作者介绍
王晶,中国移动DBA,负责“移动云”业务系统的数据库集成架构设计、运维、优化等工作;擅长技术领域MySQL,获Oracle颁发的“MySQL DBA”官方认证,熟悉MySQL复制结构、MHA、cluster等多种架构及运维优化。
发现故障的时间正值大年初二,在各种铺天盖地的拜年信息和微信红包之中,我发现了手机上的这条告警通知:
PROBLEM:Disaster: Galera cluster has node down。我生产环境的Galera集群有一个节点宕机了。
可能有的人不太熟悉MySQL Galera集群,下面先介绍一下出故障的集群信息。
PXC:
我们生产上用的是Percona的一个MySQL分支版本,PerconaXtradb Cluster,简称PXC,这是一个可以实时同步的MySQL集群,基于广播write set和事务验证来实现多节点同时commit,冲突事务回滚的功能。强数据一致性保证。
Galera Replication原理总结:
1. 事务在本地节点执行时采取乐观策略,成功广播到所有节点后再做冲突检测;
2. 检测出冲突时,本地事务优先被回滚;
3. 每个节点独立、异步执行队列中的WS;
4. 事务T在A节点执行成功返回客户端后,其他节点保证T一定会被执行,因此有可能存在延迟,即虚拟同步。
Galera复制的架构图:
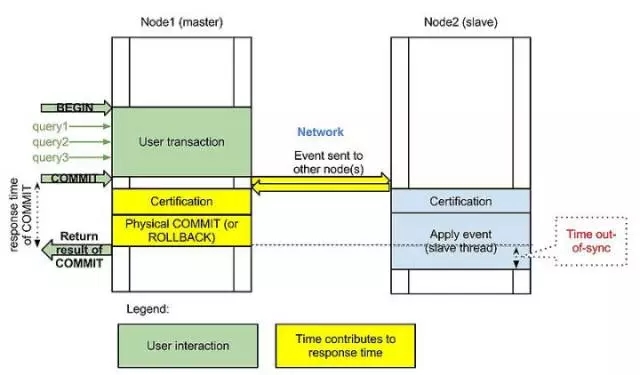
Galera flow control:
Galera是同步复制(虚拟同步)方案,事务在本地节点(客户端提交事务的节点)上提交成功时,其它节点保证执行该事务。在提交事务时,本地节点把事务复制到所有节点,之后各个节点独立异步地进行certification test、事务插入待执行队列、执行事务。然而,由于不同节点之间执行事务的速度不一样,长时间运行后,慢节点的待执行队列可能会越积越长,最终可能导致事务丢失。
Galera内部实现了flow control,作用就是协调各个节点,保证所有节点执行事务的速度大于队列增长速度,从而避免丢失事务。
实现原理很简单。整个Galera Cluster中,同时只有一个节点可以广播消息(数据),每个节点都会获得广播消息的机会(获得机会后也可以不广播),当慢节点的待执行队列超过一定长度后,它会广播一个FC_PAUSE消息,所以节点收到消息后都会暂缓广播消息,直到该慢节点的待执行队列长度减小到一定长度后,Galera Cluster数据同步又开始恢复。
搞清楚上面的背景原理之后,继续说明我的排障过程。
问题描述
1月29日早10点08分接收到Zabbix告警信息,生产环境某子系统数据库集群节点1、2分别报活跃线程数超阀值,而且不断升高。
从业务侧尝试访问了一下该子系统,发现系统页面一直无法正常查询数据及修改数据。登陆服务器查看CPU、IO、内存情况均空闲。说明累计的活跃线程过高,已经影响到业务的正常访问了。
问题分析
1、登陆Zabbix告警节点1、2查看数据库show global status like ‘Threads_running’情况发现Threads_running线程不断增高。
节点1:
| Threads_running| 100 |
节点2:
| Threads_running| 110 |
2、继续查看节点1、2数据库的show processlist的情况,发现存在很多线程停在wsrep in pre-commit stage状态(这意味着很多线程已经在节点发出commit,但将该SQL发送到其他节点是处于独立异步地进行certification test、事务插入待执行队列的状态)。这里就明了为什么会有活跃线程不断增加了,原来是线程都停留在wsrep in pre-commit stage状态。
3、进一步查找为什么会有线程一直停留在wsrep in pre-commit stage状态,show global status like ‘%wsrep%’,发现1、2节点接受队列并无阻塞,也没有发出流控。
