1. 引言
Siri,Cortana,Google Now,小冰,度秘,随着技术的进步和自然人机交互需求的扩大,个人智能助理渐渐成了各大巨头争夺的下一个入口。这些智能助理尽管能力有大有小,但有一个共同特点——用户能通过“自然语言”与其交互,这比起传统的用关键词进行搜索的方式,显然是一个不小的进步。比如,当你说“订一张明天北京去杭州的机票,国航头等舱”时,一般的搜索引擎会给出如下的网页列表:
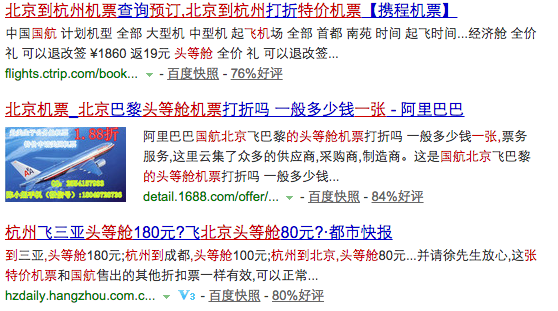
而我们的个人智能助理能直接给出你期望的答案:

要想从“订一张明天北京去杭州的机票,国航头等舱”得到这种直接答案,首要的一步就是要对自然语言进行理解。
自然语言理解(Natural Language Understanding,NLU)以语言学为基础,融合逻辑学、心理学和计算机科学等学科,试图解决以下问题:语言究竟是怎样组织起来传输信息的?人又是怎样从一连串的语言符号中获取信息的?换种表达就是,通过语法、语义、语用的分析,获取自然语言的语义表示。
2.自然语言语义表示
自然语言理解的结果,就是要获得一个语义表示(semantic representation):

语义表示主要有三种方式:
- 分布语义,Distributional semantics
- 框架语义,Frame semantics
- 模型论语义,Model-theoretic semantics
2.1 分布语义表示(Distributional semantics)
说distributional semantics大家比较陌生,但如果说word2vec估计大家都很熟悉,word2vec的vector就是一种distributional semantics。distributional semantics就是把语义表示成一个向量,它的理论基础来自于Harris的分布假设:语义相似的词出现在相似的语境中(Semantically similar words occur in similar contexts)。具体的计算方法有多种,比如LSA(Latent Semantic Analysis)、LDA(Latent Dirichlet Allocation)及各种神经网络模型(如LSTM)等。
这种方法的优点在于,它完全是数据驱动的方法,并且能够很好的表示语义,但一个很大的缺点在于,它的表示结果是一个整体,没有进一步的子结构。
2.2 框架语义表示(Frame semantics)
顾名思义,这种方法把语义用一个frame表示出来,比如我们一开始举得例子:“订一张明天北京去杭州的机票,国航头等舱”,表示如下:

在计算方法上,典型的比如语义角色标注(Semantic Role Labeling),具体可以分为两个步骤:frame identification和argument identification,frame identification用于确定frame的类型,argument identification用于计算各个属性的具体值。
这种方法和distributional semantics相比,能够表达丰富的结构。
2.3 模型论语义表示(Model-theoretic semantics)
模型轮语义表示的典型框架是把自然语言映射成逻辑表达式(logic form)。比如对于下图中的“中国面积最大的省份是哪个?”,将其表示成逻辑表达式就是图中红色字体部分,进一步那这个逻辑表达式去知识库中查询,就得到了答案。在计算方法上,典型的就是构建一个semantic parser。

模型论语义表示是对世界知识的完整表示,比前两种方法表达的语义更加完整,但是缺点是semantic parser的构建比较困难,这大大限制了该方法的应用。
2.4 我们目前采用的语义表示
