Kafka是一种快速、可扩展的,设计内在就是分布式的、分区的和可复制的提交日志服务。作为一种高吞吐量的分布式发布订阅消息系统,Kafka被广泛的应用于海量日志的收集、存储。网上有大量Kafka架构、原理介绍的文章,本文不再重复赘述,重点谈谈Consumer Offset默认保存机制。
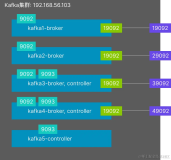
Topic作为一类消息的逻辑集合,Kafka集群为其维护了一个分区的日志,其结构如图:
Topic每个分区是一个有序的、信息不断追加的序列。分区中的每个消息都分配了一个连续的ID号,称为偏移量(offset),用于唯一标识每个消息在分区中的位置。消费者根据自身保存的offset值确定各分区消费的位置。在0.8版本之前,Kafka一直将consumer的 offset信息记录在ZooKeeper中。
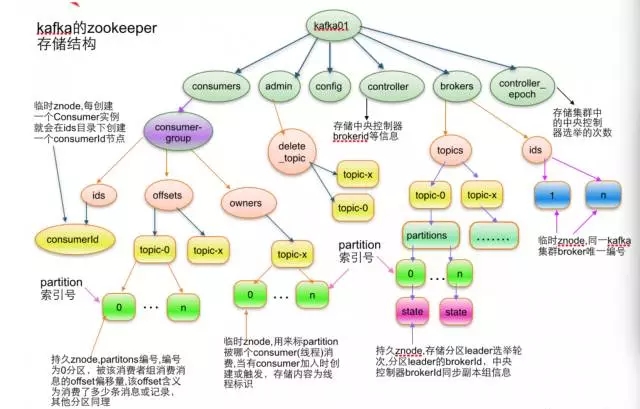
Kafka的ZooKeeper存储架构图
