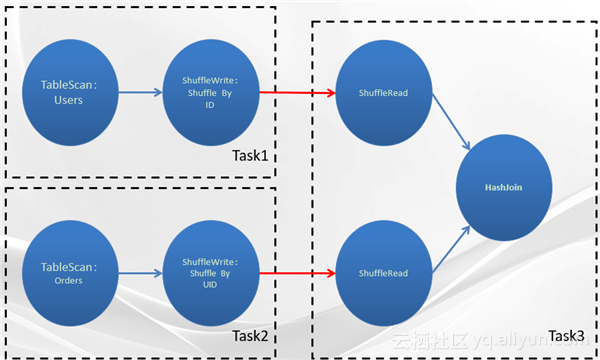
Task1把Users表按照ID去Shuffle一次,Task2把Orders表按照Users ID也去Shuffle一次。Instance数量,Task1是100G/256M,Task2是2TB/256M。跨网络读约等于4TB,跨网络写是2TB,没有本地开销。
案例4:2TB的“订单表”和100GB的“用户表”在用户ID上连接,再和40GB的“卖家表”在卖家ID上去连接。
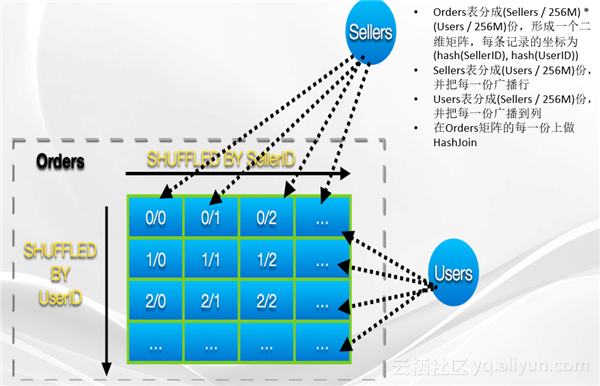
用Mergejoin,因为存在排序,从本地IO上讲很亏。用HashJoin算法,100GB数据内存放不下。如果用Shuffle HashJoin,网络上Shuffle的数据量过于大。解法很类似,保证最大的那张表只Shuffle一次。首先把Orders表分成Sellers表除以256M那么多份,然后再乘上Users表除以256M那么多份,然后它会形成一个二乘二的矩阵。这一次的Shuffle要把Orders表分成一个矩阵,行是Users ID,列是Sellers ID,行数是Users除以256M份,列是Sellers除以256M份。然后再来把Sellers表分成Users除以256M份,并且把其中的每一份广播到Orders所对应的每一行上。然后再把Users表分成Sellers除以256M份,然后再广播到Orders表的每一列上。然后在每一个矩阵上就可以做HashJoin了。它的做法的出发点是通过聚融于Sellers表和Users表来避免这张大的Orders表被多次Shuffle。
我们在前面的计算过程当中,可以看到我们重度依赖Shuffle,但是Shuffle可能造成数据长尾,如极少数大店的订单数量会远远高于一般店铺,这时计算Orders和Shops在ShopID上的连接会出现绝大多数instance已经计算完成,剩下的几个instance由于处理的数据量太大,执行时间过长。一个可能的解法:把这些店铺的数据单独取出来,通过HashJoin单独计算;然后合并到其他。
分布式环境中的聚合计算
计算每个买家的订单数量,数据特点:买家众多,内存远远装载不下;每个买家订单数量都不多,换句话说Buyer字段在Orders表中的选择度很高。一个可能的解法是这样,我们先扫描Orders表,然后我们按照Buyer这个字段去做Shuffle跟Sort,达到的效果是相同买家的数据全部都到了一台机器上,并且它是按照买家有序的。这样我们在Task2当中,按照Buyer去排序,然后后面基于流做一个聚合。Streamed Aggregate的输入是按照Buyer有序的。我们就会产生一条关于买家A的订单数量的记录,再去计算买家B、买家C等等。
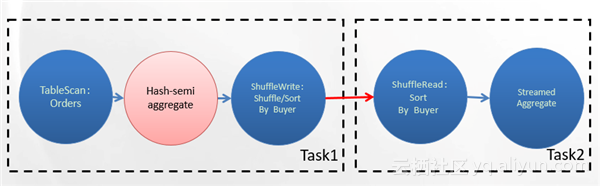
Task1跟Task2之间Shuffle的数据量的IO是整个Orders表的IO,相当浪费,优化办法是先做一次本地的聚合,往Task2 Shuffle数据的时候只要Shuffle这一份上买家和这个买家的订单数量即可。具体的做法是在Orders表的TableScan后面补一个Hash-semi aggregate,然后再去做Shuffle Write。Hash-semi aggregate做的工作大概的流程是这样:维护一张哈希表,{key : Buyer,value : Partial Result};一条记录过来首先查找哈希表,找到了的话在Partial Result上继续聚合;没找到插入之,并用1来初始化Partial Result;如果哈希表达到了上限,输出哈希表的10%(经验数字);TableScan Operator处理完当前分片,输出整个哈希表。streamed Aggregate在Partial Result的基础上去计算出来Final Result。
计算每个类目的订单数量。数据特点:Category个数有限,内存完全放得下;每个Category订单数量都很庞大,Category字段在Orders表中的选择度很低。解法和上例当中唯一的不同在于我们用Hash aggregate来代替掉了Hash-semi aggregate。
