缘起
我们都知道,当前大数据的需求基本属于遍地开花。无论是帝都、魔都,还是广州、深圳,亦或是全国其他各地,都在搞大数据;不管是不到百人的微小公司,还是几百上千人的中型公司,亦或是上万的大型公司,都在需求数据岗位。
大公司暂且不论,他们一切都走在前头。那么,对于中小型企业来说,开始尝试以数据的思维去思考问题,开始涉足大数据领域,这就是一个从0到1的过程了。
有(bu)幸(xing),近半年来,我亲自见证以及亲身体会到了这个过程,或者至今仍然在完善1这个过程中。期间,有痛苦有坑、有喜悦有成功、有沉静有反思,这是一件快乐又痛苦,同时又注定会很有成就感的事。
所以,我写下了“从0到1构建大数据生态”的系列文章,当然,目标群体仅仅是在中小型企业中,从0到1开始构建数据生态的同行们。希望,我整理的这些东西,或者说一个技术小故事能够帮助到各位同行朋友,能够给你们在某些阶段一些有用的建议或参考。限于个人的知识累积以及能力,必然会存在一些误差或者观点错误,欢迎指正与交流。
蛮荒时代
1企业为什么想起要做大数据?
一个中小型企业,为什么突然就想起要开始做数据,开始组建大数据团队呢?从目前现状来看,这是一个很正常的现象。大家都做嘛!但有没有想过,为什么大家都做?
大数据这个鬼东西怎么在四五年前一下子就火得不行了,然后在这两年更是成了香馍馍,大批大批的传统IT从业人员,纷纷转行搞大数据。这是真的,近一年来,我面试的人里,很多都是从传统行业转型到大数据的,甚至有六到七年开发经验的也毅然决然转型。这定然是市场驱动使然,有利益就有市场,有市场就有需求。
而资本市场也偏好靠数据说话的企业,甚至出现了很多以数据业务为核心的企业公司,甚至专门做数据服务的行业,一样融到了大把大把的钱。个人认为企业开始关注,甚至是涉身大数据,资本偏好只是表象,在其内层必然还有更深层的原因。
在大数据真正兴起的08、09年之前,整个互联网都是一个蓬勃发展的时代,互联网自身普及以及覆盖度的提升,互联网基础实施、电脑智能设备等进一步普及,为各个互联网企业带来了巨大的红利。
15年的时候,我跟一个创业公司的CEO聊天,他说过一句话:“当年,我那个小论坛要是能坚持做下去,现在估计早就发达了。”是的没错,当年就是随便搞个网站,只要好好搞,基本都能吸引到一大片的人,有人就能产生利益。换成更专业点的术语就是:流量红利!
那么,到了现在,流量红利早已消息不见了。面向各种人群、满足各种需求的网站、软件、APP等等,铺天盖地而来,让用户应接不暇。你需要的、你不需要的、你能想到的、你想不到的,五花八门的企业都会为你提供,你怎么选?所以,流量红利消失了!该怎么搞?
那效率和效果这个事情就不得不重视起来了,让用户更好地使用你的东西,让你的东西更精准化、让你的员工策略方案更具有效率,那么,你就更能在千千万万的类似企业中生存下去。
所以,你的企业必然需要慢慢远离“我觉得吧”“我感觉”“可能”“或者”“按道理应该”这种词语,一切回归到数据中去,让你的决策跟着数据走。
快速进行方案假设、快速进行数据反馈、快速进行策略修正、快速进行决策,让自己跑的路线更准、让自己跑的更快。
让你的用户体验更好、用得更爽,让他感觉更亲切自然,而不是你强加于其上的意志,让他被迫看你安排的东西和用既定的功能。
所以,企业慢慢开始讲究预测用户的心理,开始谈必言其“个性化”。这听起来很玄乎,但确实是实实在在的用户本质需求。因为,用户的口味也被我们各种同质化严重的应用和软件给养刁了。
于是乎,大数据大行其道;于是乎,转行者如过江之鲫。最重要的是,哈哈,它给了我一口饭吃。
2你看到的是一个茹毛饮血的现状!
在引入大数据这个概念之前,试想一下,企业的数据层面会是处于一个什么样的状况?这里我想引用原始社会的一个标志词——茹毛饮血。
中小型企业一般使用传统的数据库来存储业务数据,并且很大一部分是MySQL(别问我为什么,因为它免费啊),我想,这点毋庸置疑。而一般的中小型企业,特别是小型创业公司,基本是不配置专门的数据库工程师的,都是业务开发人员兼任。
于是乎,你会看到各种各样奇葩设计的数据库表、各种各样错综复杂数据表关系、各种各样看起来不合理其实用起来也不合理的数据存储方式。
你以为你来做大数据的,这些业务数据就跟你没关系吗?关系可大发了,你第一个要处理的数据就是业务数据。你将会忙于天天跟业务开发人员沟通交流,焦头烂额地去梳理清楚这些业务关系,甚至是转换成你要的数据形态。
然后你会不自觉地吐槽:擦!尼玛关系数据库中的数据也要做清洗呀!
