
来自阿里云IDST褚崴为大家带来分布式机器学习平台方面的内容,主要从大数据的特点和潜在价值开始讲起,然后介绍阿里的业务场景中常用到的机器学习算法,以及阿里采用的分布式机器学习框架,最后介绍了PAI算法平台,一起来看下吧。
大数据的特点和潜在价值
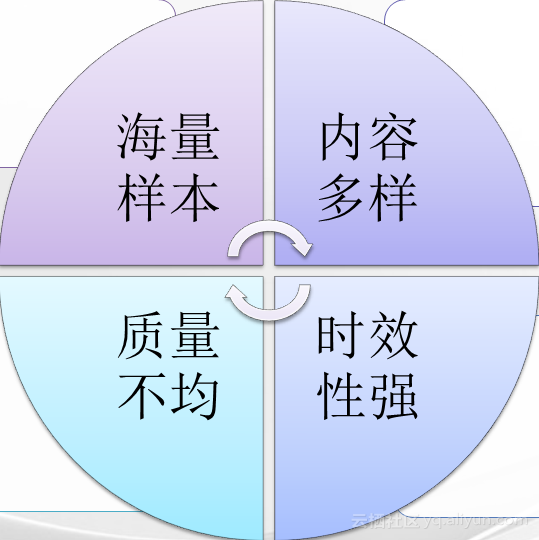
我们正在步入大数据的时代,大数据至少具备以下四个特点:
- 海量样本:数据的规模巨大,特征非常多,每40个月翻一番,数据管理复杂;
- 内容多样:非结构化数据、异质数据,每天产生的数据里有图像、语音、视频,还有各类传感器产生的数据,各种定位的信息,交易记录…
- 时效性强:数据实时更新,多突发事件,用户短期行为,要求实时检索和计算的能力;
- 质量不均:数据采集渠道多,质量参差不齐,数据分析准确性不一致。
大数据里蕴藏着丰富的知识,如何使大数据成为知识和力量?这是数据挖掘科学家的使命。
数据挖掘是由软件实现的机制从海量数据中提取出信息,数据挖掘方法又被称做算法,在海量样本里,我们可以更加准确地发现事件间的关联关系,对未知的事件有精准预测的能力,帮助我们做出更合理的决策。在电子商务领域,数据挖掘正在广泛地应用于精准营销、风险控制、成本管理等方方面面。
大数据挖掘的基础就是分布式的大规模机器学习的能力。阿里有7.6亿的商品,日均访问量10亿次,占C2C市场90%以上,占50%以上的B2C市场,占第三方支付的50%, 这些组成了阿里的大数据。目前,在阿里数据平台事业部的服务器上,攒下了超过100PB已处理过的数据,等于104857600个GB,相当于4万个西雅图中央图书馆,580亿本藏书。
