2.2 数据分布及其检验
样本数据的数字特征刻画了数据的主要特征,而要对数据的总体情况作全面的了解,就必须研究数据的分布。上节中的数据直方图与Q-Q图等能直观粗略地描述数据的分布,本节进一步研究如何判定数据是否服从正态分布的问题。若不服从正态分布,那么又可能服从怎样的分布?
2.2.1 一维数据的分布与检验
1.经验分布函数
设来自总体X的容量为n的样本x1,x2,…,xn,样本的次序统计量为x(1),x(2),…,x(n),对于任意实数x,定义函数
Fn(x)=0,若x<x(1)
kn,若x(k)≤x<x(k+1) (k=1,2,…,n-1)
1,若x≥x(n)(2.2.1)
称Fn(x)为经验分布函数。
由定义可知,Fn(x)表示事件{X≤x}在n次独立重复试验中的频率。
1933年,格里汶科(Glivenko)证明了以下结果:对于任一实数x,当n→∞时Fn(x)以概率1一致收敛于分布函数F(x),即
Plimn→∞sup-∞<x<∞Fn(x)-F(x)=0=1
这一结论表明:对于任一实数x,当n充分大时
F(x)≈Fn(x)(2.2.2)
因此可用经验分布函数来近似代替F(x),这一点也是由样本推断总体的最基本理论依据之一。
在MATLAB中,作经验(累积)分布函数图形命令cdfplot的调用格式为:
① cdfplot(X); %作样本X(向量)的经验(累积)分布函数图形
② h=cdfplot(X);% h表示曲线的环柄
③ \[h,stats\]=cdfplot(X);%输出stats表示样本最小值、最大值、均值、中值与标准差
通常,将样本的直方图与经验分布函数图结合应用,对数据的分布作出推断。
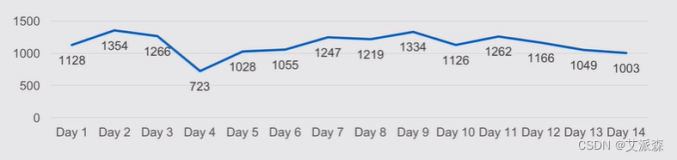
例2.2.1 生成服从标准正态分布的50个样本点,作出样本的经验分布函数图,并与理论分布函数Φ(x)比较。
解:编写程序如下。
clear
X=normrnd (0,1,50,1);%生成服从标准正态分布的50个样本点
\[h,stats\]=cdfplot(X);%绘制样本的经验分布函数图
hold on
plot(-3:0.01:3, normcdf(-3:0.01:3,0,1), 'r') %绘制理论分布函数图
legend('样本经验分布函数Fn(x)', '理论分布函数Φ(x)' ,'Location','NorthWest');
输出结果:
h =
3.0013
stats =
min: -1.8740%样本最小值
max: 1.6924%最大值
mean: 0.0565%平均值
median: 0.1032%中间值
std: 0.7559%样本标准差
图2-12表明样本的经验分布函数图形与理论分布函数图很相近。
图2-12 N(0,1)分布函数图及其50个样本点的经验分布函数图
2.总体分布的正态性检验
进行参数估计和假设检验时,通常总是假定总体服从正态分布,虽然在许多情况下这个假定是合理的,但是当要以此为前提进行重要的参数估计或假设检验,或者人们对它有较大怀疑的时候,就确有必要对这个假设进行检验。进行总体正态性检验的方法有很多种,以下针对MATLAB统计工具箱中提供的程序,简单介绍几种方法。
(1)Jarque-Bera检验
Jarque-Bera检验简称JB检验,它是利用正态分布的偏度sk和峰度ku,构造一个包含sk、ku且自由度为2的卡方分布统计量
JB=n16J2+124B2~χ2(2)(2.2.3)
其中J=1n∑ni=1xi-xS3,B=1n∑ni=1xi-xS4-3。
对于显著性水平α,当JB统计量小于χ2分布的1-α分位数χ21-α(2)时接受H0,即认为总体服从正态分布;否则拒绝H0,即认为总体不服从正态分布。这个检验适用于大样本,当样本容量n较小时需慎用。
在MATLAB中,JB检验命令jbtest的调用格式为:
H = jbtest(X,alpha);
或
\[H,P,JBSTAT,CV\] = jbtest(X,alpha);
对输入向量X进行Jarque-Bera测试,显著性水平alpha缺省为0.05。输出H为测试结果,若H=0,则不能拒绝X服从正态分布;若H=1,则可以否定X服从正态分布。输出P为接受假设的概率值,P小于alpha,则可以拒绝是正态分布的原假设;JBSTAT为测试统计量的值,CV为是否拒绝原假设的临界值,JBSTAT大于CV可以拒绝是正态分布的原假设。
命令jbtest一般用于大样本,对于小样本用命令lillietest。
(2)Kolmogorov-Smirnov检验