其实这也是没有办法的事,历史原因使然,人力成本使然,这是我们处于0的阶段必然需要面对的东西。
在大数据这个体量中,业务数据只是占据了很小的一部分。是的,更多的是用户的行为数据,业务的访问数据。
你可能会很高兴地说,对了,不是有业务服务的LOG吗?我们可以从LOG中清洗出很多有用的Visitor数据来,一个MapReduce就搞定啦,分分钟的事。
“啊,这个呀,当时没有想到要记录下这些东西哟,没有打这些LOG。”
是不是想大喷一口血?情况好点的公司,虽然处理不了数据,但是依然是有意识地在很多业务逻辑中,埋下业务的服务LOG,落成LOG文件,待有处理能力时再做处理。
再好点的,已经有点数据意识了,开始在业务中主动埋下一些数据收集点,开始收集用户的行为轨迹数据。
但依然是把数据存储到了MySQL中,很多点位逻辑是错乱的,点位的收集目标是不清晰的(也没办法清晰,因为我都不知道要怎么用,都是提前埋下,将来可能要用而已)。
这已经很不错了,虽然点位是不准确的,虽然我不知道一天50万、100万的数据量,你的MySQL能撑几天,但好歹是有了吧,已经很不错了。
再好点的就是,已经有大数据的一到两个储备人员了,已经能够近乎的将数据以近乎正确的姿势存储到hive或者HBase中,哪怕是HDFS里头。这已经是伟大的进步了,至少恭喜你,你已经越过了0的阶段,步入0.1时代!
以上基本上就是你进入一个即将要开始做大数据的公司,所看到的东西。是不是一脸懵逼、大写加粗的尴尬?恨不得把这些乱七八糟的,一下子磁盘格式化掉。
3这个时候,你需要做点什么?
这里,我所说的做什么,不是指开始动手干,而是做之前的准备工作,算是前期工作吧。进入之后,第一时间当然是掌握如上那些信息了。接着,你需要好好跟你的老板谈一谈人生,啊不,是谈一谈他到底想干什么。
他想达到一个什么样的数据业务目标,想花多大的成本,下了多大决心去做这件事,仅仅是跟跟风、炒炒概念,还是真的想解决问题。这很重要,这关乎到你后续将投入的人力,不同阶段的规划,怎么去做这件事、做好这件事。
其实不单纯这里,其他方面也是一样的,遇到一个问题,一定是需要了解足够的信息和需求才去做的,这不耽误事,不然吃力不讨好,妥妥的。
与此同时,你需要慢慢根据蛋碎菊紧的现状以及BOSS的“伟大宏图”,去规划你的人力了。至于说人力怎么搭配,什么年份、什么水平,这就需要看“菊花”到底有多紧,“宏图”到底有多大,时间到底还有多少去思考了。
好了,背起你的锄头,去挖别人家的墙角吧,或者,刷脸的时候到了,万能的朋友圈,彰显你的威力吧!
如何拓荒
1你需要和你的BOSS好好谈谈未来!
这里我所说的BOSS,或许是你实打实的老板,或许是你的直属Leader,总之是有权力为公司数据化运营、数据化决策拍板的人。
BOSS知道要做数据这么个事,但是对于细节他肯定是不熟悉的,他只知道最终他需要达到大概什么样的目标,市场有这么个数据化驱动的趋势。那么,这个时候,在真正动手之前,你需要和他好好聊聊。
首先你需要和你的BOSS一起来拆解公司数据化的目标,你需要彻底清楚公司想把数据化做到什么程度,每个阶段大致目标是什么。
虽然,很多中小型公司把一个人当好几个人用,但是,有多少人,做多少事,这句话永远是正确的!只有在彻底地了解清楚大致的战略目标之后,你才能去拆解问题,并且根据实际的预算怎么样分阶段去实现你的数据化目标。
所以,你跟BOSS聊的时候,不是跟他谈你心目中的数据理想国,也不是他给你描绘宏图大业,而是实打实地了解公司大致会往数据投入多少人力物力,然后再根据业务目标,去拆解你所需要做的事,按阶段去做详细的规划,去储备你最需要的人才。
2背起你的锄头,去挖别人的墙角吧!
如上,做完那些事,你对于你的数据理想国,至少也是知道它的框架大致组成了。既然你需要架构它,那么,你也一定是知道你缺少什么伙伴,去把它从蓝图中构建出来。
你肯定是需要队友的,任何稍微复杂点的事都不可能独自一人去完成,能独自完成的事都是小事或者模块化的事,任何一个成系统性的事,都脱离不了团队的协作,一个组合合理、有共同理想目标的团队是最强大的。
OK,话题不扯远了,回到如何招人的问题上吧。
大数据行业从09、10年开始引入国内,到12年左右生态概念开始火爆,再到现在的如日中天,其实也算发展了好多年了,就算从11年、12年开始算,也起码正式火了四五年了。
但行业里最多依然是那种真正行业背景不到2年的人,而且很大一部分是“听闻”行情好,纷纷通过某种渠道,例如培训机构培训等转型过来的。其实这也好理解,大数据真正达到颠覆性的认知,也就在这一两年,是个企业都言必谈数据,这也算是市场需求在驱动着发展。
近一年来,从我手里过面试的人,估摸着也有二十人左右,但实际上真正靠谱的,还真没有几个。我之所以说这么多,其实是想表达一个意思,通过正规的渠道去招人,其实是很不靠谱的。那么,有没有其他办法呢?