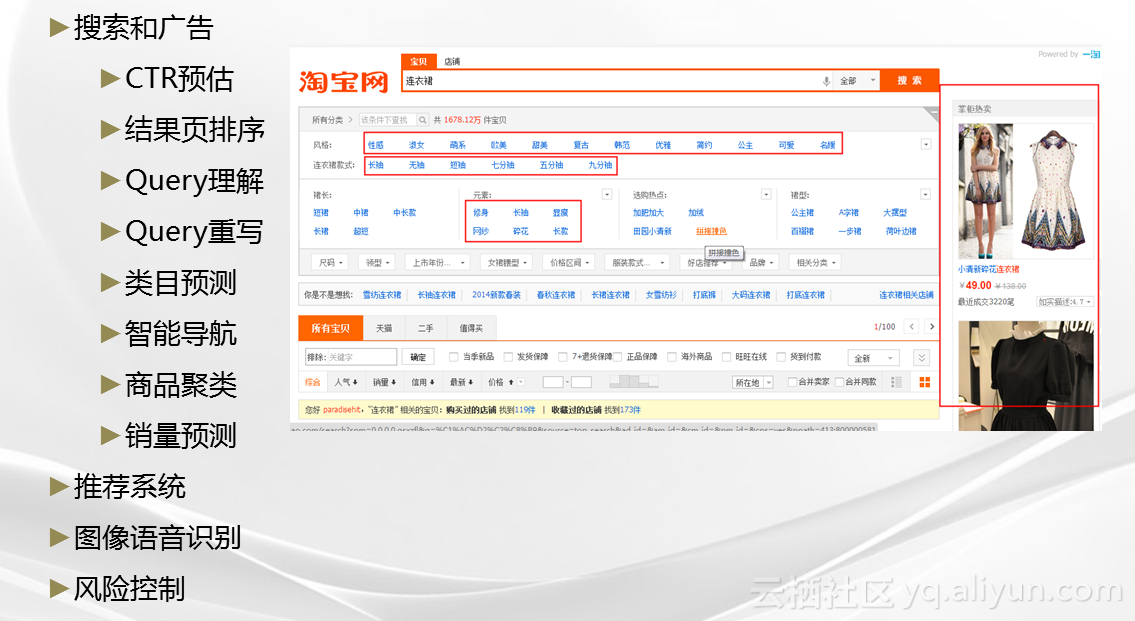
机器学习在阿里广泛地应用,在淘宝的主页上,搜索技术里的对搜索关健词的理解和重写、结果内容的排序、广告投放点击率的预估、商品的聚类和去重,还有相关商品的推荐技术等等;在蚂蚁金服的业务中,图像识别技术广泛应用到证件智能审核和人脸识别,规则挖掘技术也运用在风险控制上;在客服业务里,语音识别技术也得到广泛地应用。
机器学习算法
通常我们把机器学习的算法分为三大类:有监督学习、无监督学习和强化学习。
逻辑回归(Logistic Regression)
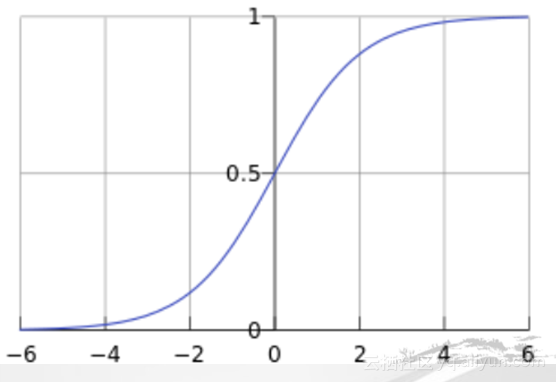
逻辑回归广泛地运用在二分类的问题,基于多个输入变量来估计某一事件发生的概率。在CTR预估的任务中,最常用到的线性逻辑回归的模型:
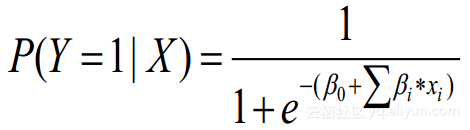
输入变量描述上下文,预估用户点击的概率。可以包含广告质量信息与搜索关键字的相关性,历史记录中的点击情况,以及用户的个人信息等等,利用日志中的上一次的历史事件学习一个线性模型来拟合用户的点击行为,这个线性模型的输出值通过一个logit model把一个实数映射到0~1之间,成为一个概率值,通常我们假定样本是互不相关的,利用极大似然法来优化线型模型的权重,根据具体情况我们还会加上正则项来获得相对更简单的模型,其他的多分类问题 (multiclass classification) 或 序数回归 (Ordinal Regression)也可以转化为二分类的问题来求解,所以逻辑回归适用范围非常广。
