本文根据DBAplus社群第94期线上分享整理而成。
讲师介绍

卢誉声
Autodesk资深系统研发工程师
-
《分布式实时处理系统:原理、架构与实现》作者。
-
Hurricane实时处理系统主要贡献者。
-
多部C++领域译作。
分享大纲:
1. 海量数据处理的挑战
2. 基础处理架构选型
3. 分布式系统结构设计
4. 性能调优和数据存储(MongoDB)
一、海量数据处理的挑战
随着互联网与计算机的普及,我们可以通过传统途径或互联网收集到大量的数据,而在日常工作中对这么大量的数据处理需求也与日俱增。日常遇到的数据种类非常多,从结构化的表格数据、到半结构化非结构化的文本图像,我们需要掌握更多的技能与工具来学会如何处理这些数据。尤其在机器学习越来越热的今天,更加有必要学会这个技术。
近两年最火的恐怕就是深度学习,而深度学习又非常依赖数据量,很多时候不管网络再怎么精心设计,再怎么使用技巧,也不如数据量来得实在。比如在我们这里,就经常需要为此处理大量的文本和图像数据。但在这个过程中,我们发现总是在做很多重复的工作。
总结一下,日常的工作模式抽象出来基本就是这么几件事:
-
将需要处理的数据输出到一个列表文件(或者存到数据库里),每一项就是一个任务。
-
处理程序中开启多个Worker线程,并为每个线程分配任务,线程执行自己的任务,并将结果输出出来。
-
处理程序还需要记录处理了哪些数据,哪些是成功的,哪些是异常的。
-
需要将这么多个处理程序连接在一起完成数据处理任务。
二、基础处理架构选型
日常工作模式:
-
为需要处理的数据建立列表
-
启动程序,开启多个Worker线程处理列表中的数据
-
将处理完的项目输出到另一个列表中
-
启动下一个程序,继续开启多个Worker线程处理列表中的数据
-
……
可以发现,这个需求其实就是一个简单的生产者-消费者模式。我们其实是在建立一个任务队列,然后让Worker来取任务并执行任务。为了简化这项工作,我自己写了一个简单的消息队列以及生产者消费者的抽象,让程序专注于数据处理的逻辑。
用户只需要建立一个MessageQueue(消息队列),一个Feeder(消息源),一个Consumer(消息处理单元),并且实现Feeder和Consumer的具体逻辑(可以使用函数对象或者lambda表达式)。这样就可以简化日常的任务,但是经过长时间的工作后,发现这样还是远远不够,还需要经常处理以下问题:
-
如何分配任务?
-
任务失败了怎么办?
-
如何保存任务状态?
-
如何分布式计算?
我们来分别看一看:
1、如何分配任务?一开始我们采取的是按序号分配任务,每个任务执行连续一批任务。后来发现这样会遇到很多问题,不如使用生产者消费者模式让Worker自己领取任务。但由于缺乏统一的调度者,因此无法确保整体具有最高的计算效率。
2、如何处理任务失败?我们一开始的方法是将成功任务和失败任务分别放到两个独立列表里,每次一个任务结束后都要重新处理失败的任务,有非常多手动工作。
3、如何保存任务状态?程序常常会因为各种原因在一半中断(未完全测试的程序可能会内存泄漏、内存越界,即使程序没有问题,也可能发生进程误杀甚至是断电等狗血的事情),因此我们需要保存任务状态,下次启动程序的时候可以自动跳过已经成功处理过的任务。
4、如何分布式计算?当数据过多时,需要手动分割数据放在几个机器上执行,部署和手动管理成本很高。
后来我们发现Apache Storm的数据处理方式很适合解决这些问题。但是非常可惜,一方面出于性能考虑,另一方面为了更加容易地调用本地C++程序,这种基于Java的方式并不是那么方便,每次还需要编写JNI来接入我们的C++代码。
于是,我们需要自己建立一套系统来解决这个问题。这套系统中包含这些东西:
-
使用NodeJS编写的网络爬虫,因为NodeJS单线程异步非阻塞,简化了高性能爬虫的编写工作。
-
