作者介绍
黄浩:从业十年,始终专注于SQL。十年一剑,十年磨砺。3年通信行业,写就近3万条SQL;5年制造行业,遨游在ETL的浪潮;2年性能优化,厚积薄发自成一家。
9月版本是一个大版本,上上下下都在紧锣密鼓地张罗着。
9月10日版本上线,8日开始,能明显的感觉到大战前战鼓擂动人喊马嘶的紧张氛围。项目组人头簇动,奔走如织;邮箱内,关于BUG单通报及处理意见的邮件,在这个骄阳似火的南方,犹如冷冽寒冬时北方的雪花般漫天纷飞。

14:40
主动出击
快下午三点钟的时候,一片雪花悄然飘落在我的身上:

务必搞定,全力支持,看内容,听口气,这是PM的死命令了。
虽然,我只是“全力支持”,也就意味着是“协助”性质;但是我也不敢怠慢,其一是关乎到能否下班,其二是此时已是一片混乱,都被功能BUG单弄得焦头烂额了,开发人员都无暇顾及性能问题了。如果我不主动出击,今天肯定就不能下班了。
我通读了邮件内容,发现有两项性能问题看起来是与我有关,也就是与SQL有关的,缺陷单号分别为:D6899590、D6679058。
14:48
双拳难敌四手
从描述上看,单号为D6899590的性能问题更加突出,更应急剧解决。正当我准备先啃硬骨头,主动联系相关责任人时,又来了一封邮件,内容如下:

这正是一场及时雨,浇灭了一团熊熊正燃的大火。先不管“申请”是否能得到批准,至少是一种解决问题的途径,而且可以预见,这将是一个有效途径,因为此时此刻,已经到了上线前最关键的节骨眼,只要提单人同意了,PM也不想节外生枝,多一事不如少一事,多半都是同意的。
