1. 分布式调用系统的现状
当前,随着互联网架构的扩张,分布式系统变得日趋复杂,越来越多的组件开始走向分布式化,如微服务、消息收发、分布式数据库、分布式缓存、分布式对象存储、跨域调用,这些组件共同构成了繁杂的分布式网络。
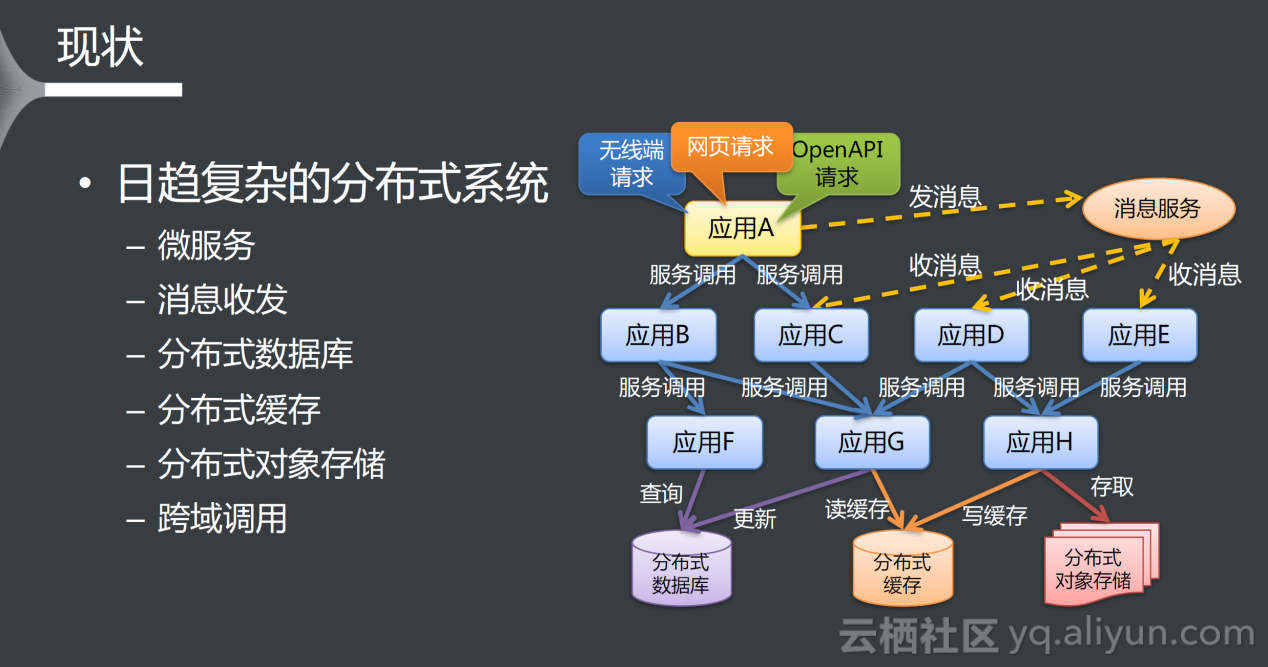
如上图右侧所示,当应用A发出某个请求时,其背后可能有数十个甚至更多的服务被调用,可谓是“牵一发而动全身”。
如果将分布式系统比作高速公路网,每个前端的请求就相当于高速上行驶的车辆,而处理请求的应用就是高速上的收费站,在收费站上将车辆通行信息记录成日志,包括时间、车牌、站点、公路、价格等,如果将所有收费站上的日志整合在一起,便可以通过唯一的车牌号确定该车的完整通行记录;分布式调用系统跟踪和监控就是类比这种思想,对每一次请求进行跟踪,进而明确每个请求所经过的应用、耗时等信息。