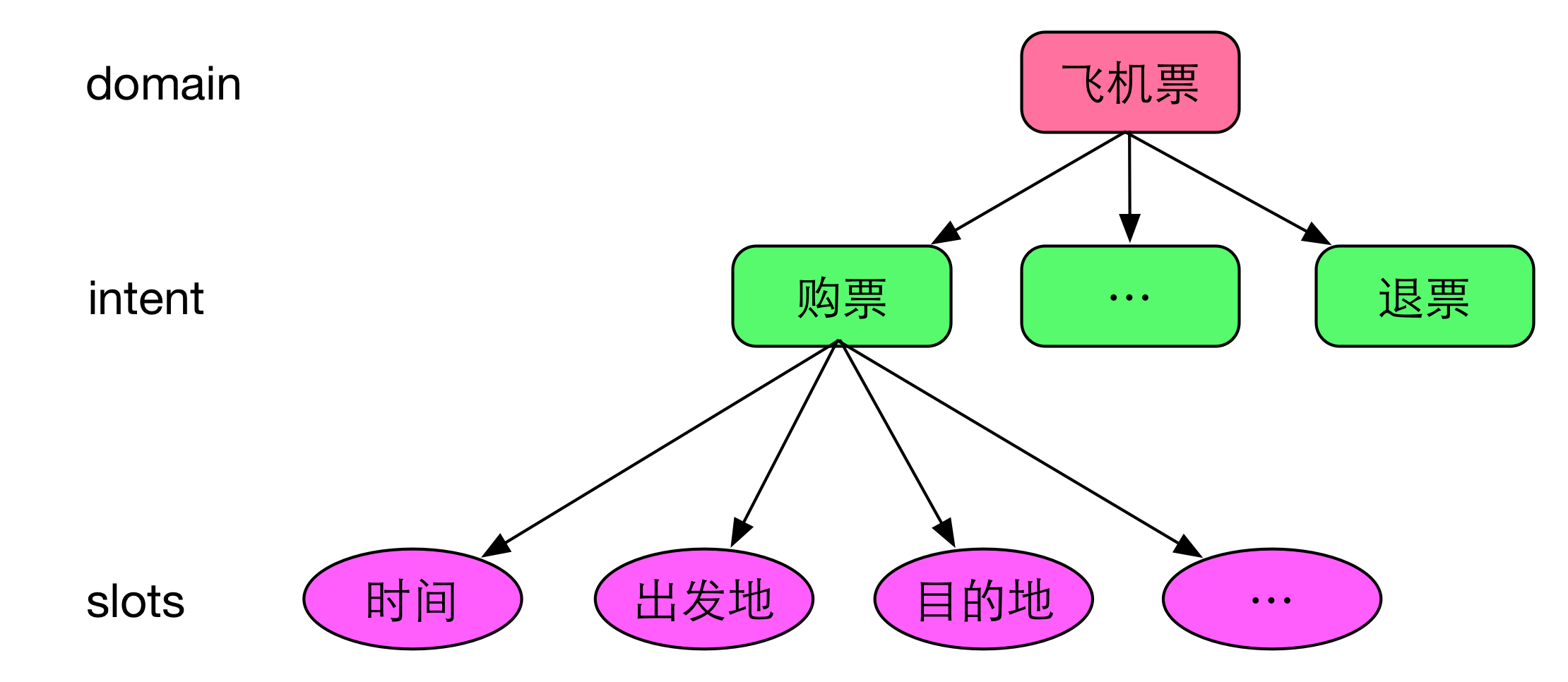
我们目前采用的是frame semantics表示的一种变形:采用领域(domain)、意图(intent)和属性槽(slots)来表示语义结果。其中,
- 领域是指同一类型的数据或者资源,以及围绕这些数据或资源提供的服务,比如“餐厅”,“酒店”,“飞机票”、“火车票”、“电话黄页”等;
- 意图是指对于领域数据的操作,一般以动宾短语来命名,比如飞机票领域中,有“购票”、“退票”等意图;
- 属性槽用来存放领域的属性,比如飞机票领域有“时间”“出发地”“目的地”等;
对于飞机票领域,我们的语义表示结构如下图所示:
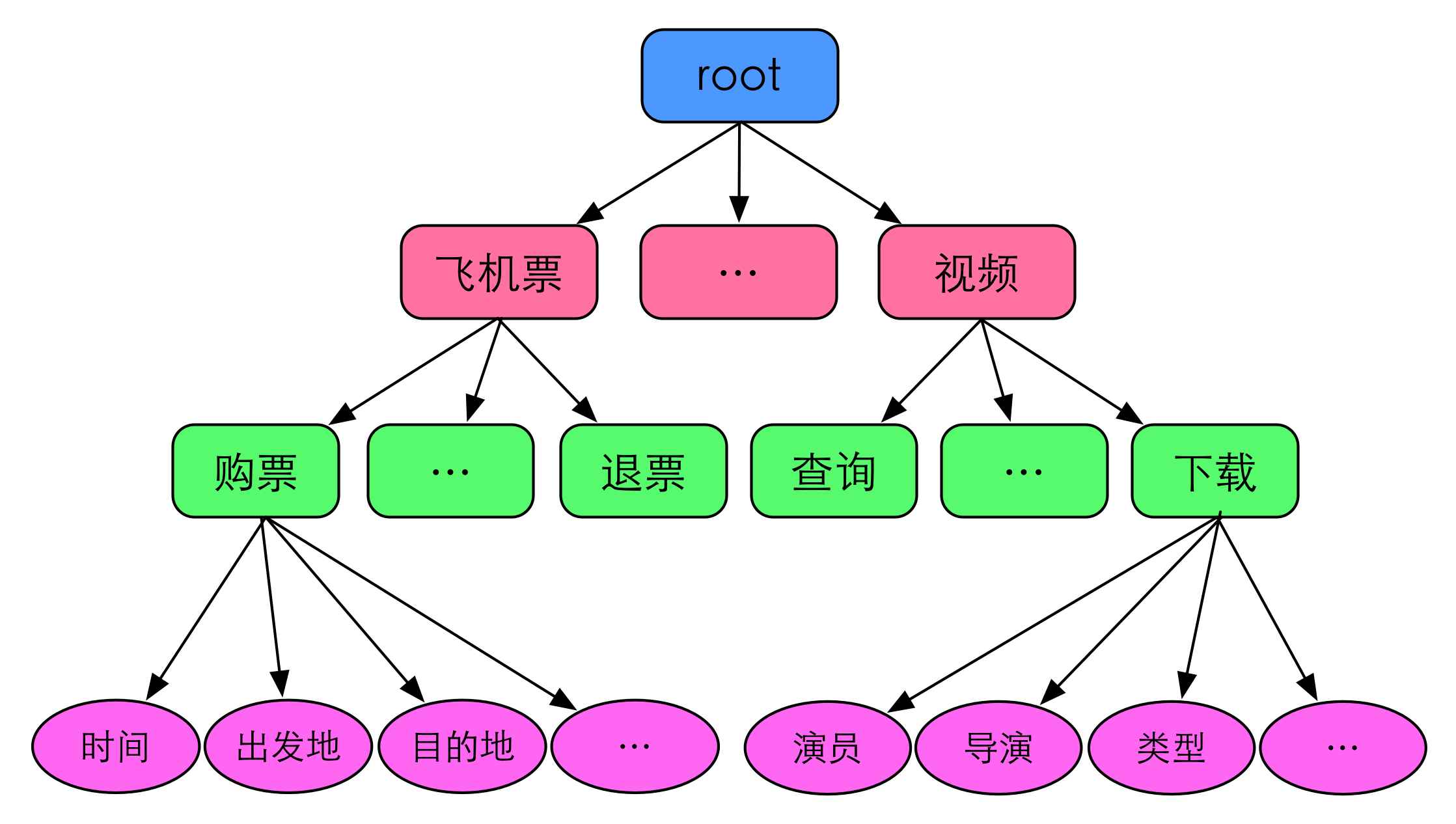
进一步,我们对于世界的语义描述(又称为domain ontology)如下:
3. 自然语言理解技术难点
在确定了自然语言理解的语义表示方法后,我们把技术方案抽象为如下两步:
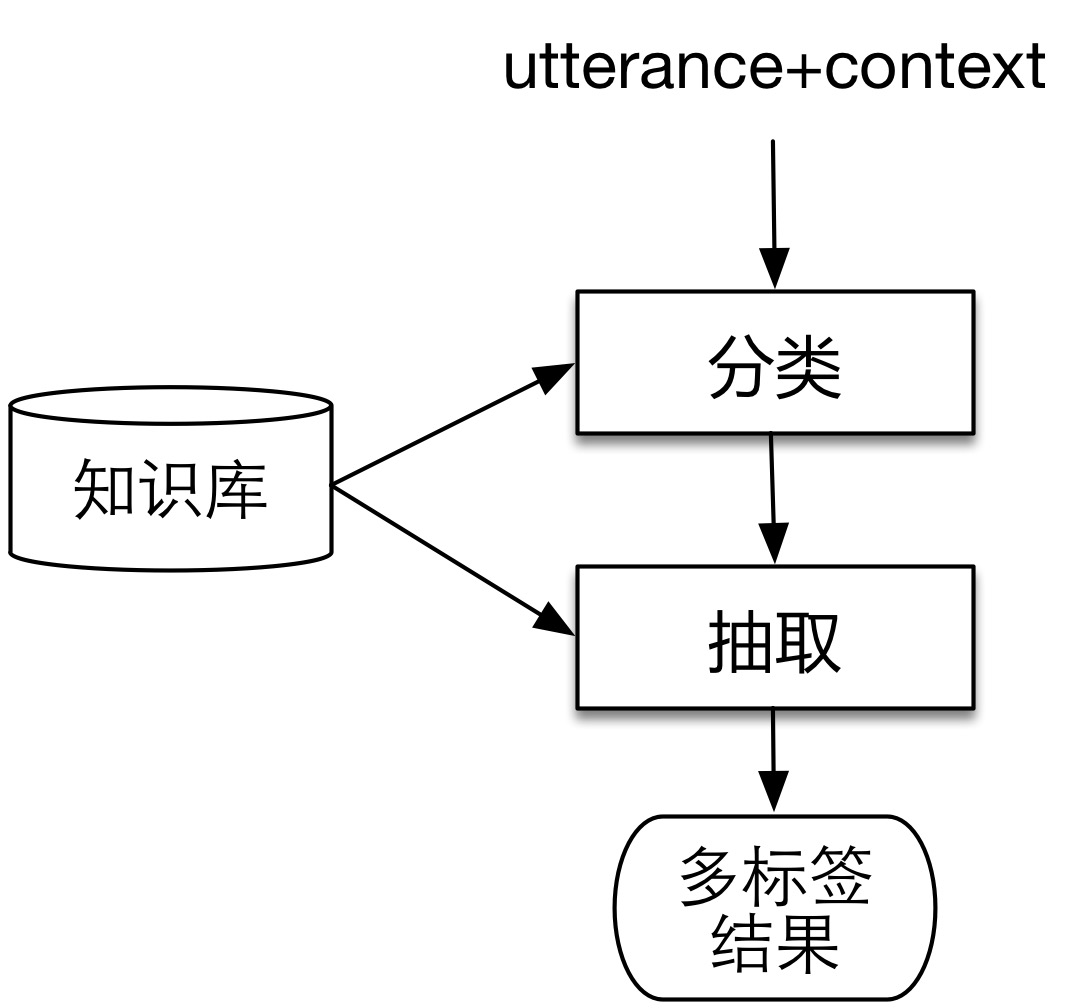
这和前文提到的语义角色标注把过程分为frame identification和argument identification类似,领域分类和意图分类对应frame identification,属性抽取对应argument identification。