1、刷脸
刷脸这东西,相对比较靠谱,但门槛比较高。鉴于很早期在大数据线上圈人构建技术交流圈,并且在北京组织过好几次线下的大数据交流活动,或多或少总是认识一些行业内的同行。
于是,我开始与他们挨个联系,看看有哪些有意愿回南方工作的,并且有兴趣与我一同做事的朋友。
其实,很多人或多或少都在线上,甚至是线下都交流过的,我坚信能够跟我玩在一个圈子的人,应该再差也不会比这种随机选人的几率更差吧(哈哈,自恋ing)。
所以初期,我的团队核心几个人,都是我通过线下自己的渠道找来的。我也是很感激他们能够相信我,其实我是无法保证他们的未来,但我能保证的是与我一起做事会让他们更爽点!
从这点来说,时常与他人多交流是有用的,不单纯是技术上的交流沟通,另一方面也算是自己技术人脉的累积。
对于这一点,我建议从业者有机会多认识业内同行,有机会多交流沟通,就一定不要浪费。多一个视角,多一份见识,技术需要被交流。多年来,我一直坚持一个理念就是:进步始于交流,收获源于分享!
2、线上技术圈
其实归根结底还是需要多参与技术交流,线上很多技术圈子,不管是社区也好,交流群也好,相对很多线上群体来说比较纯粹,毕竟都是搞技术的嘛!
我一直以来都认为,同等基础技术水平下,会主动寻求技术知识沟通交流的人会比那种闭门造成的人优秀,尤其是大数据这个开放而又极其需要自我增长的领域。
人类的聚群现象,能跟你玩在一个技术圈子的人,至少某种程度上来说,也是跟你类似的人。近朱者赤,这句话总是有点道理的(好像有点向自己脸上贴金的意思,哈哈)。
所以,从技术圈子渠道招到的人,相对会比较优质,最起码来说,是相对比较善于解决问题,以及与他人沟通的。不过如果需要从这些渠道招人,还是需要注意方法的。一方面是注意社群的规则,不要随意践踏,不要刷屏骚扰他人。
3规划要大,起点要低,阶段目标明确
第一,之所以说规划要大,不是说你的规划设计要超越什么BAT大公司的架构规划,而是说,你在做构架设计的时候,一定需要考虑将来可能有的扩展,为你的整体系统架构留出足够的可扩展性,而不是到时候又得推翻重做。如果是这样,那么你这个兼职架构师就可以换人了。
第二,之所以说起点要低,阶段目标要明确,是因为,只要不是土豪老板,都不可能说上来就给你配备100%的人力,马上去把你的蓝图架构出来的。投入与产出比,这是所有的决策者都需要考虑的事情。
所以,你需要把你的架构实现去做拆解,拆解成在有限的人力情况下,能够快速形成阶段性产出目标。然后逐渐完善你的架构,在适当的时候,再逐渐根据工作进度增加你的人力情况,这才是一种合理的人力规划以及整体发展方向。
4从基础开始,搭建你的数据帝国
这里先分享一张通用的数据平台架构:
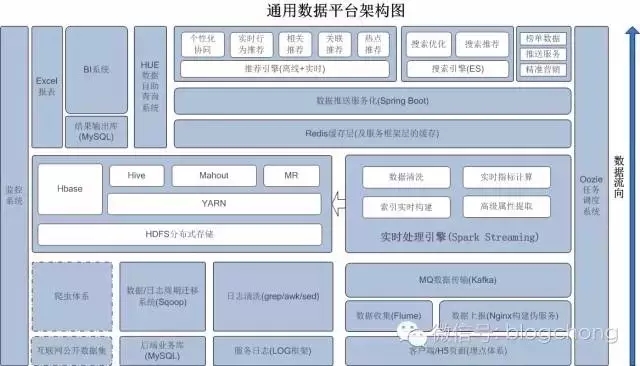
互联网行业技术无边界。在互联网行业,这种数据架构基本都是通用的,区别在于具体实现的细节,以及侧重点有所不同。
我们可以看到,这张架构图相对来说是一个比较完整通用性较强的数据平台架构,但是其包含的内容信息真的不少,数据从底层逐渐向应用层流转,实现从一整套基础数据收集到数据价值挖掘的过程。
整个过程信息量有点大,我将在后续的文章中梳理和拆解这个架构图,并细说如何拆分阶段目标,最终把这个架构蓝图绘制出来。
原文发布时间为:2017-02-03
本文来自云栖社区合作伙伴DBAplus