阿里巴巴的分布式调用跟踪实现——鹰眼
阿里巴巴中分布式调用跟踪是采用鹰眼(EagleEye)系统来实现的,鹰眼是基于日志的分布式调用跟踪系统,其关键核心在于调用链,为每个请求生成全局唯一的ID(Traceld),通过它将不同系统的“孤立的”调用信息关联在一起,还原出更多有价值的数据。
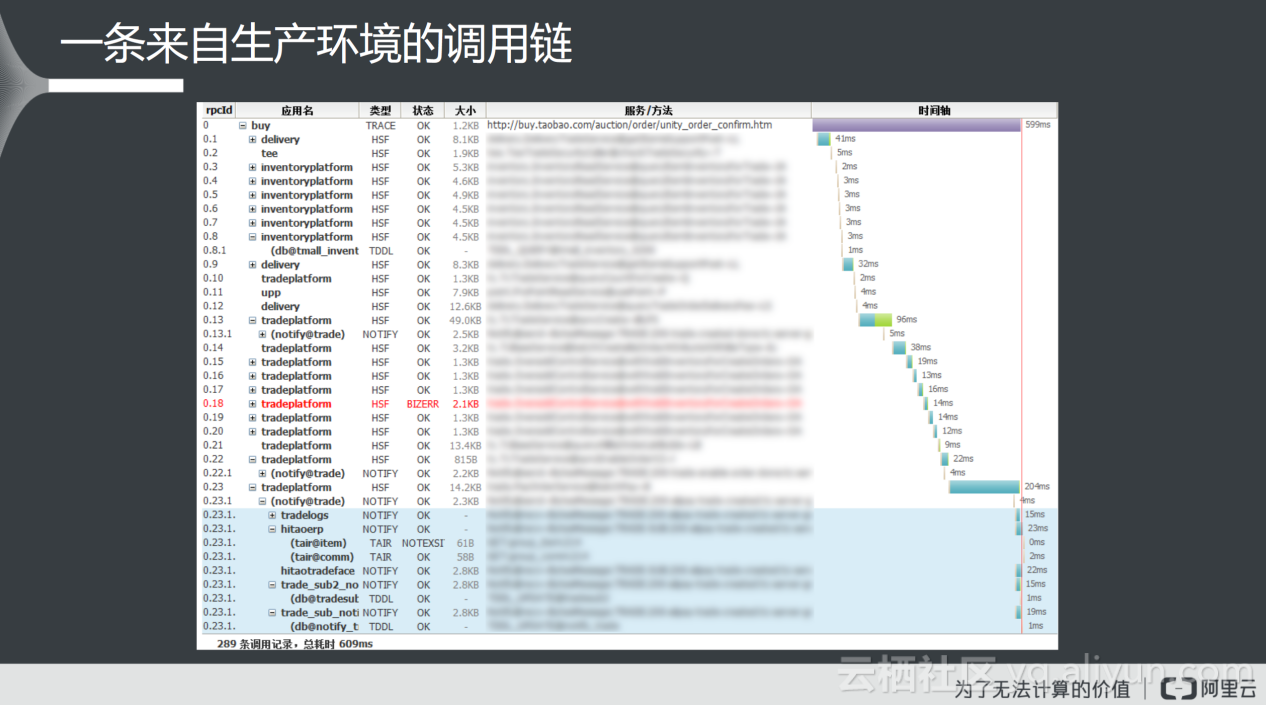
上图是一条来自生成环境的调用链,在应用名列可以看到请求中间过程所经过的一系列应用,可以看到最先经过Buy应用,后续调用delivery、tee、inventoryplatform等,形成调用树(树上的缩进表示嵌套关系),从调用树上很容易看到前端请求的完整处理过程。
另外值得注意的一点,上图是由白色背景和蓝色背景组成。其中蓝色背景表示调用链经过消息之后,变成了异步的消息通道,其后续处理过程也都是异步处理过程;白色背景处表示同步过程。一般而言,对于前端的用户等待的时间是不包含蓝色背景内的耗时,也就是只包含了同步处理的时间。