Kolmogorov-Smirnov检验简称KS检验,它是通过样本的经验分布函数与给定分布函数的比较,推断该样本是否来自给定分布函数的总体。设给定分布函数为G(x),构造统计量
Dn=maxn(Fn(x)-G(x))(2.2.4)
即两个分布函数之差的最大值,对于假设H0:总体服从给定的分布G(x),及给定的α,根据Dn的极限分布确定统计量关于是否接受H0的数量界限。
因为这个检验需要给定G(x),所以当用于正态性检验时只能做标准正态检验,即H0:总体服从标准正态分布N(0,1)。
在MATLAB中,KS检验命令kstest的调用格式为:
h = kstest(x);
h = kstest(x,cdf);
\[h,p,ksstat,cv\] = kstest(x,cdf,alpha);
把向量x中的值与标准正态分布进行比较并返回假设检验结果h。如果h=0表示不能拒绝原假设,即不能拒绝服从正态分布;若h=1,则可以否定x服从正态分布。假设的显著水平默认值是0.05。cdf是一个两列矩阵,矩阵的第一列包含可能的x值,第二列是假设累积分布函数G(x)的值。在可能的情况下,cdf的第一列应包含x中的值,如果第一列没有,则用插值的方法近似。指定显著水平alpha,返回p值、KS检验统计量ksstat、截断值cv。
(3)Lilliefors检验
Lilliefors检验是改进KS检验并用于一般的正态性检验,原假设H0:总体服从正态分布N(μ,σ2),其中μ、σ2由样本均值和方差估计。
该检验的MATLAB命令lillietest的调用格式为:
H = lillietest(X,alpha);
或
\[H,P,LSTAT,CV\] = lillietest(X,alpha);
对输入向量X进行Lilliefors测试,显著性水平alpha在0.01和0.2之间,缺省时为0.05。输出P为接受假设的概率值,LSTAT为测试统计量的值,CV为是否拒绝原假设的临界值。H为测试结果,若H=0,则不能拒绝X服从正态分布;若H=1,则可以否定X服从正态分布。P小于alpha,则可以拒绝是正态分布的原假设;LSTAT大于CV可以拒绝是正态分布的原假设。
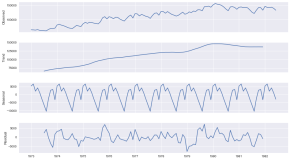
例2.2.2 在例2.1.5中,检验“中国银行”的股票的收盘价是否服从正态分布。
解:程序如下。
clear
a=xlsread('yhgspj.xls'); %读取收盘价数据
h1=jbtest(a(:,1))%JB检验
h2=kstest(a(:,1))%KS检验
h3=lillietest(a(:,1))%改进KS检验
qqplot(a(:,1))
程序运行结果:h1=1,h2=1,h3=1,三种检验都不支持“中国银行”股票的收盘价服从正态分布,Q-Q图(如图2-13所示)也可看出收盘价不服从正态分布,从而可以认为收盘价不服从正态分布。
图2-13 中国银行收盘价的Q-Q图
2.2.2 多维数据的正态分布检验
1.多维正态分布的概念与性质
设p维总体X=(X1,X2,…,Xp)T的分布密度函数为
f(x1,x2,…,xp)=1(2π)p/2Σ1/2exp-12(x-μ)TΣ-1(x-μ)(2.2.5)
则称X服从p维正态分布,记为X~Np(μ,Σ),其中
x=(x1,x2,…,xp)T,μ=(μ1,μ2,…,μp)T,Σ=σ11σ12…σ1p
σ21σ22…σ2p
…
σp1σp2…σpp
μ称为总体均值向量,Σ称为总体协方差矩阵。
多维正态分布具有如下性质:
1)多维正态分布的边缘分布还是服从正态分布,但反之不真。
2)多维正态分布在线性变换下仍然服从多维正态分布。即若X~Np(μ,Σ),A为s×p阶常数矩阵,d为s维常数向量,则
AX+d~Ns(Aμ+d,AΣAT)
3)服从正态分布的随机变量间相互独立与不相关等价。
2.多维正态分布的Q-Q图检验方法
对于来自总体且由式(2.1.16)表示的样本数据矩阵X,怎样检验其是否是来自于多维正态总体呢?一般可按照以下Q-Q图检验方法,具体的过程如下:
1)由样本数据矩阵X计算均值向量X和协方差矩阵S。
2)计算样本点X[t]到X的马氏平方距离,其中X[t]表示X的第t行。(参见第4章)。
D2t=(X[t]-X)TS-1(X[t]-X) (t=1,…,n)
3)对上述马氏平方距离从小到大排序
D2(1)≤D2(2)≤…≤D2(n)
4)计算pt=t-0.5n(t=1,2,…,n)及χ2t,其中χ2t满足H(χ2tp)=pt。
5)以马氏距离为横坐标,χ2t分位数为纵坐标作n个点(D2(t),χ2t)的平面散点图,即分布的Q-Q图。
6)考查散点图是否在一条通过原点且斜率为1的直线上,若是则接受数据来自p维正态分布总体的假设,否则拒绝正态分布假设。