如图,在offsets的子节点中保存了不同的topic的offset 信息。Consumer在消费topic中的信息时需要不断的更新ZooKeeper中的offset信息。
众所周知,由于ZooKeeper并不适合大批量的频繁写入操作,从0.8.2版本开始Kafka开始支持将consumer的位移信息保存在Kafka内部的topic中(从0.9.0版本开始默认将offset存储到系统topic中),虽然此举解决了ZooKeeper频繁写入的性能瓶颈,但却引入了新的问题。
以下是一个真实的案例:
磁盘使用率异常
某日Kafka集群的pc-xxx01主机的文件系统使用率超过80%,触发告警。通过分析发现,topic __consumer_offset 相关log占用大量的磁盘空间。
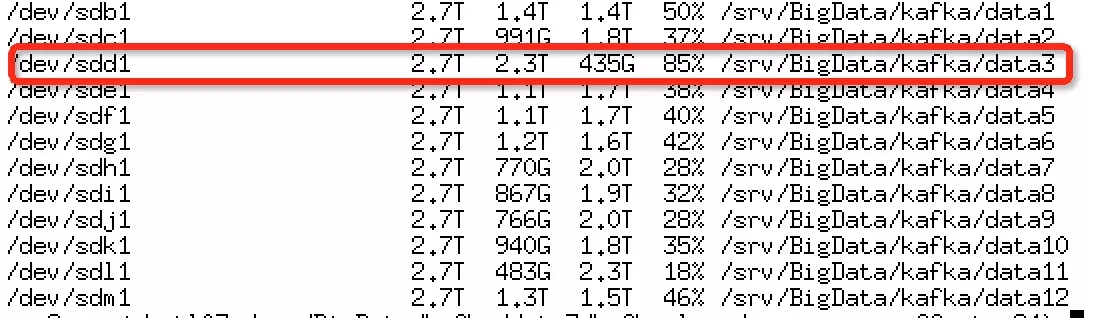
图1
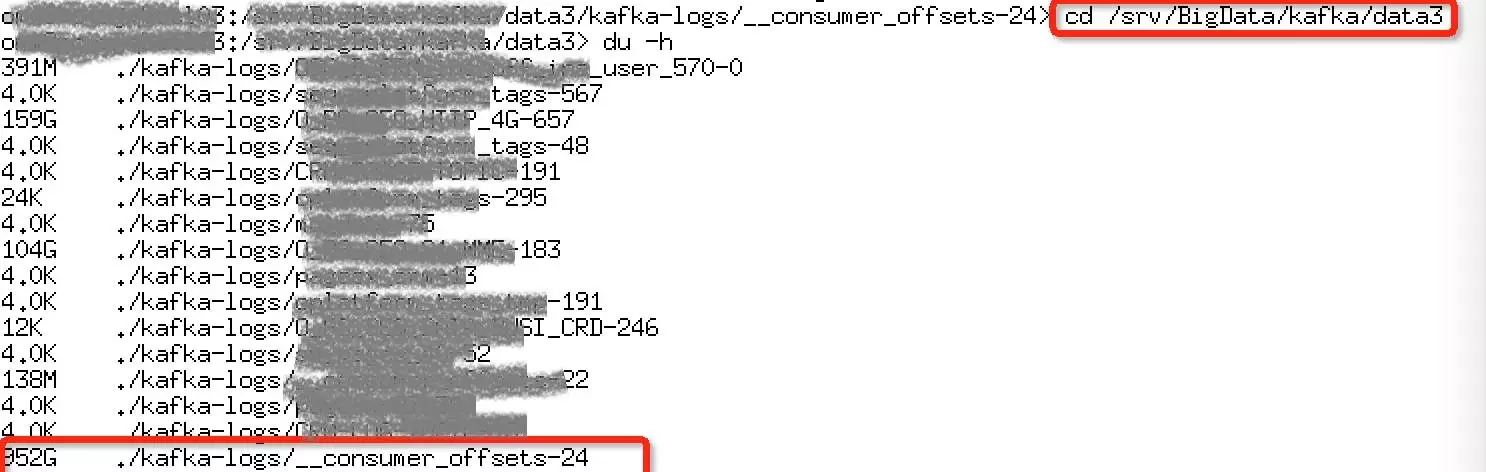
图2
如图1、2所示,pc-xxx01主机data3目录的磁盘使用率超过85%,其中__consumer_offset对应的24号分区的日志占用了952G,占总使用量的41%。