计算每个类目的买家和卖家数量。数据特点:Category个数有限;买家/卖家数量很多,内存放不下;甚至一个Category下的买家/卖家内存也放不下;买家会在多个Category下买入商品;每个Category买家/卖家数量差距会很大,汽车VS服装…
针对这样的数据特点,第一种解法就是我们先求买家数量,再把卖家数量求出来,以Category为key,做个连接来形成最终的结果。这种解法,Orders表被读了2次——尽管在执行代码上可以优化;Category在Streamline上被shuffle了两次;连接是比较重的算法,计算开销相对较大;如果Category的选择度没有那么低,那么连接的开销会很不可忽略;没有解有些Category数据倾斜的问题,长尾。
解法2是利用聚合函数输入参数为NULL会忽略当前行计算的定义,“膨胀”数据,再聚合。先去扫描Orders表,然后在Hash aggregate的时候,分成两步做,第一步先去膨胀,然后以Category Buyer和Seller为key去去重,然后后面再去Shuffle,Shuffle的顺序是按照Category,然后Sort是按照Category、Buyer和Seller去做。这种解法,Orders表只被读了1次;Category在Streamline上被shuffle了1次;没有连接;没有解Category数据倾斜的问题。
解法3中间多加一次Shuffle和Sort,我们在Shuffle的时候是按照Category Buyer和Seller去做Shuffle,这样的话我们能保证相同的Category Buyer和Seller的数据会到Task2的一个instance上去。然后我们再按用streamed的aggregate去在Task2当中去重。这种解法,Orders表只被读了1次;多了一次Shuffle-Sort,Category因此被shuffle了2次,占用了集群额外资源(单条查询执行时间 VS 集群吞吐量);没有连接;没有显著长尾。对于解法3来说,在大多数情况下我们会加速单条查询的执行时间,但是我们实际上损害了集群的吞吐量,在集群负载很高的时候,多这一次Shuffle实际上对于集群的运算能力是一种损害。
其他计算和物理优化
窗口函数的计算
窗口函数(Window Function)要素:如何将数据集分窗口——如何Shuffle;窗口内数据按照什么排序——如何Sort;在窗口上如何计算。
优化考虑
IO是主要目标。减少Shuffle的数据量;避免不必要的Shuffle-Sort,每一个Physical Operator都有Shuffle-Sort属性,如果一个Operator的输入“兼容”它的计算需求,就可以不去Shuffle或Sort。
单条查询的执行速度 VS 集群吞吐量。长尾。
典型物理优化
- A JOIN B ON A.ID = B.ID GROUP BY A.ID
- JOIN Reorder
A JOIN B ON A.ID = B.ID
JOIN C ON A.City = C.City
JOIN D ON A.ID = D.ID
- 列存储 & Column Pruning
- Predicate Push-down
- Partition Pruning
工程方案
基于开销的优化:如果有数据分布,就会知道使Shuffle By {a, b}降级成Shuffle By {a}会不会造成长尾;如果有数据分布,就会知道作为JOIN的输入数据量,从而选择是否做HashJOIN,做什么样的HashJOIN。
工程现实:海量的作业 + 海量的数据。极少有大型作业在一次处理海量的数据;存储是瓶颈,CPU不是用户作业时间比较敏感,集群吞吐量退居其次。
执行引擎实现细节的改进:SQL计算逻辑大多是按行计算,但是只引用固定的列,如值函数;所以一切优化都围绕着SIMD走;Single Instruction Multiple Data,单指令多数据;内存中的列存储。
其他优化
查询计划缓存:用户每天提交的作业,除了常数参数不同,其他都相同。
提取公共计算: 用户会提交一系列的查询用以完成一连串的需求,一次处理一整批SQL,更广范围的源表合并,甚至有一些维度表可以直接加载到集群内存,更小的调度系统开销。