在上图所示的页面中也清晰地展示了每块应用处理请求得具体耗时,非常直观地进行定位;此外,状态信息也是值得关注的一点,如上图所示,如果在调用过程中发生错误,就会出现异常(图中红色区域所标注),通过点击状态码,用户可以查看错误的具体信息。
鹰眼于2013年在阿里巴巴内部上线,目前支撑阿里集团泛电商、高德、优酷等业务,技术层面覆盖前端网关接入层、远端服务调用框架(RPC)、消息队列、数据库、分布式缓存、自定义组件(如支付、搜索SDK、本地方法埋点等);2016年在阿里云的中间件云产品EDAS发布,对外提供服务;此外,鹰眼也支持私有云输出。
2. 使用场景
下面来具体看一下调用链的具体使用场景。
定位异常、耗时问题
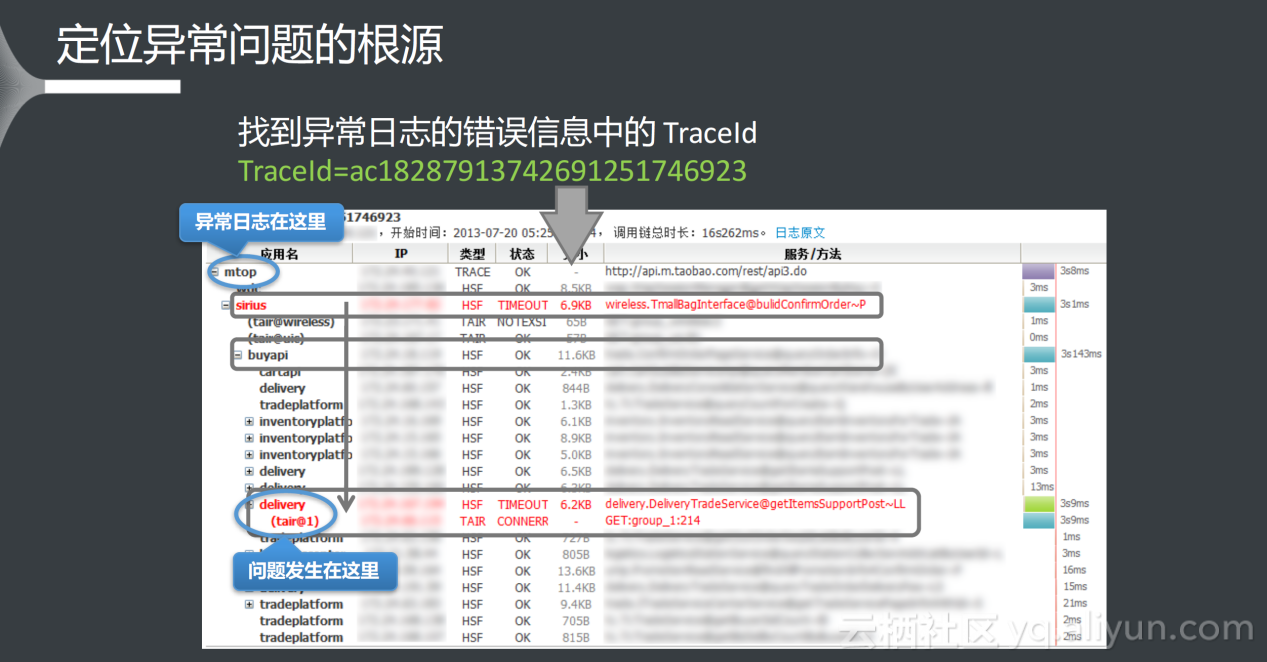
