那首先看下日志中数据回滚的原因,当数据写入rds或者hybridDB等一些支持事务的数据库中,数据批量写入,一旦由于各种原因没有写入成功,这个批次的数据会回滚重新写入,如果再次写入失败,就会报脏数据的错误导致任务失败。数据写入失败可能是以下原因导致回滚。
1,脏数据(数据值超过数据类型最大范围,数据类型不对应等等)
2,目标数据源字段设置,比如默认不允许为空
3,主键冲突
4,目标数据源本身负载太高,写入时死锁
5,同步的设置的速度太大,比如数据量很大,速度设为10M/s。
常见回滚日志报错示例:
2017-01-01 17:01:32.544 [16876048-0-0-writer] WARN CommonRdbmsWriter$Task - 回滚此次写入, 采用每次写入一行方式提交.
因为:java.sql.BatchUpdateException: INSERT, DELETE command denied to user 'xxx'@'xx.xx.xx.xx' for table 'report'下面来看几个案例
案例一: MaxCompute到hybridDB的数据同步任务报错,错误提示:
INSERT INTO hybrid_schema.dim_bz_317hu_account_gold_stg (id,account_id,hospital_id,total_gold,valid_flag,withhold,type,com_date_id,com_hour_id,from_source,create_time,update_time,creator,updater) VALUES('7933'::int8,'33718'::int8,'560'::int8,'0.0'::float8,'ENABLE'::varchar,'0.0'::float8,'1'::int8,'20170322'::int8,'11031'::int8,'bz_317hu'::varchar,'2017-03-22 10:31:45.000000 +08:00:00'::timestamp,'2017-03-22 10:31:45.000000 +08:00:00'::timestamp,'liuchang'::varchar,'liuchang'::varchar) was aborted. Call getNextException to see the cause.
2017-03-23 00:51:34.154 [job-24934082] INFO LocalJobContainerCommunicator - Total 47 records, 4672 bytes | Speed 0B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 0.00%
2017-03-23 00:51:37.976 [24934082-0-9-writer] WARN CommonRdbmsWriter$Task - 回滚此次写入, 采用每次写入一行方式提交. 因为:Batch entry 0 INSERT INTO hybrid_schema.dim_bz_317hu_account_gold_stg (id,account_id,hospital_id,total_gold,valid_flag,withhold,type,com_date_id,com_hour_id,from_source,create_time,update_time,creator,updater) VALUES('7931'::int8,'39316'::int8,'568'::int8,'0.0'::float8,'ENABLE'::varchar,'0.0'::float8,'1'::int8,'20170322'::int8,'11016'::int8,'bz_317hu'::varchar,'2017-03-22 10:16:04.000000 +08:00:00'::timestamp,'2017-03-22 10:16:04.000000 +08:00:00'::timestamp,'liuchang'::varchar,'liuchang'::varchar) was aborted. Call getNextException to see the cause.
2017-03-23 00:51:38.987 [24934082-0-9-writer] ERROR StdoutPluginCollector -
org.postgresql.util.PSQLException: ERROR: deadlock detected
Detail: Process 42073445 waits for ExclusiveLock on resource queue 6055; blocked by process 50785454.
Process 50785454 waits for ShareUpdateExclusiveLock on relation 853985 of database 17163; blocked by process 51099525.
Process 51099525 waits for ExclusiveLock on resource queue 6055; blocked by process 42073445.