聚类(Clustering)
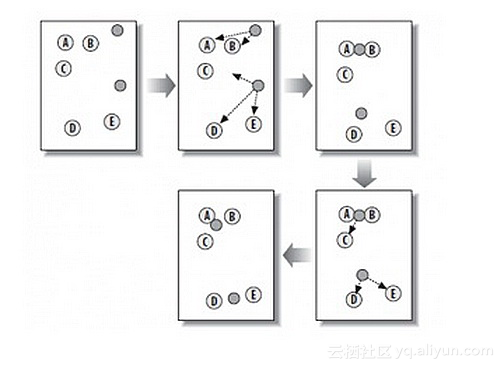
K-Means是一个常用的聚类算法,把样本按照空间位置划分成K个类,K事先设定目标是把空间位置相近的样本聚在同一个类里,样本可以是用户,也可以是商品或者照片等等,每个样本由一组特征来描述,我们通过损失目标函数最小化来优化每个聚类中的中心位置和各个样本的所属类,这个算法的大致过程如下:
初始化每个聚类的中心,可以随机的选K个样本作为中心,然后计算每个样本达到K个中心点的距离,距离可以是欧式空间距离,也可以是其它距离,每个样本选择距离最近的中心点作为该样本的所属类,之后根据该类里面所有样本来更新该类的中心点位置,可以就是样本的平均值,根据新的各类中心点位置再决定每个样本的归属类迭代,直到结果不再变化,这样我们最终获得了K个类,每个类里面都有很相似的样本。此外,还有其它的聚类算法,例如谱聚类和LDA等等。
决策树(Decision Tree)
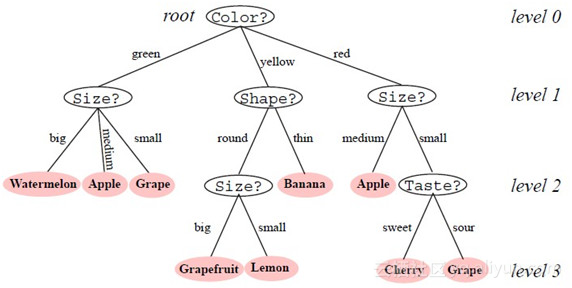
决策树是一种监督学习,给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,通过学习得到一个分类器,分类器能够对新出现的对象给出正确的分类,决策树是一种树型的结构,其中每个内部节点表示一个属性上的测试,每个分枝代表了一个测试输出,每一个叶节点代表一个类别特征和分类点,由信息熵的增益来决定。随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定,我们建立多棵决策树,各个决策树之间没有关联,分别学习部分训练样本而最终的结果由投票决定。