可以在业务异常日志的错误信息中找到Traceld(如图中的TraceId=ac18287913742691251746923),之后在鹰眼系统中只需要输入Traceld,就可以看到调用链中具体的情况,在调用链上更加直观地定位到问题(如上图所示),层层排查后确定问题的所在。
带调用链下钻的监控报表
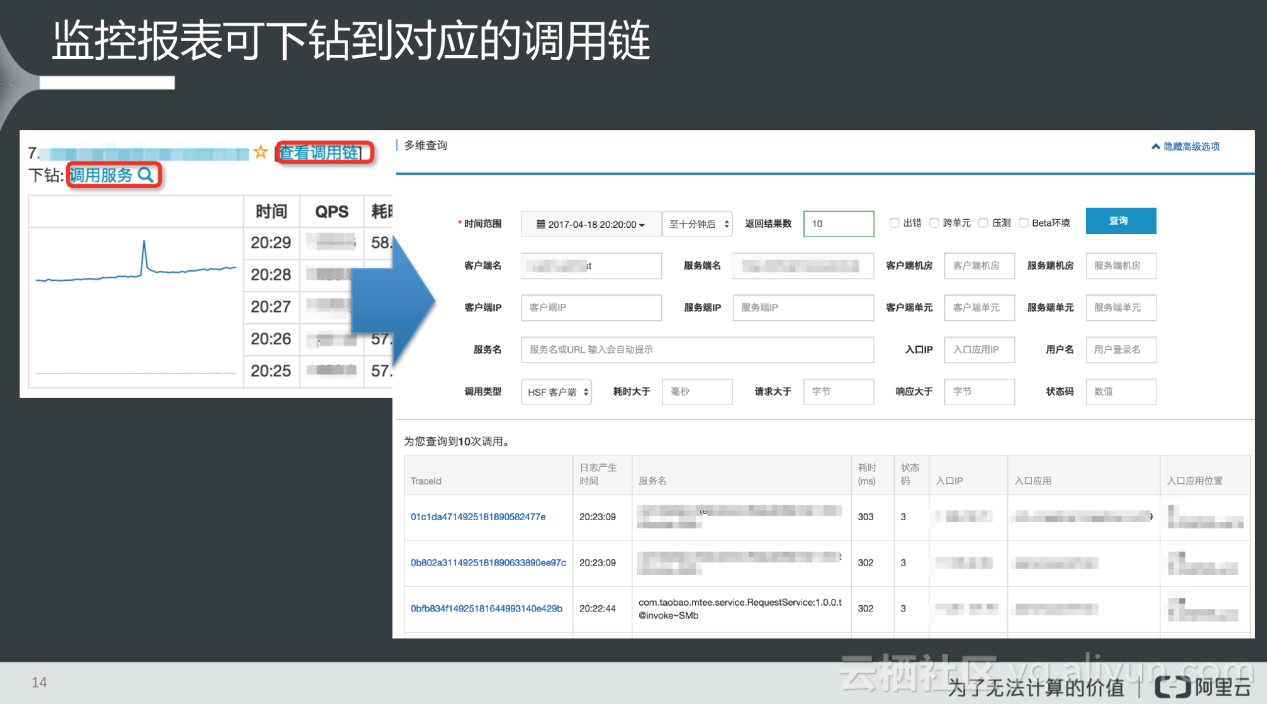
对于分布式调用跟踪系统而言,它并不仅仅提供了调用链这一功能,因为它对所有中间件的调用做埋点,所以中间件上的所有情况都可以监控的到。因此,在形成调用链的过程中也会形成一份详细的调用监控报表,它与其他监控的不同之处在于:该监控报表是带有上下钻取功能的报表。因为调用链是详细的底层统计,对上可以形成的报表维度是非常丰富的,在上图所示的调用报表里,不仅可以看到服务的情况,还可以下钻到它所调用服务的情况;另外从监控报表上还可以进行调用链的下钻,查看清晰的调用链信息。