无论对于分类还是对于抽取来说,都需要有外部知识的支持。在实现的过程中,我们面临着如下的困难:
(1)如何构建知识库
“总参”除了表示总参谋部外,还是南京一家很火的火锅店;“中华冷面”除了是一种面条,还是一首歌名;“王菲的红豆”是指王菲唱的红豆这首歌,但如果说“韩红的红豆”就不对了,因为韩红没有唱过红豆这首歌。要想把这些知识都理解对,就需要一个庞大的知识库,这个知识库中的实体词数以千万计,怎么挖掘,怎么清洗噪音,都是很大的挑战。
(2)如何理解用户语句的意图
“东三环堵吗”这句话意图是查询路况,“下水道堵吗”就不是查路况了;“今天的天气”是想问天气状况,“今天的天气不错”则无此意;“附近哪儿可以喝咖啡”是想找咖啡馆,但“牛皮癣能喝咖啡吗”就是一个知识问答了。类似上述的例子举不胜举,更别说语言理解还受时间、位置、设备、语境等等问题的影响。
(3)如何构建可扩展的算法框架
现实世界包含众多的领域,而我们不可能一次性的把所有领域都定义清楚并且实现之,那我们就需要一个可扩展的算法框架,每当修改或者新增某个领域的时候,不会对其他领域造成干扰。
(4)如何构建数据驱动的计算流程