使用MongoDB存储数据,因为MongoDB是文档型数据库,而且可以无模式,处理图像和网页数据的时候非常方便。
-
使用Caffe来进行训练和数据处理,由于我们的机器并不是特别多,这种情况下Caffe可以提供比Tensorflow更好的性能。
-
Hurricane实时处理系统( http://github.com/samblg/hurricane或http://hurricane-project.net),是Storm的计算模型在C++11中的实现,不过做了部分简化和调整,以适应我们自己的工作。
三、分布式系统结构设计
这里面的关键就是Hurricane这个系统:
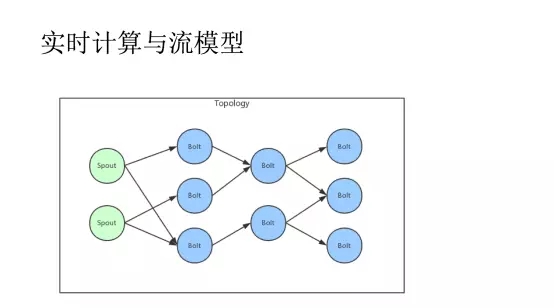
这张图就是Hurricane的计算模型,Hurricane实时处理系统是一个基于流的分布式实时处理平台,其计算模型是Topology。每个Topology都是一个网络,该网络由计算任务和任务之间的数据流组成。
该模型中Spout负责产生新的元组,Bolt负责处理前一级任务传递的元组,并将处理过的元组发送给下一级。Spout是元组的生成器,而Bolt则是元组的处理单元。每个任务都会将数据封装为元组传递给其他的任务。
在系统中任务被定义为Task。Task是对计算任务的统一抽象,规定了计算任务的统一接口。Spout和Bolt都是Task的特殊实现。为了处理这种分布式的计算模型,我们设计了自己的分布式系统架构,如下图所示:
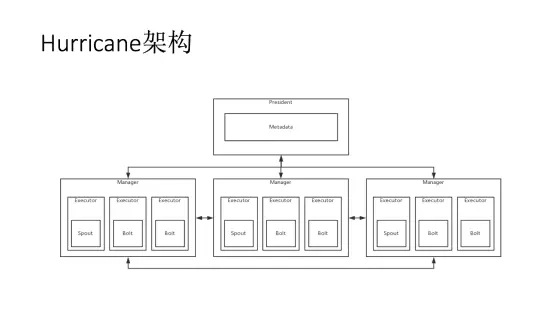
最上方的是President,这是整个集群的管理者,负责存储集群的所有元数据,所有Manager都需要与之通信并受其控制。下方的是多个Manager,每个Manager中会包含多个Executor,每个Executor会执行一个任务,可能为Spout和Bolt。
从任务的抽象角度来讲,每个Executor之间都会相互传递数据,只不过都需要通过Manager完成数据的传递,Manager会帮助Executor将数据以元组的形式传递给其他的Executor。
Manager之间可以自己传递数据(如果分组策略是确定的),有些情况下还需要通过President来得知自己应该将数据发送到哪个节点中。
在这个基础架构与计算模型之上,我们还设计了一套上层接口Squared:
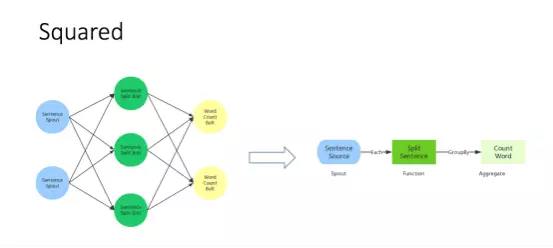
左侧是Hurricane基本的计算模型,在该计算模型中,系统是一个计算任务组成的网络。我们需要考虑每个节点的琐屑实现。但如果在日常任务中,使用这种模型相对来说会显得比较复杂,尤其当网络非常复杂的时候。
为了解决这个问题,看一下右边这个计算模型,这是对我们完成计算任务的再次抽象。
第一步是产生语句的数据源。然后每条语句需要使用名为SplitSentence的函数处理将句子划分为单词。接下来根据单词分组,使用CountWord这个统计操作完成单词的计数。
所以这个接口的本质是将网络映射成了简单的数据操作流程。解决问题和讨论问题都会变得更为简单直观,现在我们来看看Hurricane的实际应用。
四、性能调优和数据存储
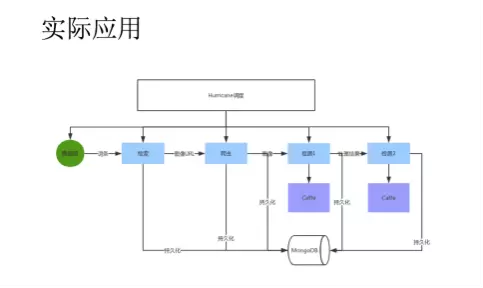
这是一个数据的预处理任务,我们需要从网络上搜索一堆图片,然后对图片做初步处理(部分检测任务),处理完成后将数据保存在数据库中,作为日后的训练数据使用。
使用Hurricane后这一切都变得非常简单。我们使用一个Spout读取数据库中的任务,每一个任务是一个词条,第一任务需要使用搜索引擎检索这些词条对应的图像URL。
这个爬取工作会通过简单的消息队列传给NodeJS,由NodeJS爬取并解析完网页,抽取URL将结果返回给Spout。然后将图像URL保存到数据库中,并传递给下一个任务。