__consumer_offset的作用
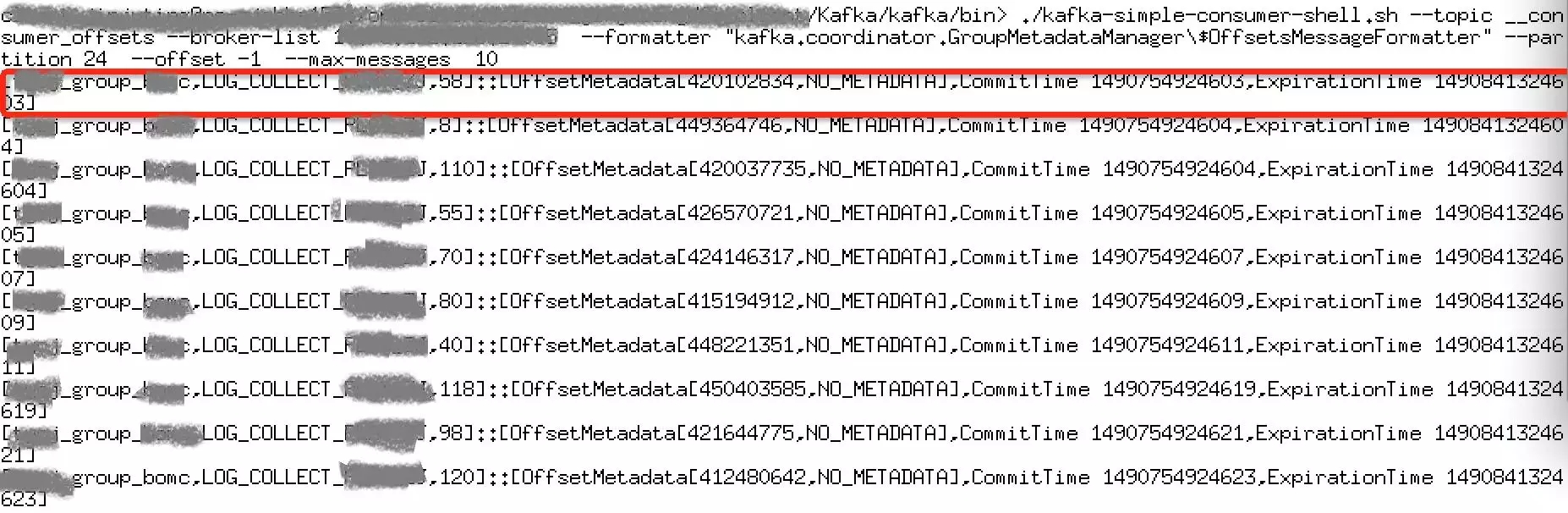
图3
如图3所示,通过消费__consumer_offsets 分区24的数据可以发现,该topic保存的消息格式为[consumer group,topic name,partition]::[offsetmetadata[offset value,nometadata],committime value,expiratintime value],即一条消息包含消费组、topic、分区、offset值、提交时间、过期时间等信息。此topic正是kafka用来保存consumer offset的系统topic(根据实验验证该topic的消息以consumer group为key进行hash,相同consumer group的offset信息会被插入同一个partition)。
__consumer_offsets数据产生的频率
Consumer消费消息之后会向offset manager 发送offsetCommitrequest请求,offset