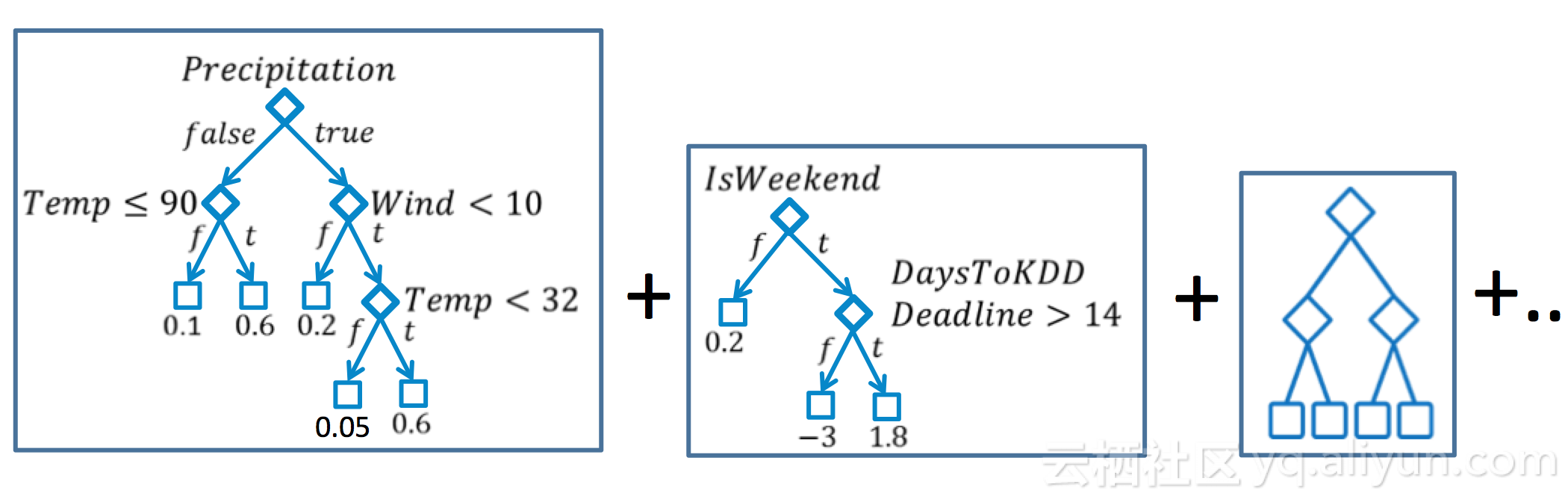
GBDT的全称是Gradient Boost Decision Tree,和随机森林一样,是由多棵决策树组成的,依次生成决策树,减小损失函数,各个决策树之间是有关联的,因为下一颗树是在现有模型的残差的基础上生成的,最终的结论由累加的各个决策树结果来决定。在生成一颗新树的时候,目标值设定为当前模型的梯度,然后按照常规的方法来建立决策树。
深度学习(Deep Learning)
深度学习核心是神经元网络模型,随着近年来并行分布式计算能力的发展,使得在海量数据上训练复杂模型成为了现实,实践也证明复杂的神经元网络模型在高难度的学习任务上表现优异,例如图像识别、语音识别、机器翻译等领域。
神经元网络模型包括一个输入层,由输入特征决定;一个输出层,由学习目标来决定;还有至少一个隐藏层,深度学习研究的模型一般都包含多个隐藏层,形成比较复杂的网络结构。
常用的网络结构有用于图像识别的CNN卷积神经元网络、用于语音和翻译的RNN、还有深度置信模型DBN,下面举例介绍CNN:
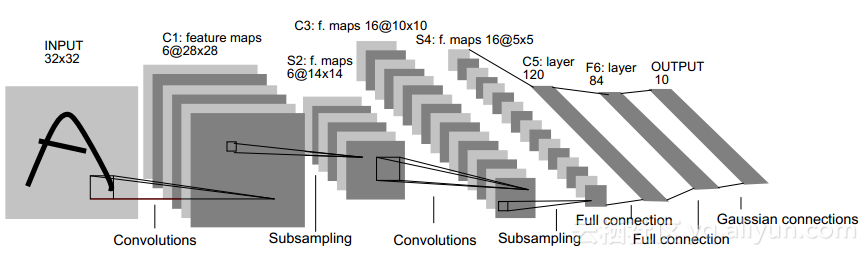
这是经典的LeNet5结构图,图中的卷积网络工作流程是,输入层有32乘32的感知节点组成,接受原始图像,然后计算流程在卷积和子抽样之间交替进行。