下一个任务会调度NodeJS将一批图像都爬取并保存下来,这里大家也可以自己使用C++编写获取数据与解析数据的程序,只不过使用JS爬取数据和解析网页比较方便,因此我们把这个任务交给JS完成了。
完成任务后将图像数据传递给检测器A,检测器A完成检测后将结果和图像送给检测器B,检测器B完成最后检测任务并将数据保存在数据中。最后处理完成的数据和图像经过人工整理后将会作为日后训练数据和测试数据的来源。
最后就是系统的优化问题了。
这里很多是实际工程问题,比如在存储大量数据时,由于MongoDB自身支持分布式存储,所以处理起来非常方便。我们只需要设定副本集,然后指定分片的字段就可以建立一个分布式集群,这里比较讲究的就是要根据实际情况选择分片字段。
和传统开源的MySQL方案相比还是比较简单的,唯一不足就是MongoDB出现过宕机无法恢复的情况,所以日常额外的数据备份工作一定要进行。MongoDB不但自身支持分布式(副本和自动分片),而且还是本人使用过的检索功能最强大的NoSQL数据库之一,日常的许多业务任务都可以使用MongoDB处理。
日常使用NodeJS配合MongoDB可以快速构建足够健壮的脚本与小型服务,MongoDB也支持对单个文档的原子查找更新,合理设计后可以解决很多问题。
比如充当简单的任务队列,同时MongoDB中也可以建立全文索引,虽然没有ElasticSearch那么强大,但是已经可以满足简单的需求。最大的优点体现在处理半结构化数据、或者数据模型不确定的时候,比起需要反复修改表结构的关系型数据库来说,MongoDB实在是方便。
当然MongoDB也存在很多问题:(抛砖引玉,个人感受,如有不当,望大家指正)
-
统计功能不够强大,虽然有aggregate等功能,但比起关系型数据库来说确实羸弱。
-
无法实现连表查询,所以在设计数据模型时会和关系型数据库方式不同,也无法完全替代关系型数据库。
-
不支持事务,虽然MongoDB支持单文档的原子操作,但是无法支持包含多个操作的事务,必须要自己处理这些问题,因此很多有事务要求的系统来说不一定适用。
当然这些只是我在日常处理管理数据中的感受,也恰恰可以适应我们的工作。因为现在数据形式多种多样,需求也多种多样。只不过在我们日常的数据处理过程中,Hurricane配合MongoDB等工具可以更好地流式处理半结构化与非结构化数据。
最后,一些其他特性:
-
保序
1)根据顺序处理数据
2)使用Orderld和队列实现保序
-
多语言支持
1)C
2)Java
3)Python
4)JavaScript
Q1:Hurricane系统开源吗?
A1:hurricane real-time processing在Apache协议下开源,可以访问
http://github.com/samblg/hurricane。欢迎想了解更多内容和感兴趣的同学参与进来。
Q2:刚刚大神提到的mongo统计功能的aggregate,我们目前就遇到这问题,数据量并不大,十万左右的数据吧,现在一个统计查询要一秒多这个时间挺吓人的,有没有优化的办法?
A2:aggregate并不是mongo的强项。在编写aggregate语句的时候有许多要注意的,比如对设计到的字段尽可能建立索引,$match或者$sort之类的操作尽量放在整个操作流水线的前面。提前用$match过滤数据,减少后面数据的计算量,排序操作尽量在使用索引的字段上进行等等,如果MongoDB本身优化问题无法解决,那就只能将计算压力放在应用服务器上。尽量少地将数据分片取出到不同的应用服务器上,通过Hurricane这种实时分布式处理系统来完成统计工作,就能很好的解决这类问题---> Hurricane实时处理系统完全开源,不依赖任何第三方库,易于维护和2次开发,相较其他系统,Hurricane 十分轻量级,可维护性高。
原文发布时间为:2017-03-07
本文来自云栖社区合作伙伴DBAplus