所以,我决定将这个问题先放在一旁,全力进攻另一个问题。
当我来到开发人员座位时,开发人员正在“语音会议”中,桌面上布满了即时通讯的聊天窗口,还不时的弹出消息提醒。一边“语音会议”,一边还要文字交谈。此时我也不再忍心干扰,只是默默待在一边等待“语音会议”结束。
“关于性能的那封邮件你看到了吗?”
“我知道……哎,又被通报了……我手上还有好几个BUG单要处理。”
低沉中略带颤抖、无奈下尽显沧桑,看着这位被BUG单折腾得疲惫不堪语无伦次的小伙子,我心戚戚。
“你把这个性能对应的SQL发给我。”
“要不等下吧,这边先处理完手头的功能BUG单。”
“我这边优化也需要时间,你先把SQL给到我,我这边优化SQL的时候,你就可以同时处理其他BUG。”
14:55
这样,我拿到了对应的SQL:

15:33
意外收获-又是视图惹的祸
由于时间关系,我没有深入解读&分析SQL代码,而是直接查看了执行计划,如下:
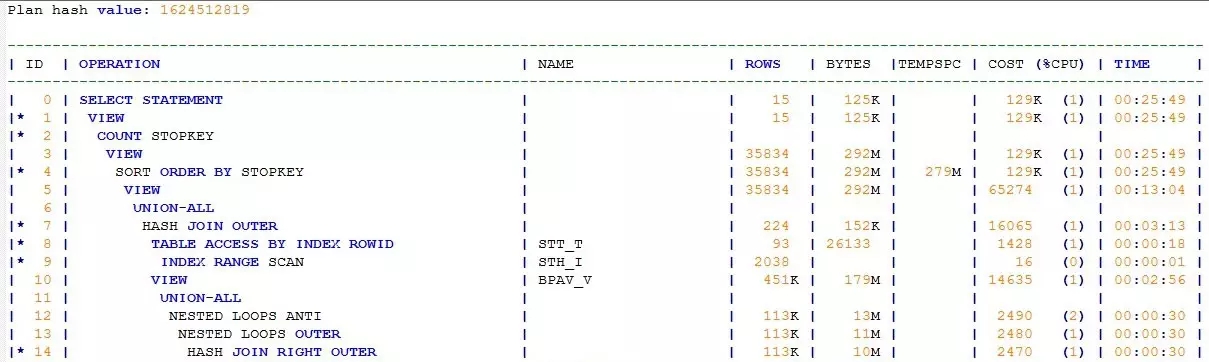
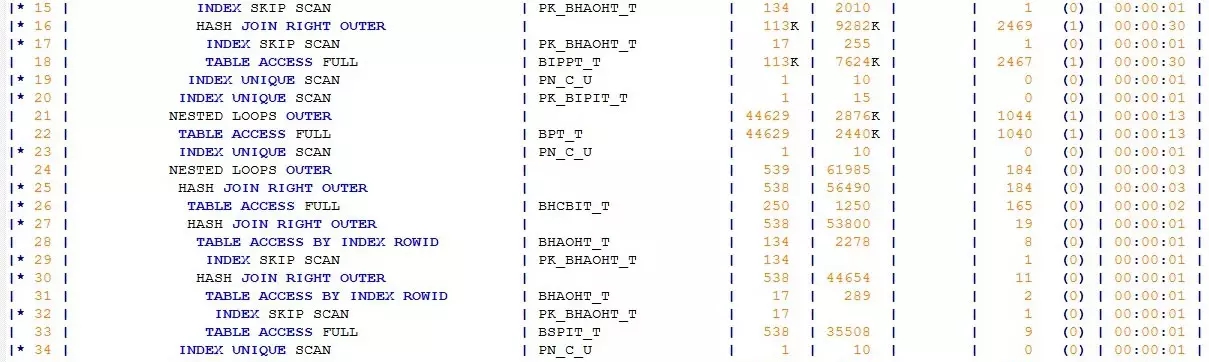
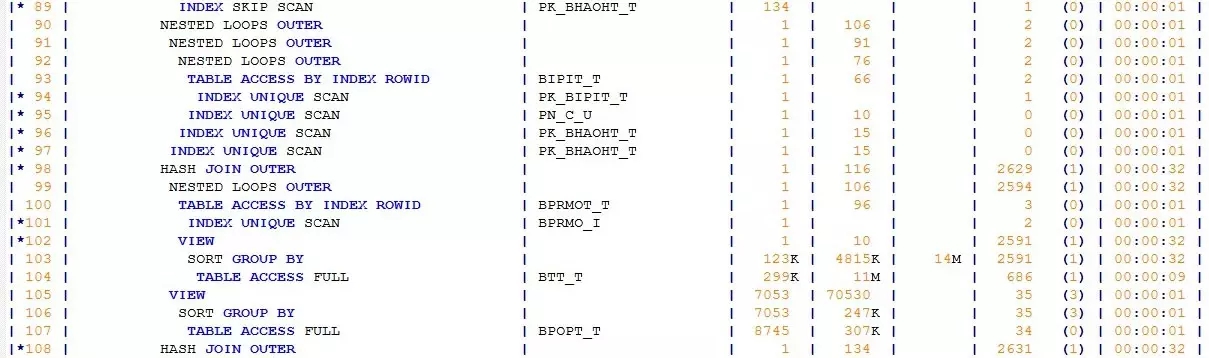
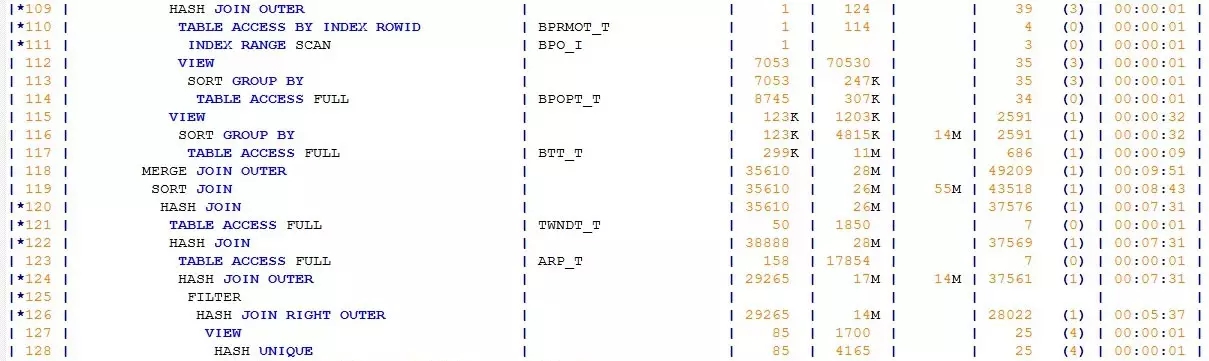
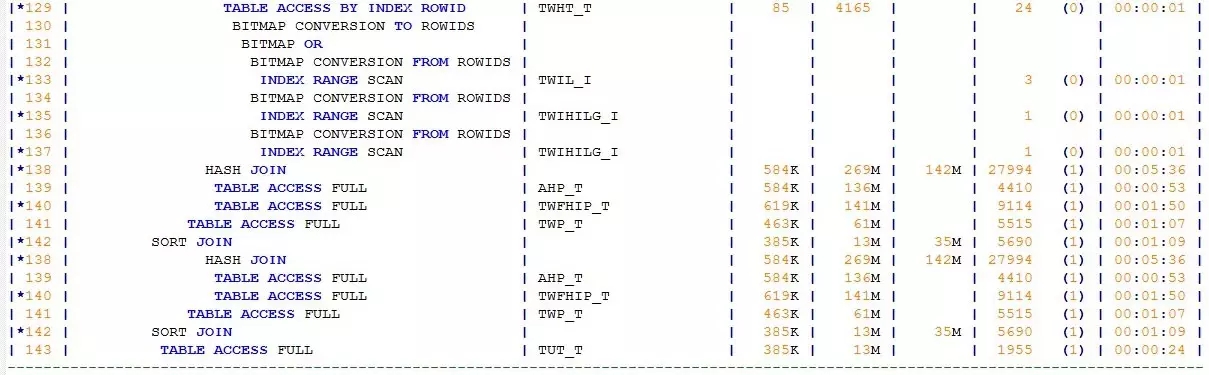