大数据时代,如果一个算法或者流程不是数据驱动的,不是随着数据的增加而自动提升效果,那这个算法框架就没有持续的生命力。
(5)如何融入上下文知识
在对话场景中,每句话都有对话上下文,同样的句子在不同的上下文中理解结果是不一样的,比如如下的例子,同样的一句话“今天天气好吗”在左侧图中属于天气领域,而在右侧图中则属于音乐领域。

4. 自然语言理解技术沉淀
技术难点的解决过程就是一个技术沉淀的过程。通过在自然语言理解方向上持续研究和开发,我们积累了如下的技术沉淀:
4.1 千万级的高质量知识库
知识库的核心节点是各种词,而这些词条散布在互联网上的各个地方。通过自己抓取和第三方合作的方式,我们拿到了大量的“毛数据”,这些数据中含有大量的噪音。为了过滤清洗这些数据,我们构建了一套集成了多种过滤方法的过滤流程来对这些数据进行处理。截止目前,我们积累了数千万的高质量的各种类型的词条。
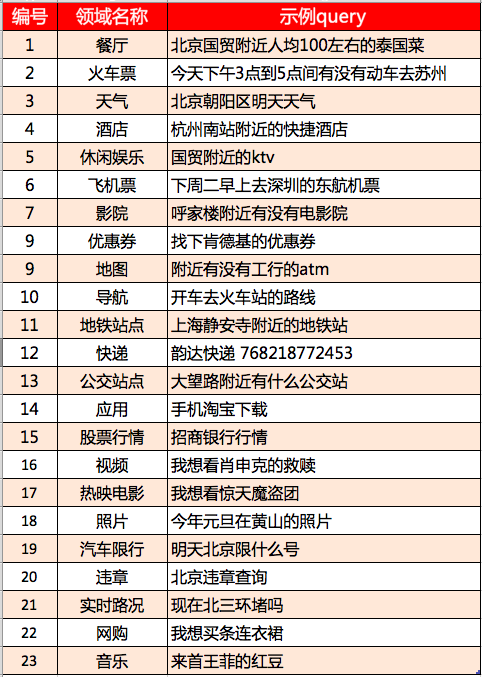
4.2 支持常见的数十个领域的理解
通过自然语言处理、机器学习、深度神经网络等算法和大数据的使用,目前我们理解的领域有60个左右,其中重要的一些领域如下:
4.3 一套可扩展的算法框架
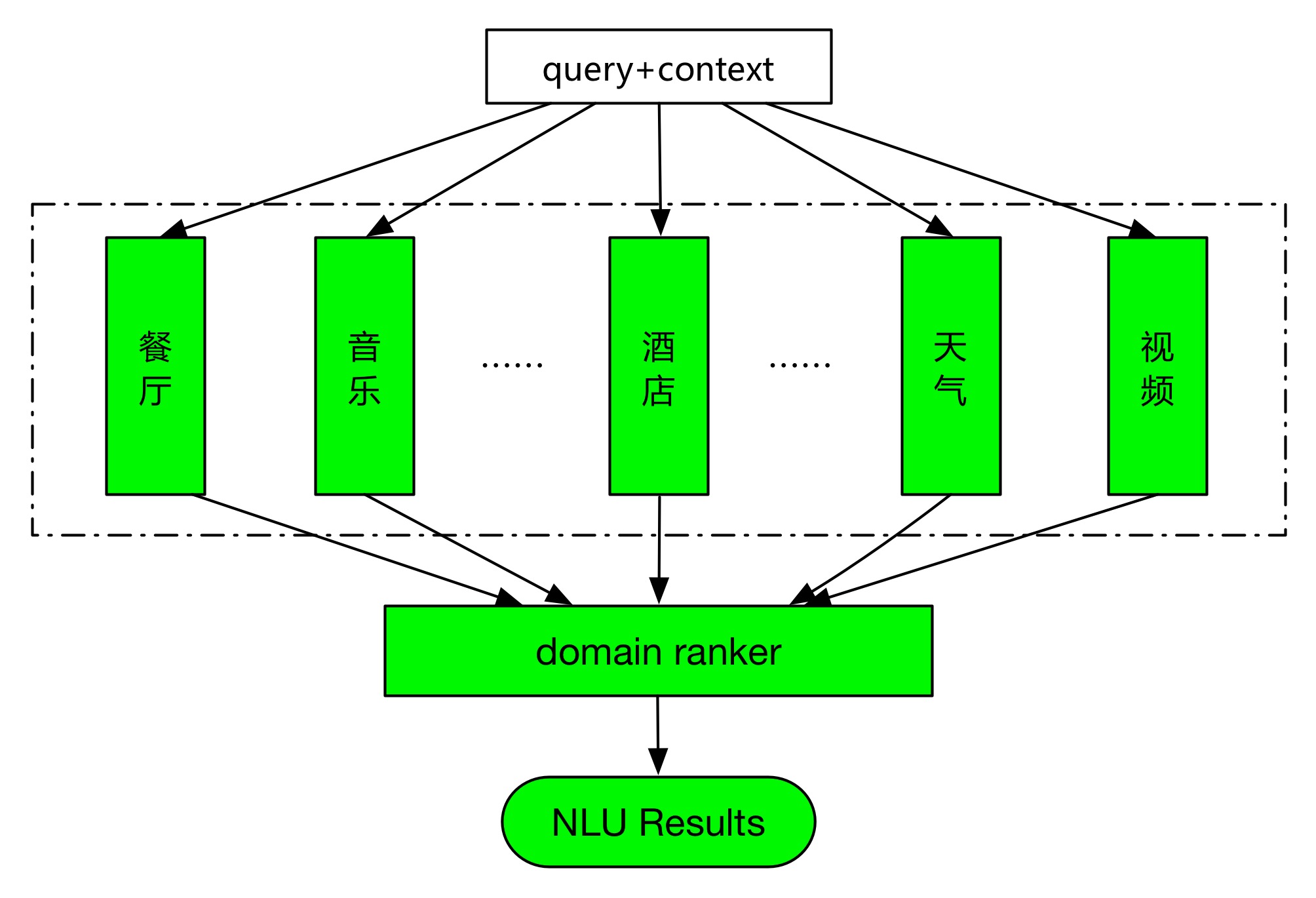