链路分析
链路与调用链不同,链路是一个统计学的概念,而调用链是单体调用的过程。分析链路的价值主要体现在以下几点:
- 拓扑形态分析:分析来源、去向,识别不合理来源;
- 依赖树立:识别易故障点/性能瓶颈、强依赖等问题;
- 容量估算:根据链路调用比例、峰值QPS评估容量;
下面来具体分析这三点。
A. 拓扑形态分析:分析来源、去向,识别不合理来源
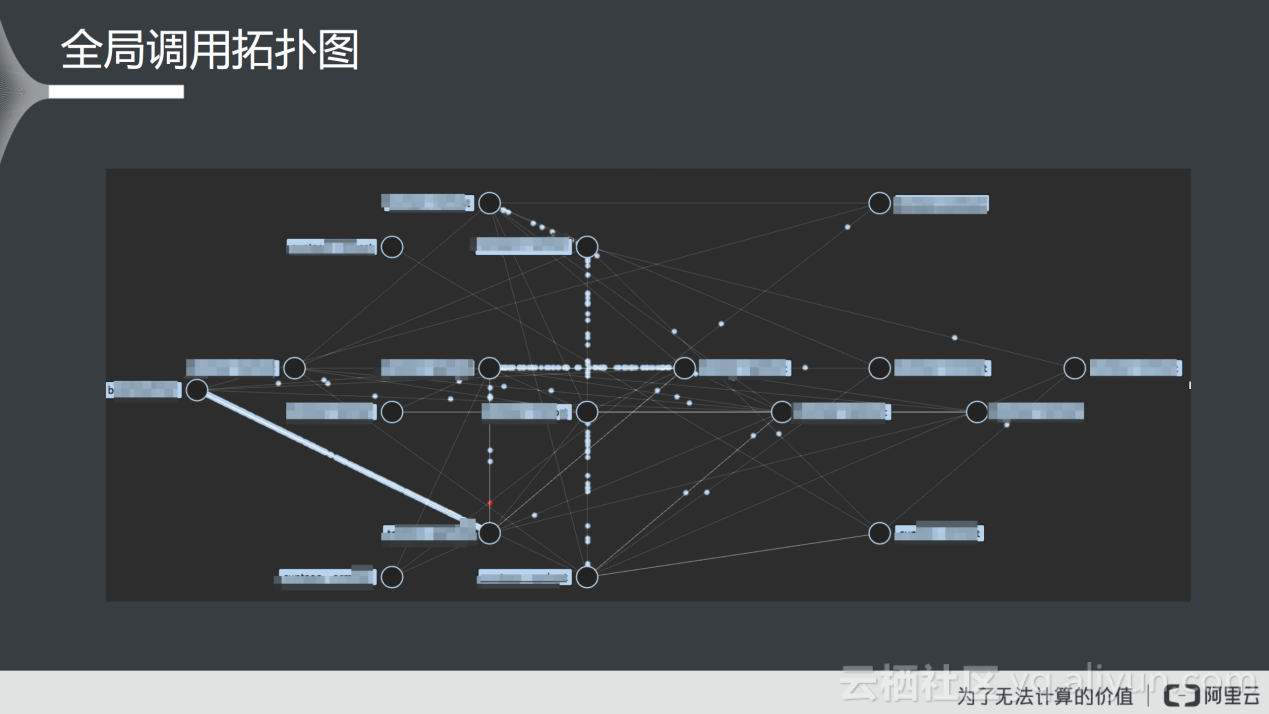
上图是全局调用拓扑图,可以明显的看到不同的应用之间存在复杂的调用关系,也可以查看某个应用和其他应用之间的调用关系以及调用的频次;图中红点表示在调用过程中出现错误。
通过该拓扑图,架构师可以清楚地观察到系统上的调用情况,此外,点击全局调用拓扑图上的某个节点,可以下钻到下图所示的单应用链路拓扑图。
