1.2 Apache Kylin的使命
Kylin的使命是超高速的大数据OLAP(Online Analytical Processing),也就是要让大数据分析像使用数据库一样简单迅速,用户的查询请求可以在秒内返回,交互式数据分析将以前所未有的速度释放大数据里潜藏的知识和信息,让我们在面对未来的挑战时占得先机。
1.2.1 为什么要使用Apache Kylin
自从10年前Hadoop诞生以来,大数据的存储和批处理问题均得到了妥善解决,而如何高速地分析数据也就成为了下一个挑战。于是各式各样的“SQL on Hadoop”技术应运而生,其中以Hive为代表,Impala、Presto、Phoenix、Drill、SparkSQL等紧随其后。它们的主要技术是“大规模并行处理”(Massive Parallel Processing,MPP)和“列式存储”(Columnar Storage)。大规模并行处理可以调动多台机器一起进行并行计算,用线性增加的资源来换取计算时间的线性下降。列式存储则将记录按列存放,这样做不仅可以在访问时只读取需要的列,还可以利用存储设备擅长连续读取的特点,大大提高读取的速率。这两项关键技术使得Hadoop上的SQL查询速度从小时提高到了分钟。
然而分钟级别的查询响应仍然离交互式分析的现实需求还很远。分析师敲入查询指令,按下回车,还需要去倒杯咖啡,静静地等待查询结果。得到结果之后才能根据情况调整查询,再做下一轮分析。如此反复,一个具体的场景分析常常需要几小时甚至几天才能完成,效率低下。
这是因为大规模并行处理和列式存储虽然提高了计算和存储的速度,但并没有改变查询问题本身的时间复杂度,也没有改变查询时间与数据量成线性增长的关系这一事实。假设查询1亿条记录耗时1分钟,那么查询10亿条记录就需10分钟,100亿条记录就至少需要1小时40分钟。当然,可以用很多的优化技术缩短查询的时间,比如更快的存储、更高效的压缩算法,等等,但总体来说,查询性能与数据量呈线性相关这一点是无法改变的。虽然大规模并行处理允许十倍或百倍地扩张计算集群,以期望保持分钟级别的查询速度,但购买和部署十倍或百倍的计算集群又怎能轻易做到,更何况还有高昂的硬件运维成本。
另外,对于分析师来说,完备的、经过验证的数据模型比分析性能更加重要,直接访问纷繁复杂的原始数据并进行相关分析其实并不是很友好的体验,特别是在超大规模的数据集上,分析师将更多的精力花在了等待查询结果上,而不是在更加重要的建立领域模型上。
1.2.2 Apache Kylin怎样解决关键问题
Apache Kylin的初衷就是要解决千亿条、万亿条记录的秒级查询问题,其中的关键就是要打破查询时间随着数据量成线性增长的这个规律。仔细思考大数据OLAP,可以注意到两个事实。
大数据查询要的一般是统计结果,是多条记录经过聚合函数计算后的统计值。原始的记录则不是必需的,或者访问频率和概率都极低。
聚合是按维度进行的,由于业务范围和分析需求是有限的,有意义的维度聚合组合也是相对有限的,一般不会随着数据的膨胀而增长。
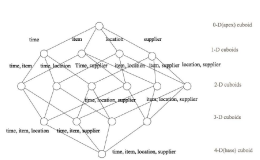
基于以上两点,我们可以得到一个新的思路——“预计算”。应尽量多地预先计算聚合结果,在查询时刻应尽量使用预算的结果得出查询结果,从而避免直接扫描可能无限增长的原始记录。
举例来说,使用如下的SQL来查询10月1日那天销量最高的商品:
select item, sum(sell_amount)
from sell_details
where sell_date='2016-10-01'
group by item
order by sum(sell_amount) desc
用传统的方法时需要扫描所有的记录,再找到10月1日的销售记录,然后按商品聚合销售额,最后排序返回。假如10月1日有1亿条交易,那么查询必须读取并累计至少1亿条记录,且这个查询速度会随将来销量的增加而逐步下降。如果日交易量提高一倍到2亿,那么查询执行的时间可能也会增加一倍。
而使用预计算的方法则会事先按维度[sell_date, item]计算sum(sell_amount)并存储下来,在查询时找到10月1日的销售商品就可以直接排序返回了。读取的记录数最大不会超过维度[sell_date, item]的组合数。显然这个数字将远远小于实际的销售记录,比如10月1日的1亿条交易包含了100万条商品,那么预计算后就只有100万条记录了,是原来的百分之一。并且这些记录已经是按商品聚合的结果,因此又省去了运行时的聚合运算。从未来的发展来看,查询速度只会随日期和商品数目的增长而变化,与销售记录的总数不再有直接联系。假如日交易量提高一倍到2亿,但只要商品的总数不变,那么预计算的结果记录总数就不会变,查询的速度也不会变。
“预计算”就是Kylin在“大规模并行处理”和“列式存储”之外,提供给大数据分析的第三个关键技术。