以上Q-Q图检验方法的MATLAB程序实现如下。
%输入样本数据矩阵X
X=\[data\];
\[N,p\]=size(X); %X的行数及列数
d=mahal(X,X);%计算马氏距离
d1=sort(d);%马氏距离从小到大排序
pt=\[\[1:N\]-0.5\]/N;%计算分位数
x2=chi2inv(pt,p);%计算χ2t
plot(d1,x2','*',\[0:m\],\[0:m\],'-r')%作散点图与直线y=x,其中m是正整数
以下举例说明上述程序的应用。
例2.2.3 为了研究某种疾病,对一批60人分为三组:G1、G2、G3,同时进行4项指标的检测,即β脂蛋白(X1)、甘油三酯(X2)、α脂蛋白(X3)、前β脂蛋白(X4)。检测的结果列在表2-7中,现将三组检验数据视为一个总体,问总体是否服从四维正态分布?
表2-7 四项指标检测数据
G1
G2
G3
X1
X2
X3
X4
X1
X2
X3
X4
X1
X2
X3
X4
260
75
40
18
310
122
30
21
320
64
39
17
200
72
34
17
310
60
35
18
260
59
37
11
240
87
45
18
190
40
27
15
360
88
28
26
170
65
39
17
225
65
34
16
295
100
36
12
270
110
39
24
170
65
37
16
270
65
32
21
205
130
34
23
210
82
31
17
380
114
36
21
190
69
27
15
280
67
37
18
240
55
42
10
200
46
45
15
210
38
36
17
260
55
34
20
250
117
21
20
280
65
30
23
260
110
29
20
200
107
28
20
200
76
40
17
295
73
33
21
225
130
36
11
200
76
39
20
240
114
38
18
210
125
26
17
280
94
26
11
310
103
32
18
170
64
31
14
190
60
33
17
330
112
21
11
270
76
33
13
295
55
30
16
345
127
24
20
190
60
34
16
270
125
24
21
250
62
22
16
(续)
G1
G2
G3
280
81
20
18
280
120
32
18
260
59
21
19
310
119
25
15
240
62
32
20
225
100
34
30
270
57
31
8
280
69
29
20
345
120
36
18
250
67
31
14
370
70
30
20
360
107
25
23
260
135
39
29
280
40
37
17
250
117
36
16
数据来源:高惠璇,应用多元统计分析,北京大学出版社,2005年第一版。
解:先将表2-7中数据按原位置作为矩阵A输入,然后整理成样本数据矩阵X。程序如下。
clear
A=\[260 75 40 18 310 122 30 21 320 64 39 17;
200 72 34 17 310 60 35 18 260 59 37 11;
……
260 135 39 29 280 40 37 17 250 117 36 16\];
X=\[A(:,1:4);A(:,5:8);A(:,9:12)\];%整理成样本数据矩阵X
\[N,p\]=size(X);
d=mahal(X,X);%计算马氏距离
d1=sort(d);%从小到大排序
pt=\[\[1:N\]-0.5\]/N;%计算分位数
x2=chi2inv(pt,p);%计算χ2t
plot(d1,x2','*',\[0:12\],\[0:12\],'-r')%作图
输出图形如图2-14所示。
图2-14 四项检测数据的多维
正态检验Q-Q图
从图2-14可以看出,数据点基本落在直线上,故不能拒绝该数据服从四维正态分布的假设。
3.多个总体协方差矩阵的相等性检验
(1)两个总体协方差矩阵相等的检验
设从两个总体分别抽取样本容量为n1、n2的两个样本,其样本的协方差矩阵分别为S1、S2,那么在两个总体协方差矩阵相等时,其总体的协方差矩阵的估计为
S=(n1-1)S1+(n2-1)S2(n1+n2-2)
若检验两个总体的协方差矩阵相等,可以有如下假设检验:
H0:Si=SH1:Si≠S,(i=1,2)
检验统计量
Qi=(ni-1)[lnS-lnSi-p+tr(S-1Si)]~χ2(p(p+1)/2)(i=1,2)(2.2.6)