但wsrep_evs_delayed报节点3的4567端口连接延迟。查看节点1、2错误日志发现报“WSREP: (40a252ac, 'tcp://节点2:4567') reconnecting to 67f667d2 (tcp://节点3:4567), attempt 0”。查看节点3的错误日志与wsrep_evs_delayed运行参数则报相反信息,连接节点1和节点2的4567端口延迟。
这里需要解释一下4567端口的作用(wsrep_provider_options中的gmcast.listen_addr项:主要作用是集群内监听组员状态,组员之间的通信(握手,鉴权,广播,写入集的复制)。
此时,问题原因已经明朗了,因为节点3与节点1、2的4567端口一直连接有延迟,所以在节点1、2执行的请求无法及时的复制给节点3执行,导致节点1、2的活跃线程一直执行不完。
节点1:
+------------------------------+-------------+
| Variable_name | Value |
+------------------------------+-------------+
| wsrep_local_recv_queue | 0 |
| wsrep_local_recv_queue_avg | 0.008711 |
| wsrep_flow_control_paused | 0.000000 |
| wsrep_flow_control_sent | 0 |
| wsrep_flow_control_recv | 0 |
| wsrep_evs_delayed | 节点3:4567 |
+------------------------------+-------------+
节点2:
+------------------------------+-------------+
| Variable_name | Value |
+------------------------------+-------------+
| wsrep_local_recv_queue | 0 |
| wsrep_local_recv_queue_avg | 0.006193 |
| wsrep_flow_control_paused | 0.000000 |
| wsrep_flow_control_sent | 0 |
| wsrep_flow_control_recv | 0 |
| wsrep_evs_delayed |节点3:4567 |
+------------------------------+-------------+
4、因查询数据库状态除wsrep_evs_delayed报连接延迟,其他并无异常现象,初步怀疑是网络原因造成,排查网络后,发现是因核心交换机与接入交换机之间的光模块损坏导致丢包,所以影响部分数据库集群之间的通信,才会出现以上问题。
在网络修复期间,因数据库集群节点3延迟丢包严重,被数据库集群仲裁后踢出了集群,剩余的节点1和节点2在运行了大约半小时后也因延迟丢包严重,出现了脑裂现象。
这时紧急将数据库集群3个节点关闭,然后在每个节点执行mysqld_safe --wsrep-recover命令找出最新事务号节点作为主节点启动,并在故障期间保持单节点运行。待网络故障消除后,逐一启动节点2、3,系统数据库集群恢复正常。
问题回顾
1、 在PXC环境中,如果集群各个节点的通信端口(4567)因为网络的原因出现异常(因为集群节点间通信采用的是同一网段,因此是共性的原因),应及时采取相应措施防止脑裂情况出现。例如上面故障中,因网络原因导致集群节点数从3个变为2个,这时就应该及时地关闭剩余2个节点中的一个节点,让业务只跑在单节点上,还能避免出现脑裂的情况。至少业务不会因此终断。
否则剩余的两个节点很快也会被网络丢包拖垮,会导致整个集群都停止服务,影响业务。当然在非多主的集群中也可以通过设置“SET GLOBAL wsrep_provider_options=’pc.ignore_sb=true’;”来取消集群判断脑裂的情况(多主环境中不建议使用)。
2、可以将wsrep_evs_delayed作为一个监控项进行监控,并结合网络监控进行适当的告警。
原文发布时间为:2017-02-16
本文来自云栖社区合作伙伴DBAplus




