在Heyzap 和 Bugsnag 我已经使用MongoDB超过一年了,我发现它是一个非常强大的数据库。和其他的数据库一样,它有一些缺陷,但是这里有一些东西我希望有人可以早一点告诉我的。
即使建立索引选择性计数还是很缓慢
举个例子,当对用户feed进行分页时,你可能会看到类似的东西,
db.collection.count({username: "my_username"});
在MongoDB,这种计数采取的数量级的时间比你希望的要长。有一个open ticke,目前为2.4,在这里,我希望希望他们可以将它弄出来。在那之前,你可以留下自己的数据汇总。在插入一个新的文档的时候,你可以在mongo中用$inccommand存储数据汇总。
副本集读取不一致
当你开始利用副本集跨集群分发读数结果,就会使自己卷入麻烦的漩涡。例如,如果你将数据写到主设备,随后的读操作可能会被指引到从设备,而从设备尚有待拷贝数据。可以用类似下面的例子来说明这一点,
// Writes the object to the primary
db.collection.insert({_id: ObjectId("505bd76785ebb509fc183733"), key: "value"});
// This find is routed to a read-only secondary, and finds no results
db.collection.find({_id: ObjectId("505bd76785ebb509fc183733")});
如果还有性能问题的话这个问题会更复杂,因为这会导致主设备与从设备之间的复制滞后,使其增长到数分钟乃至某些情况下的数小时。
你既可以控制一次查询是否运行于从设备,也可以控制在插入操作中有多少从设备执行复制操作,但是这将影响到性能,在某些情况甚至会引起永久阻塞!
范围查询被以不同顺序索引
我发现范围查询使用的索引与其他的查询有些许不同。一般在一次复合查询中,你会用关键字作为索引操作的后一个参数。然而,在使用诸如$in之类的范围查询时,Mongo在应用该范围前就应用了索引。这会导致对文档的索引是在内存中完成,而这相当的慢!
// This doesn't use the last element
// in a compound index to sort
db.collection.find({_id: {$in : [
ObjectId("505bd76785ebb509fc183733"),
ObjectId("505bd76785ebb509fc183734"),
ObjectId("505bd76785ebb509fc183735"),
ObjectId("505bd76785ebb509fc183736")
]}}).sort({last_name: 1});
在Heyzap,我们通过为这个查询在Redis中创建一个缓存层,从而绕过了这个问题。但如果在$in声明中你只有两个数值,你也可以执行同样的查询两次,或者如果你有可用的RAM,你也可以调整这个索引。
Mongo的 BSON ID 很好用
Mongo的 BSON ID给你提供了大量有用的功能,但当我我第一次使用Mongo时,我都没有了解到可以用它所做事情的二分之一。例如,BSON ID的创建时间是被存储于ID的。你可以提取出这个时间,轻松的拥有一个created_at字段!
// Will return the time the ObjectId was created
ObjectId("505bd76785ebb509fc183733").getTimestamp();
BSON ID会随时间递增,因此按id排序也就是按创建日期排序。这一列是自动索引的,所以查询起来会相当快。你可以在10gen网站 读到更多关于其内容。
索引所有的查询
当我第一次使用Mongo时,我有时候会在特定的基础环境上或从一个定时任务中执行查询。最初那些查询并没有被索引,因为不需要面对用户也不需要经常运行。然而这给别的索引查询带来了性能问题,因为未索引的查询会做大量的磁盘读操作,这影响到对未缓存文档的检索。于是我下决心要保证那些查询至少是部分索引的,以免这样的事情再次发生。
始终对新建的查询执行explain操作
显然,如果你有关系数据库的使用背景,你一定熟悉 explain操作,这在Mongo里面同样重要。当你为一个应用新增一个查询时,你应该在生产数据上运行一下查询以检查其速度。你也可以要求Mongo执行explain 来解释查询到底怎么执行的,以便于你可以检查索引之类的参数等等。
db.collection.find(query).explain()
{
// BasicCursor means no index used,
// BtreeCursor would mean this is an indexed query
"cursor" : "BasicCursor",
// The bounds of the index that were used,
// see how much of the index is being scanned
"indexBounds" : [ ],
// Number of documents or indexes scanned
"nscanned" : 57594,
// Number of documents scanned
"nscannedObjects" : 57594,
// The number of times the read/write lock was yielded
"nYields" : 2 ,
// Number of documents matched
"n" : 3 ,
// Duration in milliseconds
"millis" : 108,
// True if the results can be returned using only the index
"indexOnly" : false,
// If true, a multikey index was used
"isMultiKey" : false
}
我曾见过新部署的应用程序就因为其中的查询语句没有在生产环境中做验证而导致的整个站点down掉。做个验证是相对快速和容易做到的,所以不要找拒绝!