第一个隐藏层进行卷积,它有八个特征映射组成,每个特征映射有28乘28的神经元组成,每一个神经元指定一个5乘5的接受域;第二个隐藏层实现子抽样和局部平均,它同样由8个特征映射而成,但每个特征映射由14乘14的神经元组成,每个神经元具有一个2乘2的接受域,一个可训练系数、一个可训练偏置和一个sigmoid激活函数,训练系数和偏置控制神经元的操作点;第三隐藏层进行第二次卷积,它有20个特征映射组成,每个特征映射由10乘10的神经元组成,该隐藏层中的每个神经元可以具有和下一个隐藏层几个特征映射相连的突触连接,它以与第一个卷积层的相似方式来操作;第四个隐藏层进行第二次子抽样和局部平均计算,它由20个特征映射组成,但每个特征映射由5乘5的神经元组成,它与第一次抽样相似的方式进行;第五个隐藏层实现卷积的最后阶段,它由120神经元组成,每个神经元指定一个5乘5的接受域,最后是一个全连接层,得到输出的向量。
常见的分布式机器学习框架
分布式机器学习的计算框架有两个,一是基于消息传播接口的MPI框架,一是参数服务器框架。
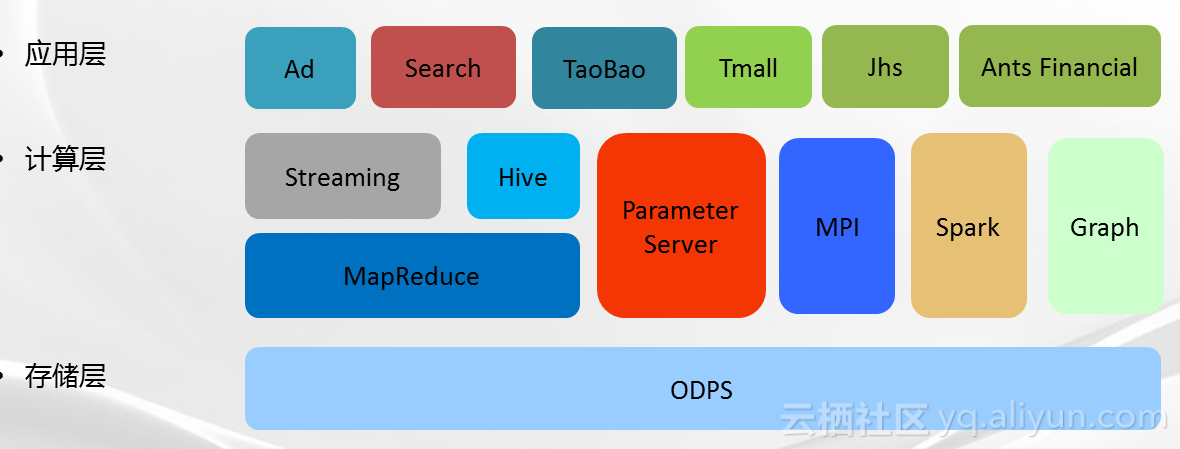
这是阿里的数据生态圈的示意图,底层的存储层是ODPS,中间层是计算层,搭载着MapReduce 、Spark、Graph还有MPI和参数服务器,最上层是应用层,支持阿里各个BU的业务,包括广告、搜索、淘宝、天猫、聚划算和蚂蚁金服。
Message Passing Interface(MPI)框架
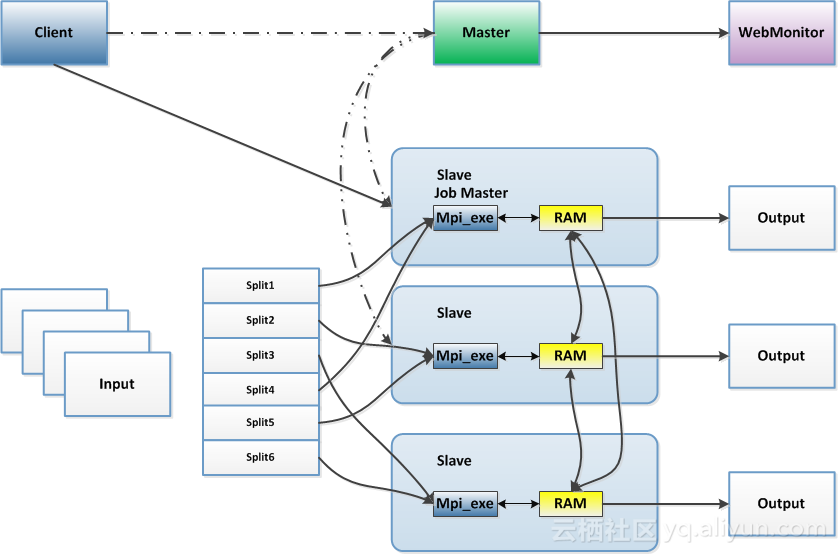
MPI是1994年5月发布的一种消息传播接口,它实际上是一个消息传播函数库的标准说明,吸收了众多消息传递系统的优点,是目前国际上最流行的并行编程环境之一。
MPI是一种标准,封装了消息传递编程接口、减少网络编程,MPI具有许多的优点:
具有可移植性和易用性,具有完备的异步通信功能,有正式和详细的精确定义。在基于MPI编程模型中,计算是由一个或多个彼此通过调用库函数进行消息收发通信的进程所组成,在绝大部分MPI实现中,一组固定的进程,在程序初始化的时候产生,一般情况下,一个处理器只生成一个进程,这些进程,可以执行相同或不同的程序,进程间的通信可以是点到点,也可以是集合的,MPI提供了一个并行环境库,通过调用MPI的库函数来达到并行的目的,目前流行的实现包括MPICH、OpenMPI和LamMPI,MPI提供C语言和FORTRAN等多语言的接口,支持迭代,支持ODPS平台,非常适合实现分布式机器学习算法。
上图是关于MapReduce数据分片,每个节点只处理一部分数据,通过增加处理节点,减少每个节点的计算工作量,从而完成大规模的数据处理任务,MPI框架支持节点间的通信,一般节点0就担当汇总的节点,推动其它节点,进行迭代计算的工作。
参数服务器(Parameter Server)框架
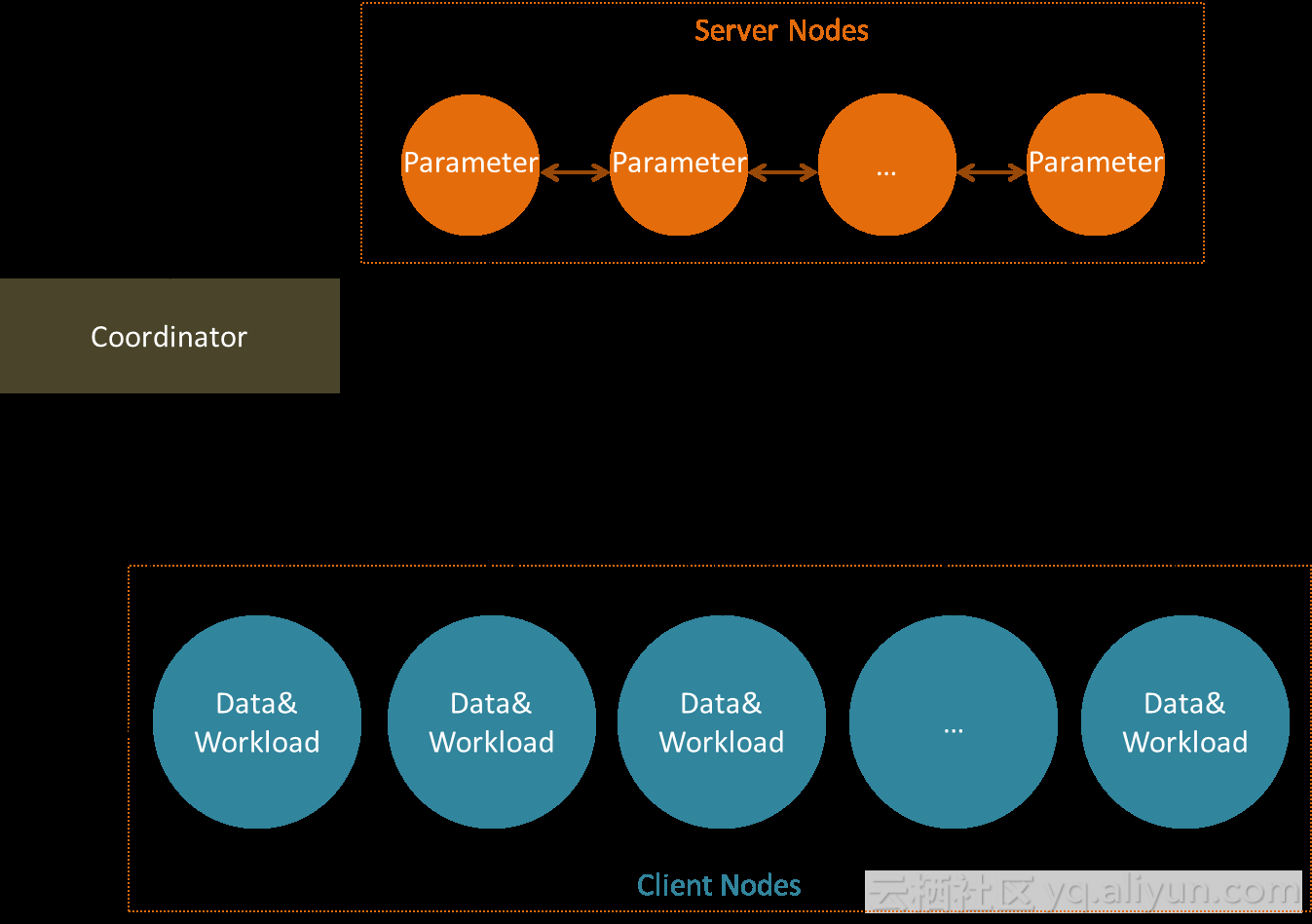
参数服务器是谷歌的一个大规模分布式计算平台,用来训练深度学习的模型。这个架构支持模型分片,可以把一个超大规模的模型分解成很多的小部分,一个参数服务器只负责模型的一小部分,可以通过增加参数服务器的数目来提升模型处理的规模;参数服务器利用稀疏特性减小通信。
在数据分片方面和MPI一样,可以通过增加节点来提升数据处理的规模,另外这个框架还支持异步迭代和Failover机制。框架会保存每一个节点的状态,当任何一个节点任务失败以后,框架会启动一个新的任务继续跑未跑完的任务。
