在一些评估里,我们(Pinterest)的发展比先前任何初创公司都要快。大约在2011年9月份,我们的基础设施都超过负载。一些NoSQL技术导致灾难性的后果,同时大量用于读的MySQL从属服务器,产生了大量令人恼火的Bug,特别是缓存。我们重新架构了整个存储模型。令人欣喜的是,新架构还是比较有效果的,基本满足了我们的要求。
1 业务需求
-
系统总体要非常稳定,便于操作,便于拓展。我们想让数据库能从开始小存储量,能随着业务发展而拓展;
-
Pin友生成的内容必须能永久访问;
-
(支持)请求的N个Pin在板块中以确定的顺序(像按照创建时间倒序,或是按照用户特定的排序)(显示)。对于喜欢的Pin友,发Pin的Pin友列表等,也必须以特定的顺序;
-
为了简单,更新一般而言要保证最好的性能,为了获取最终一致性,需要额外的东西,如分布式事物日志。这是一个有趣(但不太容易)的事情!
2 设计原理与笔记
由于我们想要的这些数据是横跨多个数据库的,我们不能使用数据库的join,外键或者收集所有数据的索引,不过他们可以被用于不能横跨数据库的子查询。
我们也需要支持负载均衡我们的数据。我们厌恶来回移动数据,尤其是逐项移动,因为容易出错,也容易让系统变得不必要的复杂。如果我们必须移动数据,最好移动一整个虚拟节点到物理节点。
为了实现快速成型,我们需要一个简单可用的解决方案,并且在我们的分布式数据平台上,节点要非常稳定。
所有的数据都需要被备份到从节点进行高可用,并为 MapReduce 转存到 S3。 在生产中,我们只与主节点交互。在生产中,你不能在从节点上读/写。从节点是滞后的,它会引发奇怪的bug。如果你共享数据,一般来说在生产中与从节点交互是没有优势的。
最终,我们需要一个好的方式来生成一个统一且唯一的ID(UUID)分配给所有我们的对象。
3 我们如何切分数据
无论我们如何构建系统,都需要满足我们的业务要求并保证系统稳定,具有高性能,易于维护。换言之,我们需要系统不糟糕 ,因此我们选择成熟的技术-MySQL作为我们构建系统的基础。我们有意避免使用具有自动扩展功能的新技术,例如MongoDB,Cassandra 和Membase等,因为他们还不够成熟(并且他们会以无法预知的方式崩溃)。
悄悄话:我依旧建议初创公司避免使用花哨的新事物——尝试使用完全能够正常运行的MySQL。相信我,我有很多错误的实践(创伤)来证明这一点。
MySQL是成熟的,稳定的并且能够正常运行的。不仅我们使用MySQL,还有大量公司在广泛的使用。MySQL支持我们所需要的数据排序、范围查询功能并且具备行级事务等功能。它还有很多的特性,但是我们不需要或使用这些。尽管MySQL非常适合我们,但MySQL是单一解决方案,因此需要我们对数据进行分片。下面是我们的解决方案:
最开始时我们有8个EC2 服务,每个服务对应一个MySQL实例:
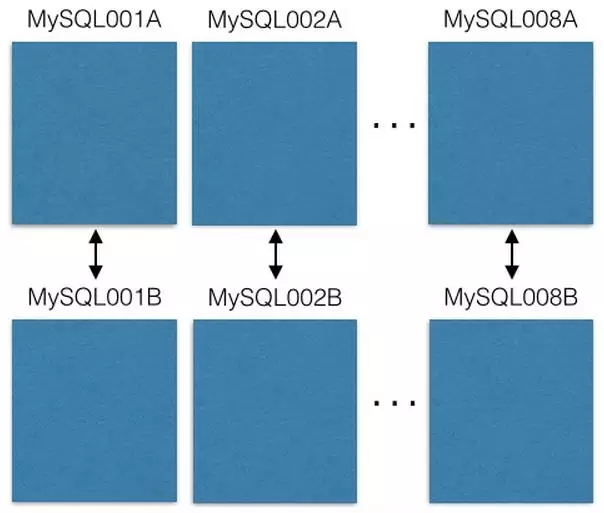
为了应对MySQL服务崩溃,每一个MySQL服务都是应用主复制模式构建,即每一个MySQL服务都将数据备份到一个备份主机上。我们的应用只读写主服务。我建议你也这样做。它简化了一切操作并且避免了复制延迟问题。
每个MySQL数据库可以有多个库:
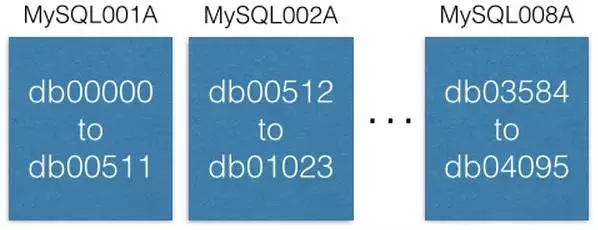
但每个库的命名唯一,如db00000, db00001, …,dbNNNNN。 每个库都是我们数据的一个分片。我们的决计决策是一块数据只在一个分片中,而不会在其它片中。然而你可以通过增加容量,以便将片移到其它机器上(后续将讨论这个)。
我们维护了一个配置表,以记录这些数据分片在什么机器上:

这个版本仅在我们需要移动分片或是替换某台机器时修改。如果主机挂掉了,我们可以将某台从属服务器升级为主机,然后再加台新的从属服务器。其配置保存在Zookeeper,更新时,配置发送到其它维护分片的MySQL服务器上。
每个分片包含相同的表:pins, boards, users_has_pins, users_likes_pins, pin_liked_by_user等等。后面我会再详细讲解。
那怎样将数据部署到这些分片上呢?
我们创建了一个64位的ID,包含了分片ID,包含数据的类型,及数据在那台服务器上(本地ID)。分片ID是10位,本地ID是36位。精明的专家对此提示只能加到62位。以前编译器和芯片设计的经验已经告诫我,预留位的长度是很重要的,所以我们有两个(设置为0)。
ID = (shard ID
给定这个Pin: https://www.pinterest.com/pin/241294492511762325/,让我们开发剖析这个Pin ID 241294492511762325:

那这个Pin对象保存在3429分片上,它的类型是1(如‘Pin’),及它在pin表的所在行是7075733。 举个例子,让我们假设这个分片是在MySQL012A.上,我们可能通过下面来访问到这个对象:

这些数据有两个类型:objects(对象)和mappings(映射)。objects包含了具体的数据,例如Pin的数据。
4 对象表
对象表存储了如Pin数据、用户数据、看板(boards)数据以及评论数据。每个对象都包含一个ID列(本地的ID,自增主键),和一个blob字段包含整个对象的JSON数据。

例如一个Pin数据:

在创建新Pin的时候,需要将所有的对象数据收集起来并生成一个JSON blob。然后,需要确定一个分片(shard)ID(我们偏向于选择与它关联(inserted)的看板的分片ID相同的ID,但是没有必要)。Pin的类型码为1。连上数据库并在Pin对象表中插入JSON数据。MySQL会返回一个本地自增ID。一旦生成了分片ID、类型码和本地ID,就可以生成完整的64位ID!
编辑Pin的时候可以在一个MySQL事务中以读-修改-写的方式修改JSON数据:
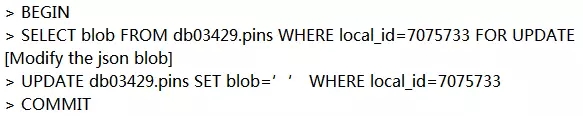
删除Pin的时候可以删除MySQL中的一行。但是更好的方式是在JSON数据中添加一个‘active’字段,设置值为false,并且在客户端上过滤到这些信息。
5 映射表
映射表用于建立对象之间的连接,如看板(board)和Pin之间的连接。MySQL中建立的映射表包含3列,一个64位的来源对象ID‘from’、一个目的对象ID ‘to’ 以及一个序列ID ‘sequence’ 。在(from, to, sequence)上建立联合索引,并且每条记录以 ‘from’ 字段的分片ID分片。