初看这个执行计划,倒也婀娜多姿、凹凸有致。但这个妙曼少女般的执行计划却隐藏着一个巨大的疑问:SQL并不复杂,表对象并不多,为何执行计划却如此“漫长”?我能想到的有两种场景会导致执行计划“变长”:其一是SQL中的OR条件被展开(CONCATENATION),其二是SQL中有视图。
果真,我在执行计划中找到了被展开的VIEW:BPAV_V,这个视图还不止被访问了一次,总共访问了两次。看到这个视图,我心窃喜。
我与这个视图曾结下了不解之缘(从《SQL优化案例之曲线救国》到《SQL优化案例之抽丝剥茧》,真可谓缠绵悱恻爱恨情仇),最终,万般无奈之下,我手起刀落,用一张表BPAT_T替换了这个“万恶”的视图。
所以,我立马将SQL视图BPAV_V改成了BPAT_T。再执行,性能从11秒变成了7秒,提升了4S。
意外收获并没有转换成的意外之喜。
相反的,来自于SE的催促邮件不绝于耳,一会儿是要原因分析,一会儿又要进度说明。此时,我咬定青山不放松,没有时间和精力去理会,相信只要能尽快将SQL优化好了,一切声音自然会消逝。所以我潜心优化,对各种邮件视而不见,对各种声音听而不闻。
15:15
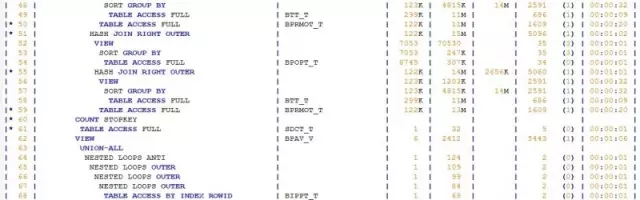
继续分析执行计划,在“千丝万缕”中,我发现了几个关键字:
CONCATENATION、MERGE JOIN OUTER、SORT JOIN,尤其是MERGE JOIN OUTER,是成本消耗较高的操作。