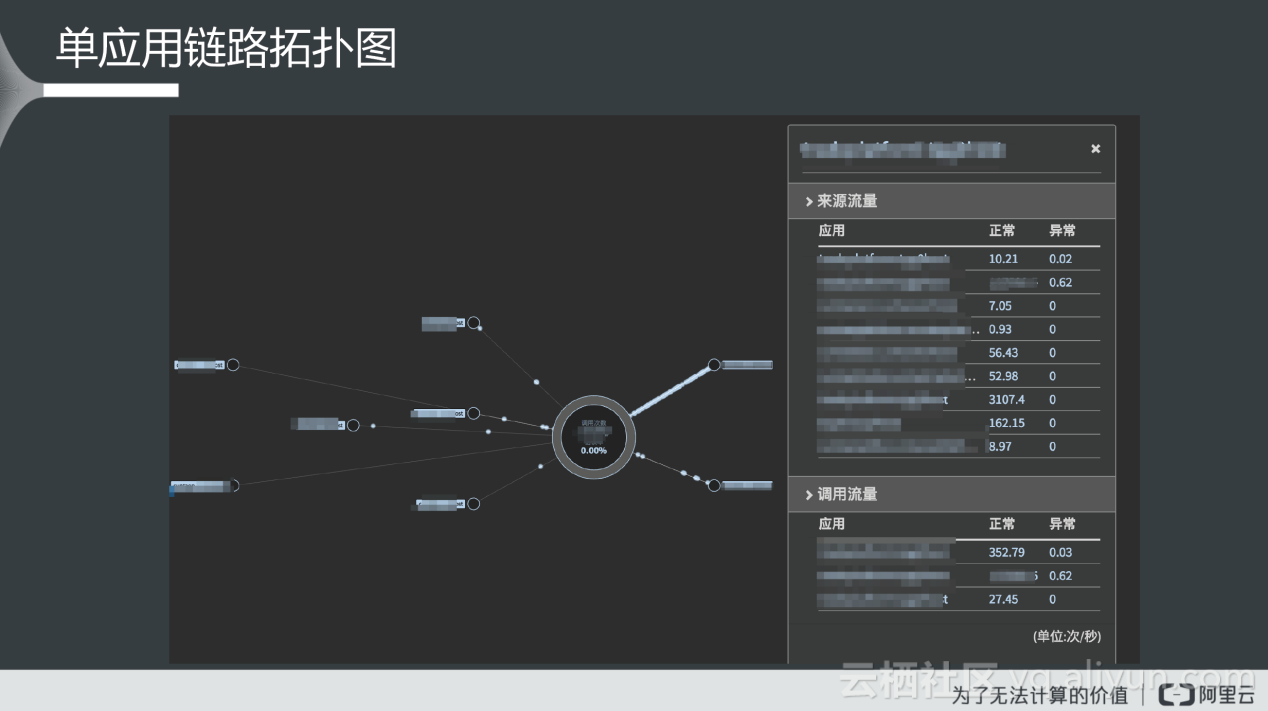
在以某应用为中心的单应用链路拓扑图,可以查看该应用在调用链上下游的应用之间的具体调用关系。
B. 依赖梳理和容量估算
链路分析除了进行拓扑形态分析之外,还能进行依赖梳理:识别易故障点、性能瓶颈、强依赖等问题;也可以根据链路调用比例、峰值QPS 评估容量。
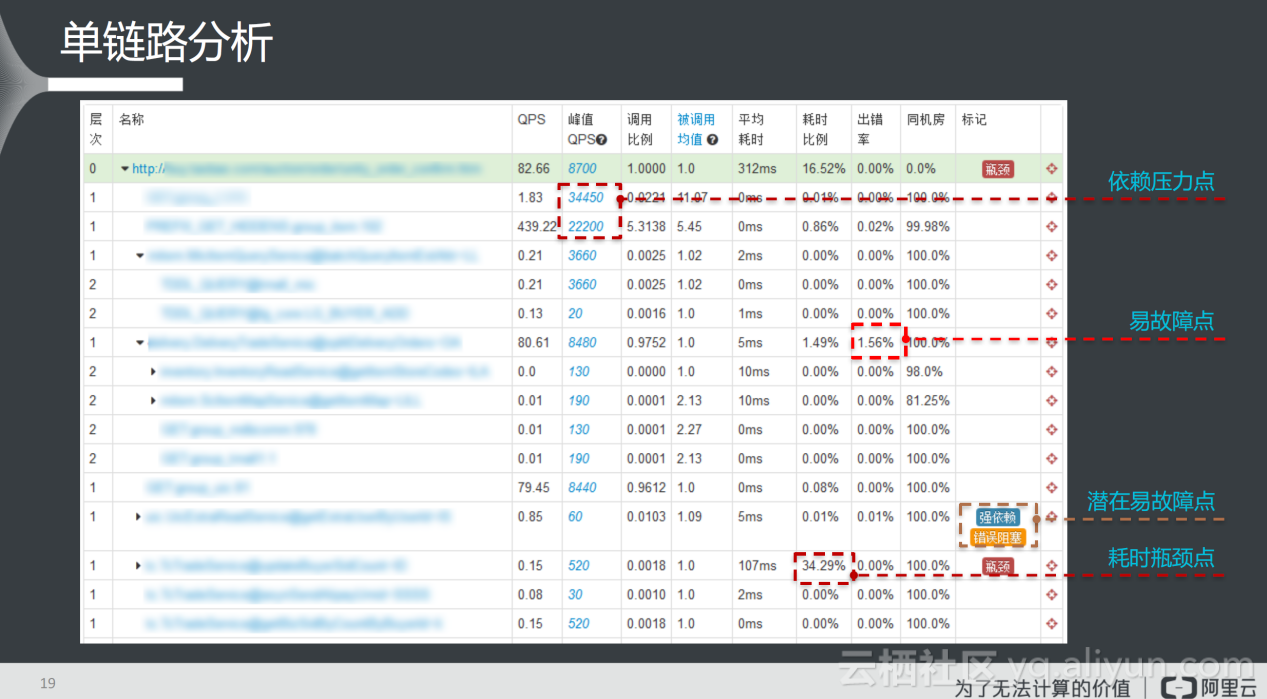
上图是一份单链路报表,单链路报表是指同一HTTP入口的调用链叠加形成、包含所有依赖情况的调用关系。上图左侧模糊部分是一棵调用树,它表现了应用之间的依赖关系,与调用链不同的是,这种依赖关系是统计学意义上的依赖,因此在该报表上包含了QPS和统计QPS统计类型的数据。在进行容量预估时,可以很容易分析上游应用对下游造成的压力。