领域的优化和扩展是常态,如果某个领域的优化或者新增,会对其他已有的领域的效果造成影响,那这将是一种灾难。我们建立了如下图所示的领域独立的、可扩展的算法框架,各个领域在知识库、数据、模型、算法等方面,都是各自独立的。
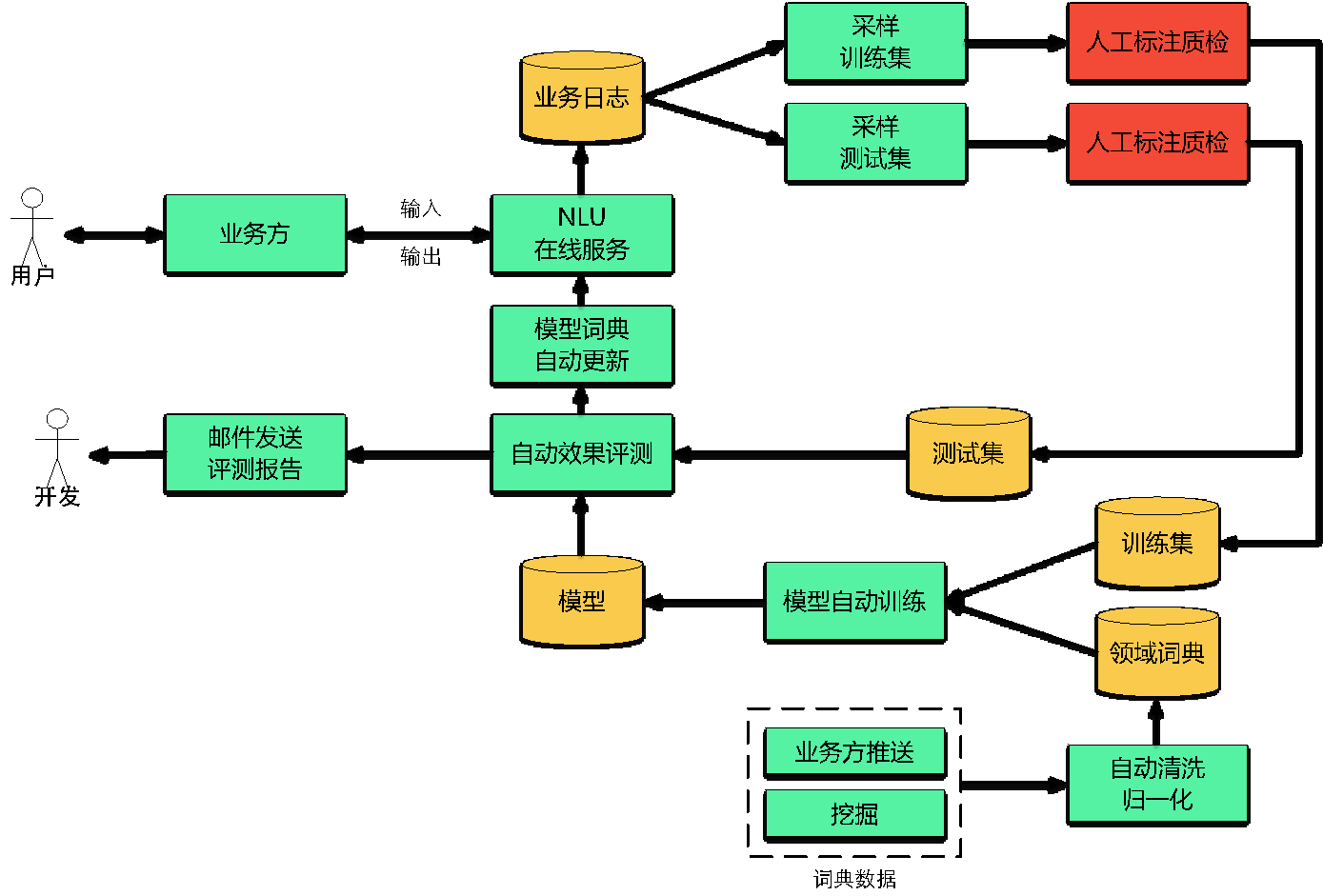
4.4 数据驱动的闭环流程
我们构建了如下的闭环数据流程,使得数据能够闭环流动,随着用户的使用,我们不断收集日志对系统进行更新,从而不断维持和提升系统的效果。
4.5 基于上下文的自然语言理解
为了理解对话,我们进一步设计了基于上下文的自然语言理解框架,和无上下文相比,它主要的变化在于增加了一个domain selection模块,该模块在基于上下文的知识下,判断当前话语(utterance)是否需要继承上文知识。
5. 结束语
自然语言理解是个人智能助理的基础模块和核心模块,我们目前的自然语言理解服务同时实现了无上下文的理解和有上下文的理解,无上下文的理解主要应用在搜素场景,如YunOS上的One Search搜索,有上下文的理解主要应用于对话场景,如YunOS上的个人智能助理+、阿里小蜜等。后续我们一方面在技术上会进一步做深,另一方面会服务更多的业务,欢迎各位有兴趣的同学一起交流探讨。