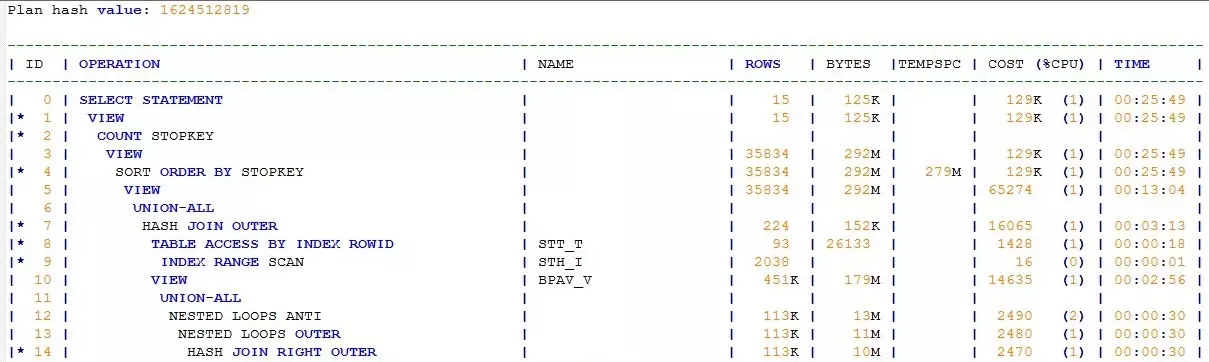
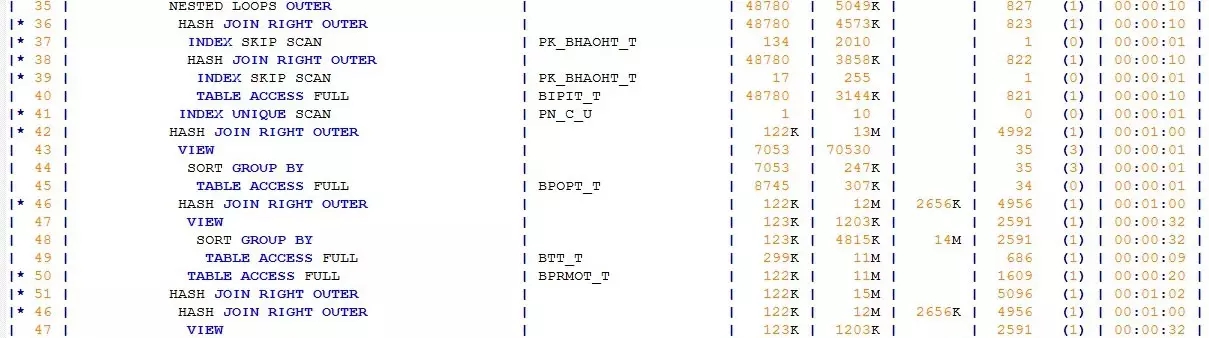
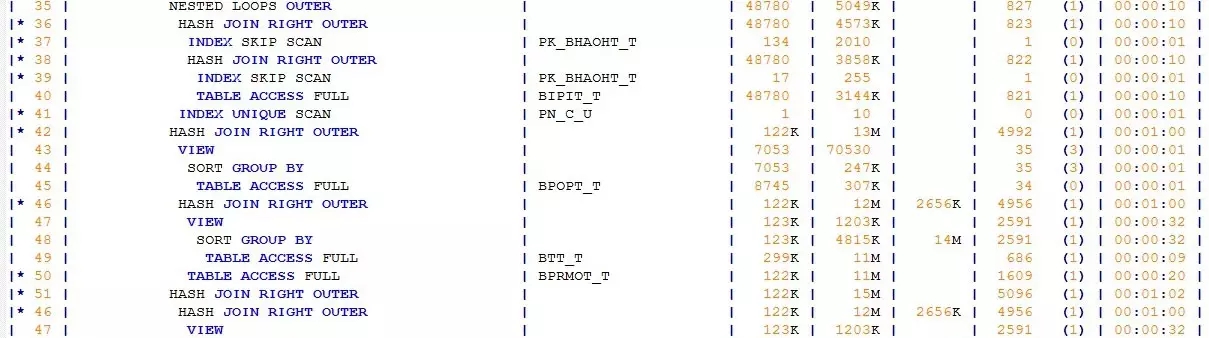
于是我重点分析了下产生这几个操作的SQL代码片段。
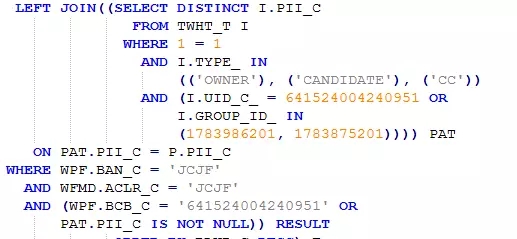
根据经验,并结合SQL的业务功能“我参与的流程”,可以判定

就是关键的过滤条件,即如下两个条件只要任意满足一个即可:
1、WPF表的BCB_C为自己的UID_C;
2、PAT子查询的PII_C不为空
这也是执行计划中出现CONCATENATION的原因所在。这应该没问题,因为通过这两个条件应该可以过滤掉大部分数据,以此过滤后的数据(小表)为驱动自然能收到不错的性能效果。
我单独执行了子查询,发现只有4条数据:
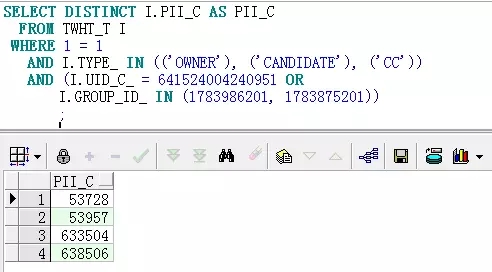
顺着这个思路,继续分析执行计划,有了重大发现:子查询PAT并没有被选为驱动表。
我尝试着用leading强制指定驱动表,但是并没有奏效。想着之前一个有关CONCATENATION的优化案例,任凭如何hint也很难改变其执行计划,当时在焦头烂额,万般无奈之下,只能将or修改成union all。这次难道也非得到这样吗?