分析器
MongoDB自带一个非常有用的分析器。你可以根据你的需要,设定分析器只分析超过一定时间的查询。我设定是记录所有超过100微秒的查询。
// 分析所有超过100微秒的查询 db.setProfilingLevel(1, 100); // 分析所有的查询 db.setProfilingLevel(2); // 关闭分析器 db.setProfilingLevel(0);
分析器保存所有的分析数据到加了前缀的system.profile集。这和其他的数据集很像,你可以对他执行查询,例如:
// 知道最近的分析
db.system.profile.find().sort({$natural:-1});
//找到超过5毫秒的查询
db.system.profile.find( { millis : { $gt : 5 } } );
// 找到最慢的查询
db.system.profile.find().sort({millis:-1});
你可以可以通过show profile helper显示最近分析输出。
分析器本身会给每一个查询增加一些开销,但是我认为这是值得的。没有他,你会是摸眼瞎。我宁可牺牲一点点的速度开销,来让我能看到是那些查询导致问题的。没有它你根本意识不到你的查询对用户来说到底有多慢。
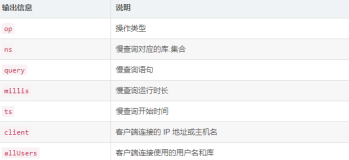
有用的 Mongo命令行
这儿是一些有用的命令行,你可以在mongo shell中运行它们,在监视你服务器状态。这些都可以脚本化,所以你可以用它获得数据,用来监控或者绘制图表。
- db.currentOp() - 显示你所有当前正在运行操作
- db.killOp(opid) - 可以用来杀掉长查询
- db.serverStatus() - 显示你整个服务器的状态,对监控非常有用
- db.stats() - 显示你选中库的状态
- db.collection.stats() - 特定集的状态
监控
经过过去一年对Mongo生产实例的监控,我列出了系列需要监控的关键阈值。
索引大小
根据你你的工作需要调整MongoD内存中合适的大小,这是必须的。以Heyzap为例,我们需要把所有的索引都放到内存里,当浏览老游戏或者用户配置时候,我们要很频繁地查询整个数据集。
通过图表化的索引大小,让Heyzap能准确的预知何时需要增加服务器,何时删除索引或者其他的方法处理来增加索引的大小。我们能够在大约一天内预知是否需要处理当前索引增长的问题。
当前操作值
图形化你mongo数据库的当前操作值,可以让你了解何时你数据库开始变慢了。如果你注意到你当前操作值的一个异常值,我就可以查找其他数据寻找导致问题的原因。是不是当时有一个慢查询?是不是访问增加了?我怎么减缓这个压力?当操作值出现异常时,对一个复制集来说常常会导致复制延迟,所以当务之急是赶紧解决由于复制集导致读到的数据不一致的问题。
索引偏差数
索引偏差产生是在MongoDB开始命中硬盘去载入一个索引,这通常意味着你的工作集不再能命中内存数据了。这个值理论上应该为0,取决于你的使用,它实际上达不到0。偶尔从硬盘载入一个索引对整体性能不会有很大的影响。你应该让你的索引偏差数尽可能的低。
复制延迟
如果你使用复制作为备份,或者你使用复制从库提供读访问,你就应该监控你复制延迟。如果你的备份滞后于主节点几个小时的话,那将非常危险。同时从从库读到延迟与主库几个小时也会让你的用户混乱的。
I/O 性能
如果你的云端上运行MongoDB,比如使用亚马逊的EBS,查看你磁盘运行的怎么样,非常有用。你可以得到I/O性能的随机下降,而且你需要把它关联到性能指标中去,比如作为一个当前操作数据峰值的解释。一些监控工具,比如iostat可以告诉你所有你需要的信息,让你了解你硬盘行为。
监控命令
有很多非常酷的应用可以用来监控你的数据库实例