manager 负责将对应的consumer group、topic、partition、offset等信息插入__consumer_offsets topic。系统默认每60s为consumer提交一次offsetcommit请求(由auto.commit.interval.ms, auto.commit.enable两个参数决定)。应用可以采用同步commit的方式进行数据消费(即consumer每处理一条消息触发一次commit操作),这可能导致频繁发送offsetCommitrequest请求的现象发生。
__consumer_offsets 数据保留策略
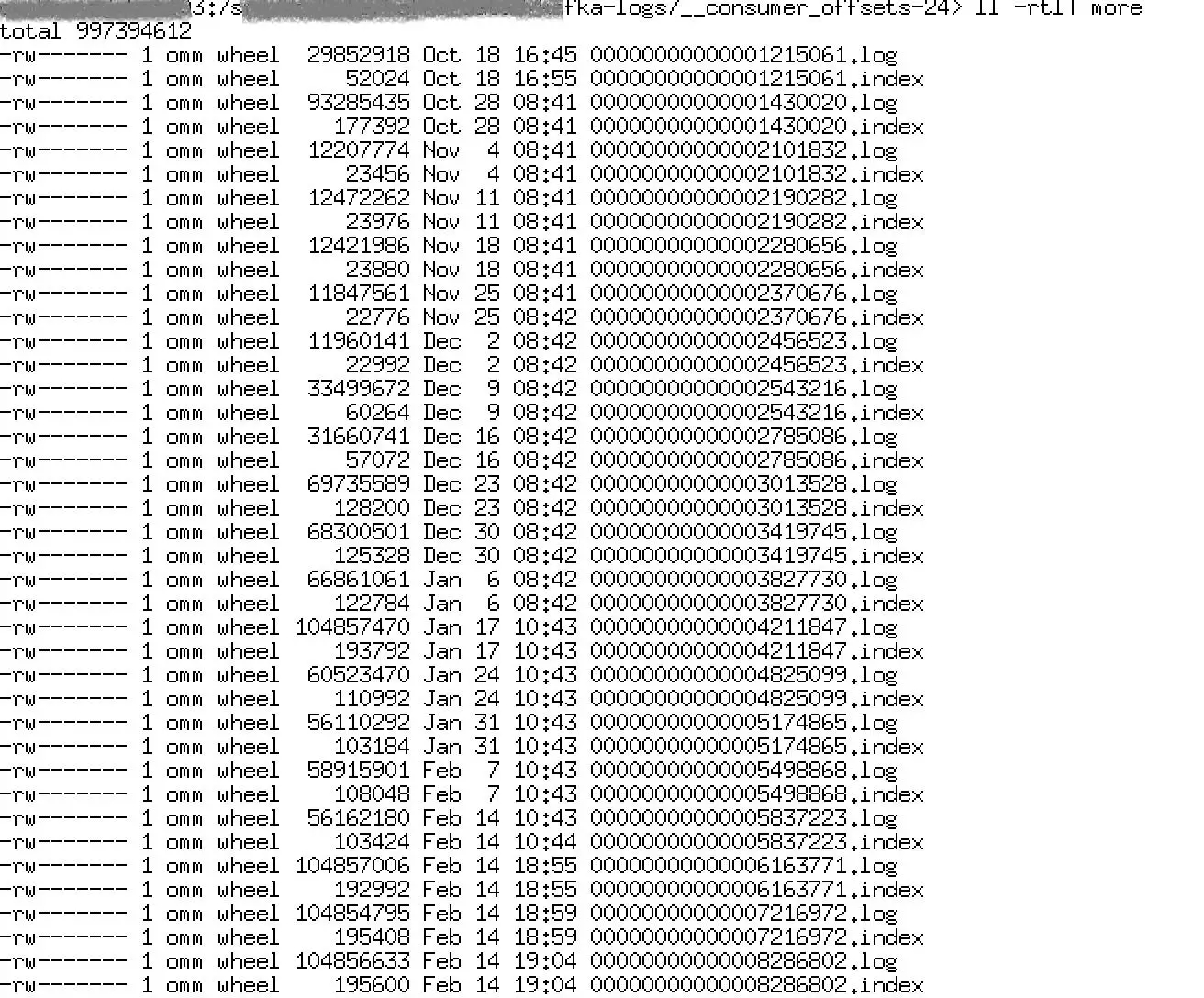
图4
如图4所示,当前__consumer_offsets 24号分区保留了16年10月到现在的所有消息日志,总量达到952G。
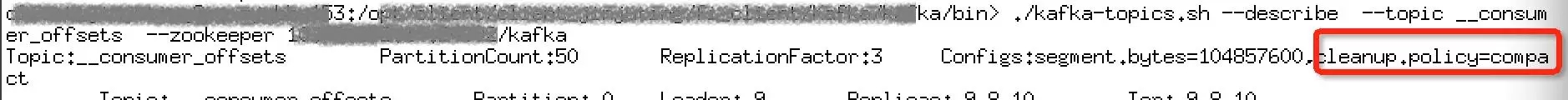

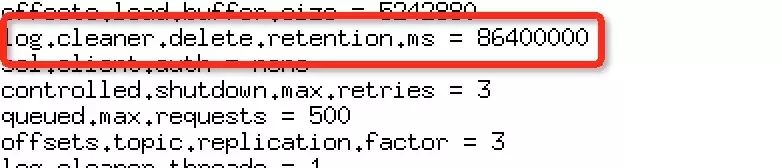