其中·表示行列式,p是向量的维数,tr表示矩阵的迹。
对给定的α,卡方分布临界值为λ,若Qi<λ(i=1,2)则接受H0,否则拒绝H0。
例2.2.4(1989年国际数学竞赛A题:蠓的分类) 蠓是一种昆虫,分为很多类型,其中有一种名为Af,是能传播花粉的益虫;另一种名为Apf,是会传播疾病的害虫,这两种类型的蠓在形态上十分相似,很难区别。现测得6只Apf和9只Af蠓虫的触角长度和翅膀长度数据
Apf:(1.14,1.78),(1.18,1.96),(1.20,1.86),(1.26,2.00),(1.28,2.00),(1.30,1.96);
Af:(1.24,1.72),(1.36,1.74),(1.38,1.64),(1.38,1.82),(1.38,1.90),(1.40,1.70),(1.48,1.82),(1.54,1.82),(1.56,2.08)。
判别Apf与Af两类蠓虫的协方差矩阵是否相等。
解:编写检验协方差矩阵相等的源程序如下。
clear
apf=\[1.14,1.78; 1.18,1.96;1.20,1.86;1.26,2.;1.28,2;1.30,1.96\];
af=\[1.24,1.72;1.36,1.74;1.38,1.64;1.38,1.82;1.38,1.90;1.40,1.70;1.48,1.82;1.54,1.82;1.56,2.08\];
n1=6;n2=9;p=2;
s1=cov(apf);s2=cov(af);
s=((n1-1)*s1+(n2-1)*s2)/(n1+n2-2); %计算混合样本方差
Q1=(n1-1)*(log(det(s))-log(det(s1))-p+trace(inv(s)*s1)) ;
Q2=(n2-1)*(log(det(s))-log(det(s2))-p+trace(inv(s)*s2)) ;%计算检验统计量观测值
输出结果为
Q1 =
2.5784
Q2 =
0.7418
给定α=0.05,查表得到临界值χ21-α(3)=7.8147(命令chi2inv(0.95,3)),由于Q1=2.5784<7.8147,Q2=0.7418<7.8147,故认为两类总体协方差矩阵相同。
(2)多个总体协方差矩阵相等的检验
设有k个p维总体Gi,i=1,2,…,k,从每个总体中分别抽取样本容量为ni(i=1,2,…,k)的k个样本,其样本的协方差矩阵为S1,S2,…,Sk,用S1,S2,…,Sk估计Σ1,Σ2,…,Σk。其中Σi为总体Gi的协方差矩阵。
原假设 H0:Σ1=Σ2=…=Σk;
备择假设 H1:Σ1,Σ2,…,Σk至少有一对不相等。
在H0成立时,统计量
ξ=(1-d)M~χ2(f)(2.2.7)
其中M=(n-k)lnS-∑ki=1(ni-1)lnSi,S=∑ki=1(ni-1)Si/(n-k),f=p(p+1)(k-1)/2为自由度,n=n1+n2+…+nk,
d=2p2+3p-16(p+1)(k-1)∑ki=11ni-1-1n-k,ni不全等
(2p2+3p-1)(k+1)6(p+1)(n-k),ni全等(2.2.8)
对给定的α,计算概率p=P(ξ>χ2α(f)),若p<α则拒绝H0,否则接受H0。
以上过程和程序可用下例说明。
例2.2.5 检验表2-7中三个总体G1、G2、G3的协方差矩阵是否相等(α=0.1)。
解:编写程序如下。
clear
A=\[data\]; %输入样本数据
G1=A(:,1:4);%提取总体1的样本
G2=A(:,5:8);
G3=A(:,9:12);
n=size(G1,1)+ size(G2,1)+ size(G2,1);%计算总的样本容量
\[n1,p\]= size(G1);
k=3;
f=p*(p+1)*(k-1)/2;%统计量自由度
d=(2*p^2+3*p-1)*(k+1)/(6*(p+1)*(n-k));%由式(2.2.8)计算
s1=cov(G1);%协方差矩阵
s2=cov(G2);%协方差矩阵
s3=cov(G3);%协方差矩阵
s=(n1-1)*(s1+s2+s3)/(n-k);%总体协方差矩阵估计
M=(n-k)*log(det(s))-19*(log(det(s1))+log(det(s2))+log(det(s3)));%计算式(2.2.7)中的M值
T=(1-d)*M;%计算式(2.2. 7)统计量
P0=1-chi2cdf(T,f);%卡方分布概率
输出结果:
T= 20.3316,P0= 0.4374
由于由统计量计算得到的概率为P0=0.4374>0.1,故判定3个总体协方差矩阵相等。