映射表中保存单向映射关系,如看板(board)到Pin的映射表‘board_has_pins’。如果需要反向的映射关系,需要建立一个独立的反向映射表‘pin_owned_by_board’。‘sequence’ 主要用于排序(分片之间是不可以比较的,因为本地ID可能相互是冲突的)。当插入一个新的Pin到看板的时候,通常可以用unix本地的时间戳作为序列号(sequence ID = unix timestamp)。序列号可以是任意的数字,但是unix时间戳是一种使新增的列处于更大的数值的便捷方式,因为时间是单调递增的。查询映射表的方式如下:

这样可以返回至多50个pin_id,再通过它们获取Pin对象。
以上的方法便是一次应用层的连接(board_id -> pin_ids -> pin objects)。应用层连接的一个杰出的特性是可以在独立于对象数据的情况下缓存映射数据。在memcache集群中缓存pin_id到pin对象的映射数据的同时还在Redis集群中缓存board_id到pin_ids的映射数据。这样就可以实现与缓存数据更匹配的缓存技术。
6 扩容
我们系统有三种主要的扩容方式。最简单的就是升级机器(容量更大、速度更快的硬盘,更多内存,任何成为瓶颈的部分)。
第二种方式是开启新的分片范围。虽然我们的分片ID是16位的(最多64k个分片),但是一开始我们只创建了4096个分片。新建的对象只能存储在开头的4k个分片。某天我们决定添加新的MySQL服务器用来存储4096到8191的分片,并且开始填充数据。
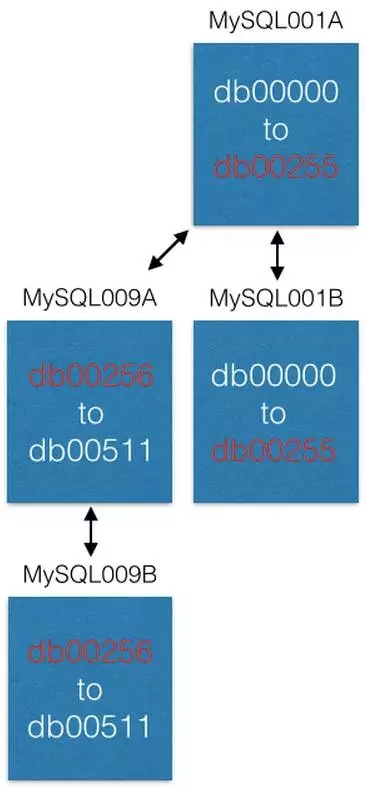
最后一种方式是将一些分片移动到新的机器上。例如需要对MySQL001A(存储着0到511分片)扩容是,先新建一对主从节点(译者注:此处原文为“a new master-master pair”,可能为笔误),命名为最大的编号(比如是MySQL009A和MySQL009B),然后开始从MySQL001A复制数据。
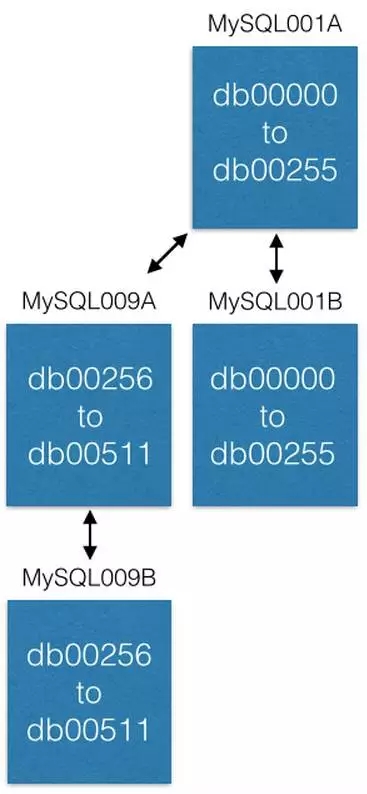
当复制完成时,改变配置,使MySQL001A只存储0到255分片,MySQL009A只存储256到511分片。现在每个服务器只处理原先一般的数据量。
7 一些优点
如果你曾构建过生成UUIDs的系统,你会发现这个系统可以轻松地实现这个需求!当你创建一个新的对象并插入到数据库的时候,会得到一个本地ID。这个本地ID和分片ID、类型ID组合便可得到一个UUID。
如果你曾用ALTER命令为MySQL数据表添加过字段,你肯定知道这种操作十分缓慢而且十分痛苦。本文的方法不需要任何级别的MySQL Alter操作。在Pinterest的过去三年中,我们可能完成了一次Alter操作。给对象添加新的字段只需要让那些服务知道JSON模式中添加了几个新的字段。当反序列化一个JSON对象的时候如果没有某些字段,此时便可以返回预设的默认值。如果需要新的映射表,只需要创建一个,然后在需要的时候填充数据就可以。完成这些事情就可以发布新产品了。
8 取模分片(Mod Shard)
取模分片和 Mod Squad(译者注:一部电影)是一样的,唯一的区别是它们完全不同。
有一些对象并不是通过ID查询的。比如一个Pin友用Facebook账号登录的时候,我们需要将Facebook的ID映射到Pinterest的ID。Facebook的ID在我们看来就是比特位,所以我们将他们存储到一个独立的分片系统中,并命名为取模分片。包括其他诸如IP地址、用户名、邮箱地址等。
取模分片正如和上文中的分片系统类似,除了它们可以以任何数据查询。对查询输入取hash然后以系统中总分片数取模。结果就是数据将被存储或已经存储的位置,如下:
shard = md5(“1.2.3.4") % 4096
此例中shard 值会被赋为1524。类似ID分片,需要维护一个配置文件,如下:

则,查询一个IP地址1.2.3.4的方式,如下:

但是会因此而失去一些ID分片优势,比如空间分布(spacial locality)。一开始就必须创建好所有分片,并且手动创建分片ID(并不能自动生成)。系统中的所有对象都最好有一个不变的ID。只有这样当一个用户修改他的用户名的时候才不用去更新那些关于这个用户名的引用。
9 最后的一些想法
至今为止,这个系统在Pinterest已经在线上使用了3.5年了,似乎还会一直用下去。实施这样一套系统相对比较直截了当,但是保持运行并将全部数据从旧机器迁移过来还是相当困难的。如果你在初创公司并且承受着数据增长的痛苦,然后你构建了新的分片机制,并且考虑构建一套集群用于在后台执行脚本把旧数据库的数据迁移到新的分片机器(提示:可以用pyres)。可以肯定的是,无论你做怎样的努力,数据丢失都是不可避免的(我敢肯定它是系统中的捣蛋鬼),所以要一遍一遍重复的迁移数据直到写入新系统的迁移数据为0或者数量小到一定程度。
这套系统是最大努力的交付。它没有保证原子性、隔离性和一致性。听起来很糟糕,但是不用着急,因为这些保证可能并不是必须的。如果需要的话,可以在其他的过程或系统中实现这些特性,但是你能直接获得的好处是,这个系统刚刚好可以正常运行。通过简洁可以得到好的可靠性,并且运行起来相当快速。如果你还是担心原子性、隔离性和一致性,请联系我。我可以帮助你解决这些问题。
关于故障恢复怎么样呢?我们构建了一个维护MySQL分片的服务。我们把分片配置信息存储到了ZooKeeper。如果一台master服务器宕机了,可以执行一些脚本,将slave升级为master,然后再开启一台替补服务器(包括数据同步)。直到现在我们也没有使用自动的故障恢复。
本文来自云栖社区合作伙伴"DBAplus",原文发布时间:2016-11-01