情急之下,死马当成活马医。我灵机一动,既然希望PAT作为驱动表,而且PAT的数据量只有4条,是否可以指定其与外部结果集的连接方式为nested loop呢?
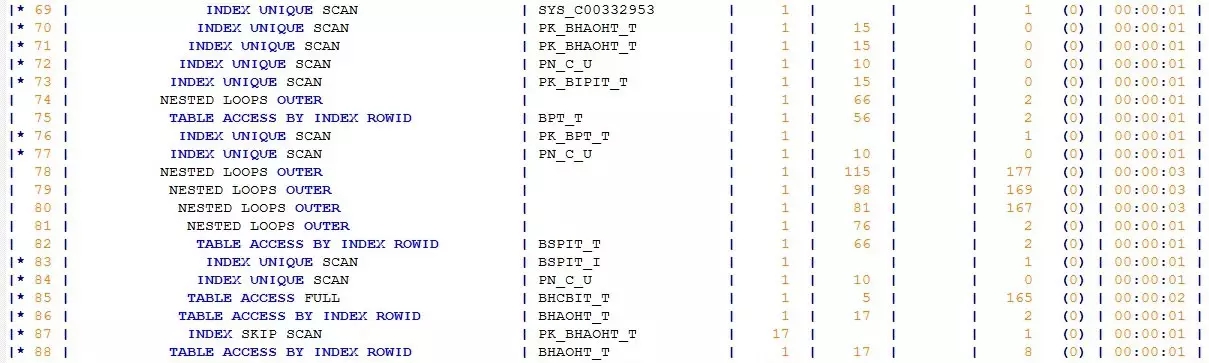
在增加了USE_NL(P, PAT)的SQL HINT后,我看了下执行计划,果然PAT子查询变成了驱动表:

看到驱动表的选择已经如愿以偿了,我也没有时间仔细分析执行计划,直接按下了F8执行,我的个乖乖,2.98S,终于进入了3S。
15:36
节外生枝
我把优化后的SQL发给了开发人员,本以为可以收工了。但是开发人员回复说:这个SQL要跑到2S内,因为这个页面除了执行这个SQL外,还需要做其他的处理,大约需要1S时间。
不怕有问题,就怕没时间
性能不达标,可以继续优化,但是做任何事情都需要时间。而现在雪上加霜的是:9月版本的代码将在16:00整冻结。
这下,留给我的时间真的不多了,原本是截止到18点的,现在冻结的时间说变就变,从18点提前到了16点,2个小时呀。
从最开始的11S到现在的3S,我已经使出了洪荒之力;即便如此,我也不能让这1S成为压垮这个性能问题的最后一根稻草,哪怕只剩下不到半小时的时间,我也要坚持到底。
或许是有更紧急的功能BUG要处理,而顾不上性能这块,到了这个时候,邮箱安静了,即时通讯安静了,仿佛整个世界都安静了下来,最重要的是,此时我的心也安静了。
再回到SQL语句,我又快速浏览了一遍,这次,SQL中的大量的CAST类型转换引发了我的兴趣。

这种转换,我未曾用过,也未曾见过。但是,有一点是可以肯定的:类型转换势必会影响到执行性能,原因很简单,转换的时候,需要逐行校验数据的合法性。
基于此,我试着取消某个字段的CAST转换,F8执行,居然报错了:
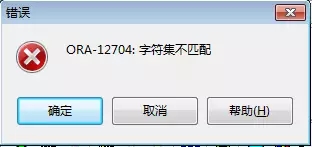
看到这个错误,再结合SQL语句,我们猛然醒悟:SQL中有UNION关键字,而两部分中,相同业务内容的字段的数据类型居然不一致,因此就需要转换。
我的第一反应就是:统一数据类型,修改表中字段的数据类型。但转念一想,统一数据类型固然可行,但是有点想当然了,因为对表结构的任何改动都存在巨大的风险,而现在时间上根本无法承受这种风险。
两眼瞅着这些鳞次栉比的CAST,心里想着谁还把TID_C这种明显NUMBER型的字段建成了NVARCHAR2,也是个人才呀。
再看这个CD_C,转换成了TIMESTAMP,这个没有必要了吧,如果CD_C本身就是date类型的话。查看了表结果,果然是DATE类型,我就果断连同后面两处同样的转换一并取消了。
不放弃,总能收获
继续往下看,接下来的一个CAST让我激动不已:
CAST('JCS' || DBMS_RANDOM.RANDOM() AS NVARCHAR2(64)) BS_ID_,