K-Means 的分布式实现
MPI框架下具体过程如下:
1. 数据分片;
2. 节点0保存当时各个聚类的中心点的信息;
3. 每一个节点从节点0把当前各个聚类的中心点信息拉下来,然后计算每个样本到这些中心点的距离,根据最短的距离获得所属类,并累计本地的中心点信息,遍历所有的样本,将本地的中心点的信息推送到节点0;
4. 节点0收集到所有信息之后更新当前的各个类的中心点的信息,就是同步迭代;
5. 各个节点继续各自的计算,直到收敛,也就是各个中心点的位置不再变化。
当特征维度非常高的时候,节点0可能没有足够的内存资源来保存中心点的信息,而参数服务器正好可以解决这样的难题,参数服务器框架具体过程如下:
1. 首先模型分片;
2. 参数服务器分别保存当前类中心点的一部分特征维度;
3. 每一个节点从参数服务器上拉下来中心点的部分特征,累计每个样本到各个中心点的距离,再从参数服务器上拉下来另外一部分特征,继续计算到各个中心点的距离,直到得到完整的本地中心点的信息,之后将本地中心点的信息推送到参数服务器;
4. 参数服务器搜集到所有的信息之后,更新当前的各个类的中心点的信息,还是同步迭代;
5. 各个节点继续各自的计算,直到收敛。
PAI算法平台
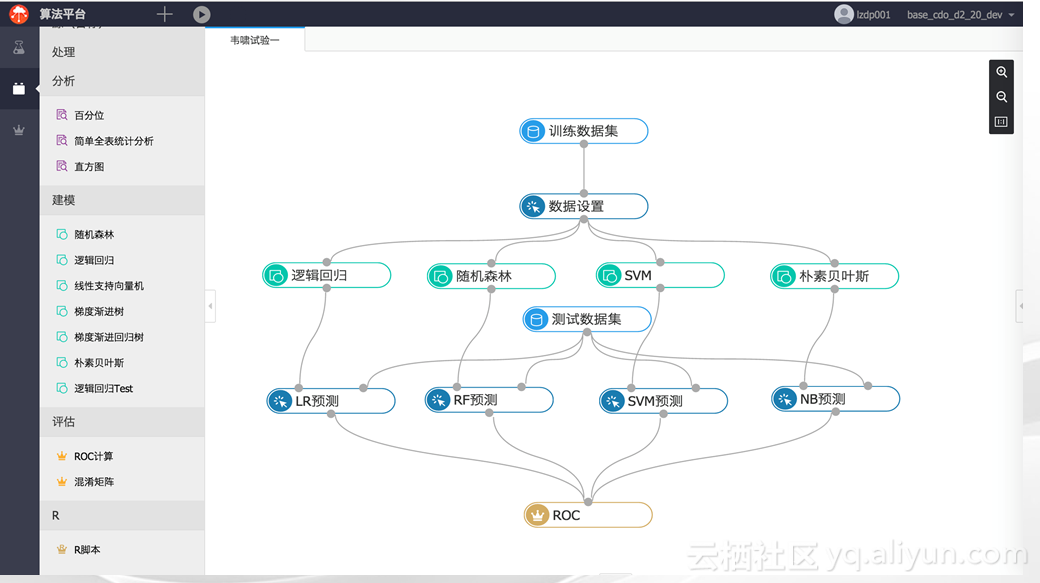
这是PAI算法平台的一个Snapshot,PAI算法平台将提供Web服务,支持拖拽的图形见面操作,在授权的基础上,所有的算法模块都可以共享,所有的实验记录都可以复用,我们希望营造一个算法的生态圈,每一个社区成员都可以分享他的实验设计和结果。
谢谢大家!