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2198) ~[postgresql-9.3-1102-jdbc4.jar:na]
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:1927) ~[postgresql-9.3-1102-jdbc4.jar:na]
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:255) ~[postgresql-9.3-1102-jdbc4.jar:na]
at org.postgresql.jdbc2.AbstractJdbc2Statement.execute(AbstractJdbc2Statement.java:561) ~[postgresql-9.3-1102-jdbc4.jar:na]
at org.postgresql.jdbc2.AbstractJdbc2Statement.executeWithFlags(AbstractJdbc2Statement.java:419) ~[postgresql-9.3-1102-jdbc4.jar:na]
at org.postgresql.jdbc2.AbstractJdbc2Statement.execute(AbstractJdbc2Statement.java:412) ~[postgresql-9.3-1102-jdbc4.jar:na]
at com.alibaba.datax.plugin.rdbms.writer.CommonRdbmsWriter$Task.doOneInsert(CommonRdbmsWriter.java:382) [plugin-rdbms-util-0.0.1-SNAPSHOT.jar:na]
at com.alibaba.datax.plugin.rdbms.writer.CommonRdbmsWriter$Task.doBatchInsert(CommonRdbmsWriter.java:362) [plugi 问题定位:
有数据回滚操作,初步定位为数据在hybridDB写入失败,回滚写入失败,出现脏数据大于用户设置的0条。任务终止。
问题排查:
看到日志中出现下面报错:
排查看到日志中有显眼的一句:
org.postgresql.util.PSQLException: ERROR: deadlock detected 那么问题基本定位到:是因为hybridDB这边表出现死锁,数据写不进去,报脏数据,任务失败。
导致hybridDB死锁的原因可能是这个表的负载很大,排查一下用户配置:同步速率设置的10M/s,那就非常有可能是这个速度和用户的数据量太大,写入负载太高导致死锁。
解决方法:根据自己数据量和需求设置同步速度,这个案例建议用户调小一些同步速率,错开高峰,把任务放到低谷时期执行。
案例二:目标数据库设置字段不能为空,数据中有null值,同步报错: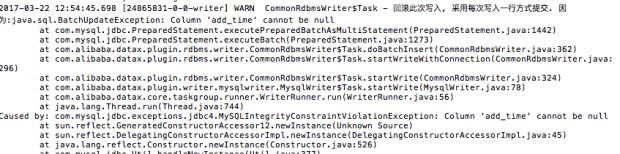
问题定位:报错显示目标数据库中的有些字段设置的是cannot be null,而数据中有null值。导致失败
解决方案:修改目标数据库中的字段设置,如果此字段必须不能为空,核对下数据来源保证不能为空,或者对数据预处理一下null值。
案例三:数据同步到rds时,odps中有重复数据,rds中设置主键,导致主键冲突。
问题定位:日志中有回滚写入操作,报错提示 Detail: Key (id)=(2022080640) already exists.可以定位是主键冲突了,
原因是rds中设置主键的这个字段在odps中存在重复,并不是唯一值。
解决方案:
1,建议重新建一张没有主键的表。
2,如果要主键,选择odps中有唯一约束的字段。
3,业务上允许的话,可以先对odps中的数据进行去重再同步
案例三:数据同步到rds,rds端字段数据类型设置太小。
原因定位:数据同时出现回滚,报错:java.sql.BatchUpdateException: Data truncation: Data too long for column 'flash' at row 1
Maxcompute中的数据字段值,超出rds表中设置的数据类型的阈值,导致写入失败。
解决方案:去rds中调大这个字段的对应数据类型值
案例四、odps同步数据超过24小时
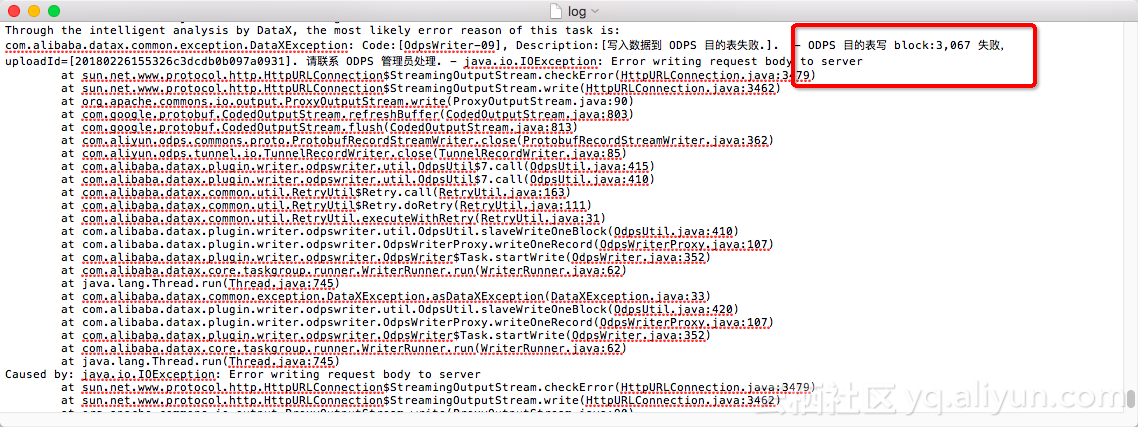
maxcompute tunnel session 超时时间为24小时。
数据规模太大,传输时间已经超过24小时会报异常。
解决方案:
建议您将作业速率上限和作业并发数调大,比如:5M, 5个并发
https://help.aliyun.com/document_detail/49810.html
注意,如果数据源是线上的业务库,建议您不要将并发数设置过大,以防对线上的业务库造成影响。
https://help.aliyun.com/document_detail/54070.html
另外也建议把数据分开上传
总结:数据同步任务涉及多种数据源,问题类型也是比较多。那从日志中排查报错是比较常见的方式。本文就罗列了一些Maxcompute到其他数据库的一些常见典型的案例,有不足的地方希望读者联系我指出来啊