在这里居然碰到了DBMS_RANDOM.RANDOM(),天杀的,这个查询将近100万的数据量,也就是要产生100万的随机数,性能是绝对受影响的。
我试着注释掉随机函数,果真,速度杠杠的,不到2S。那么这个随机函数在这个SQL中的作用是什么呢?是否也注释掉呢?在时间上,已经不容许我深入疑问。于是我把这个疑问抛给了开发人员。由于开发人员新接手这个功能,这些细节上的问题,还需要确认。
我一边等着开发人员的回复,一边继续往下看,希望能发现更多可以优化的地方。我在NOTEPAD++编辑器中,漫无目天马行空般逐个双击被CAST的字段,当双击到STATE字段时,意想不到的情况出现了:
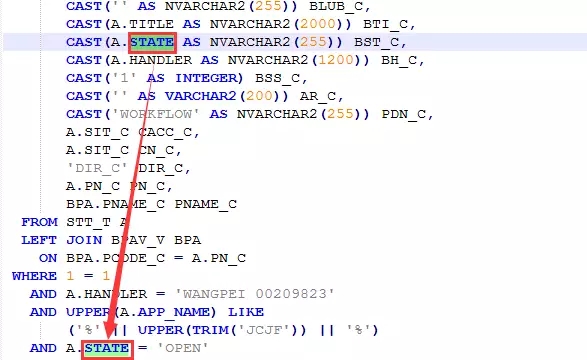
这个state字段同时也是过滤条件字段,而且只有一个值,那就意味着CAST的字段对象完全可以用常量值替代。而紧挨着的HANDLER字段也是如此。这一下子,就省略了两个字段的CAST转换。再加上前面3个CD_C,总共省却了5个字段CAST转换带来的成本开销。
此时,也收到了开发人员那边的回复:这个是为了兼容平台SQL(也就是UNOIN ALL的另外一段代码),用随机数唯一标识数据。既然是这个用途,我就决定用TID_C字段替换随机函数,因为在SQL中,TID_C本身就是唯一的。
经过这番“咬文嚼字”般的“急急如律令”,我也如释重负,相信跑进2S应该问题不大了。按下F8,1.8S。
15:40
一波未平一波又起
就在我将优化后的SQL提交给开发人员,准备发包验证时,发包人员回复:这个是平台包,每天的发包时间窗只有两个,中午12点及下午5点。
非常日期当用非常手段
眼看只有不到20分钟的时间了,此时的我心急如焚:在险象环生的海上风暴中,经历半个多小时的殊死搏斗后,九死一生,港口即在眼前,却发现锚不见了,靠不了岸。
我转问开发人员:
“你本地JAVA服务端能不能连接到测试服务器?”
“可以。”
“那就切换到测试服务器,直接在你本地验证这个性能。”
“不过我要重启服务,大概需要10分钟。”
我一边敦促开发人员切换数据库,一边联系上性能测试人员。
“由于时间关系,这个性能问题需要在开发人员本地测试,需要你过来这边”
“这不行,还没有过在本地环境验证性能问题的做法。”
“这个性能问题完全是SQL造成的。本地服务端已经切换到测试数据库了,从原理上看,在本地验证完全是等价的。”
在SE的共同努力下,测试人员从另外一个ODC赶了过来。此时开发人员的本地服务也重启完毕。
后记
惊心动魄过后,再来回顾下该案例,整个优化过程都没有出奇出意、可圈可点之处,每个优化点都是那么的平凡,平凡得让“高手”们不齿。但也就是这些平凡的优化凑在一起,化解了一场“危机”。很多人都问过我一个问题:怎样才能做好SQL优化?我想这个案例或许能给出答案:
1、驱动真的很重要;
2、让Oracle尽量少做事。
原文发布时间为:2017-02-21
本文来自云栖社区合作伙伴DBAplus