当前__consumer_offsets 的清理策略为compact,日志保留周期为24小时,但是系统默认的log.cleaner.enable为false,导致kafka不会对超过保留周期的数据进行压缩处理,topic保留了系统上线以来的所有历史数据。
不合理的同步提交方式
通过前期分析发现,__consumer_offsets 数据量暴增的24分区的数据主要来自于对log_xxx_plat_xx这个topic的消费组。通过获取应用相关代码分析发现,该topic相关consumer 采用了同步commit方式进行数据消费。
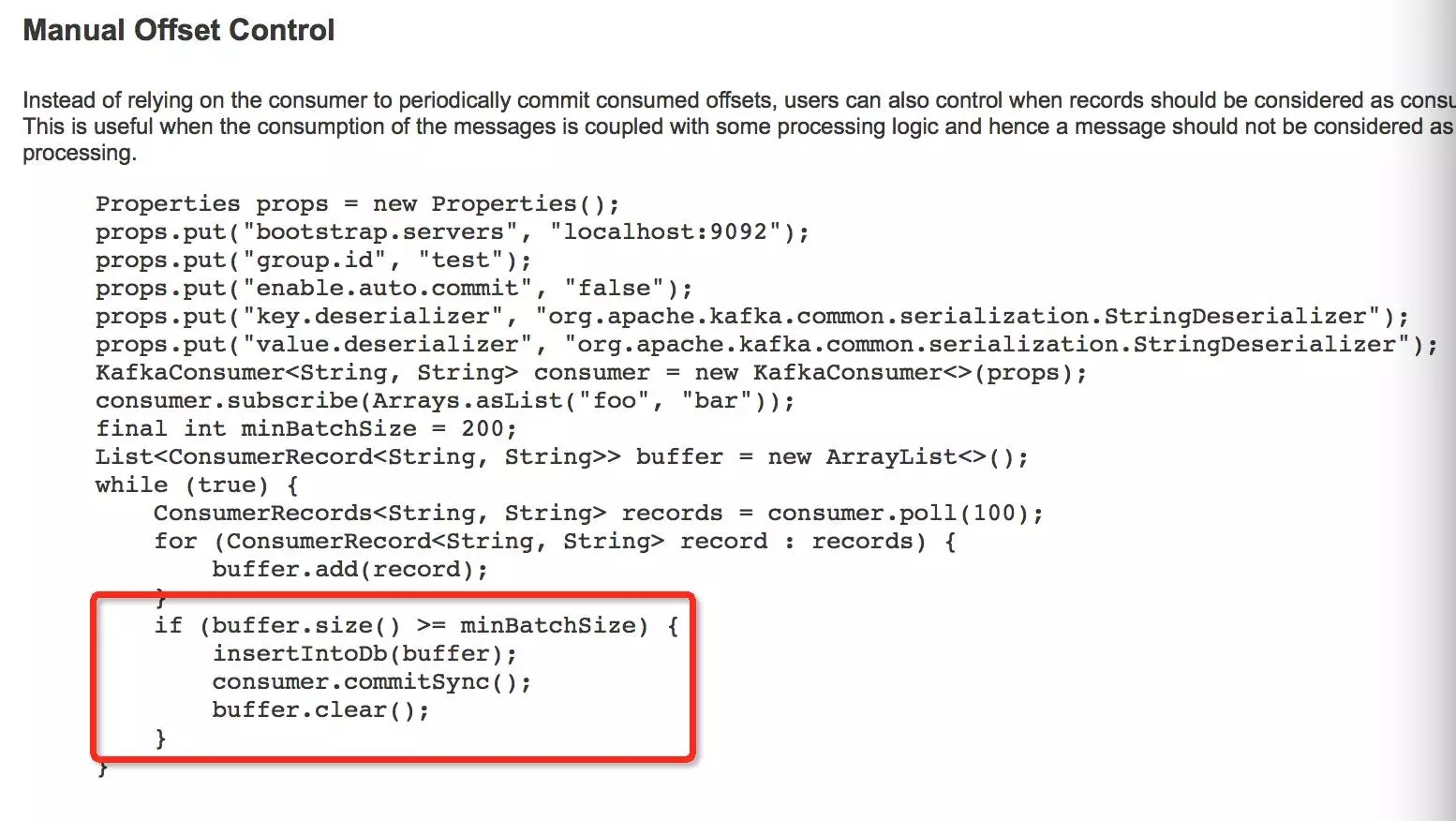
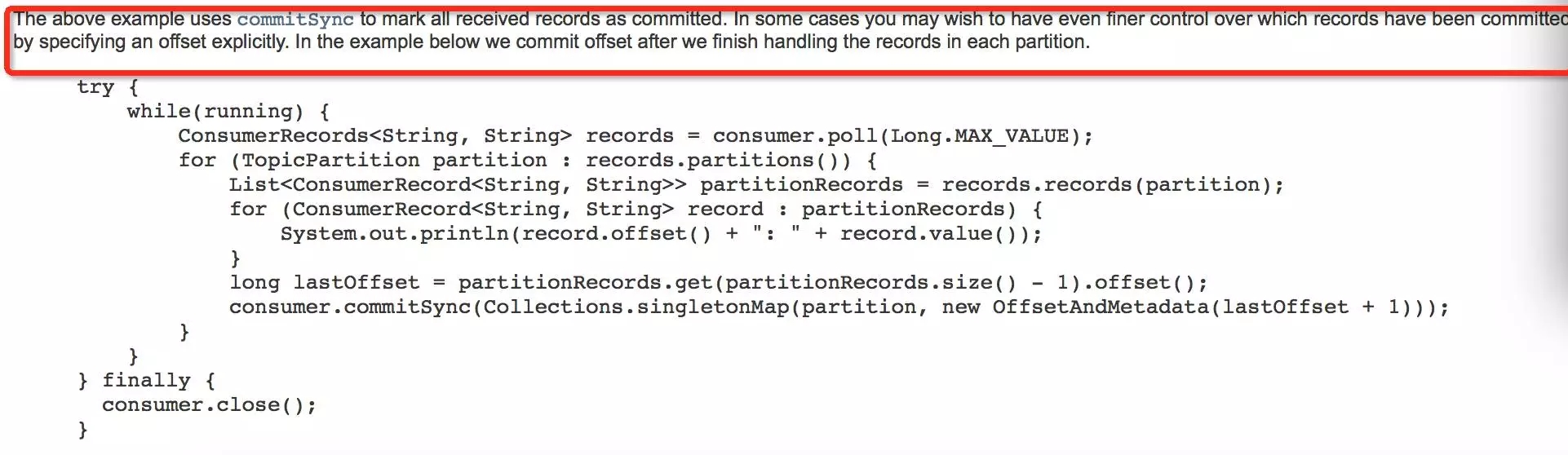
以上是官方文档给出了consumer同步commit消费信息的两种示例代码。第一种方式,只要消费一条消息,就会产生一条commit记录,数据量庞大;第二种方式,对同步commit做了精细化处理,每次批量数据消费,只会对被消费topic各分区中最后一条消息进行commit。如果一个topic包含10个分区,每次消费单个分区需要处理10条消息,采用第一种方式将产生100条commit记录,而第二中方式只会产生10条commit记录,差距巨大。经开发确认,相关应用正是采用了第一种方式进行同步commit。
系统topic分区大小异常的原因
通过以上分析,当前__connsumer_offsets部分分区数据量异常的问题是由于以下两方面原因共同造成:
-
__connsumer_offsets默认清理策略设置不当,导致过期历史数据无法正常清理。
-
部分应用消费方式不当,导致产生大量commit信息。
针对该问题,我们后续优化策略如下,取得了不错的成效。
-
要求应用优化代码,减少commit信息的产生,应用进行代码改造之后commit信息日增加量由原先的37G减少到1.5G。
-
调整topic 清理策略,将系统log.cleaner.enable设置为true,重起broker节点触发日志清理。
优化之后__consumer_offsets 数据量由原先的900G下降到2G。
原文发布时间为:2017-04-28
本文来自云栖社区合作伙伴DBAplus