在该报表上,还可以进行依赖梳理方面的工作,根据出错率确定易故障点;此外,那些存在强依赖、错误阻塞的地方都是潜在故障点;最后,还可以根据耗时比例进行相关的性能优化。
3.最佳实践
调用链作为排查问题的核心,通过其可以将各类数据关联在一起,提高问题排查能力。下面来看一下调用链的最佳实践——全息排查。
全息排查
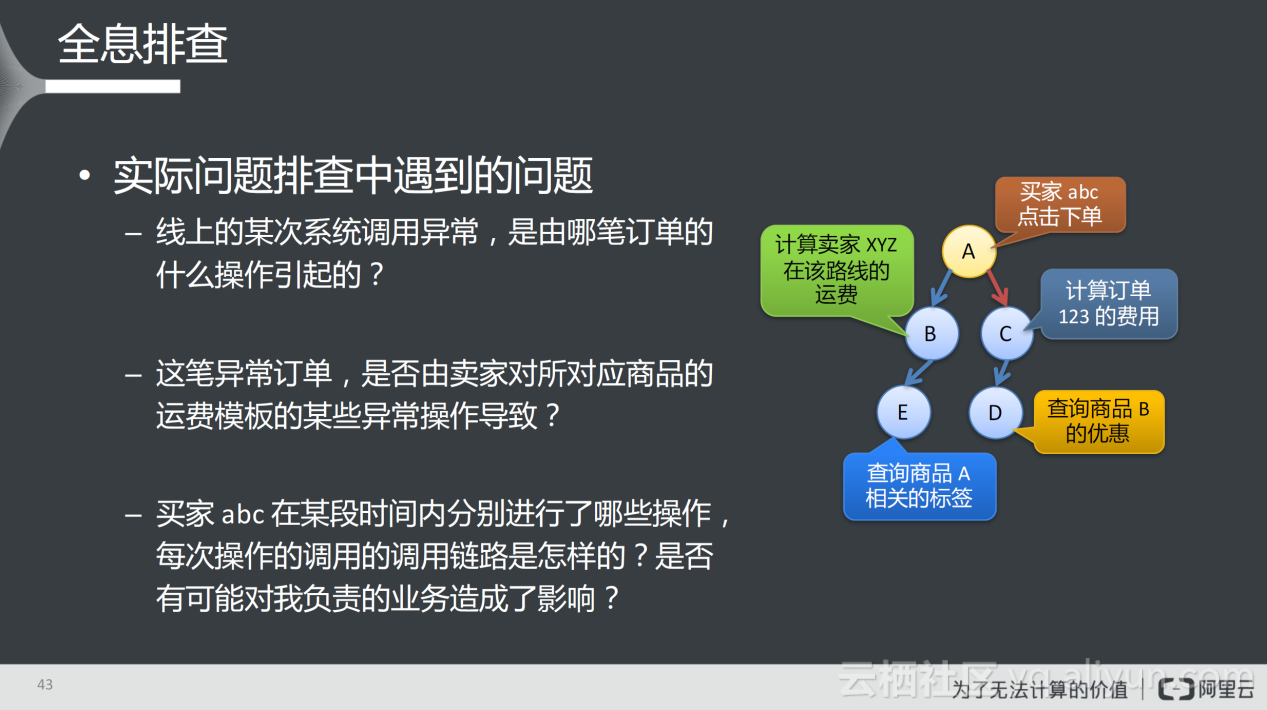
在实际问题排查中经常会遇到上图所示的问题,这些问题都具有明确的业务含义,这些问题尽管看上去和调用链并无关系,但可以用调用链得到很好的解决。如上图右侧所示,A-E五个节点在调用链上承载的调用关系实际上都是一些具体的业务,例如节点A处理HTTP请求表示卖家abc点击下单;在调用B时其实在计算卖家xyz在该路线的运费等等。在排查问题时,最有价值的切入点在于先从业务问题出发,再进一步在调用链中确认问题所在之处。
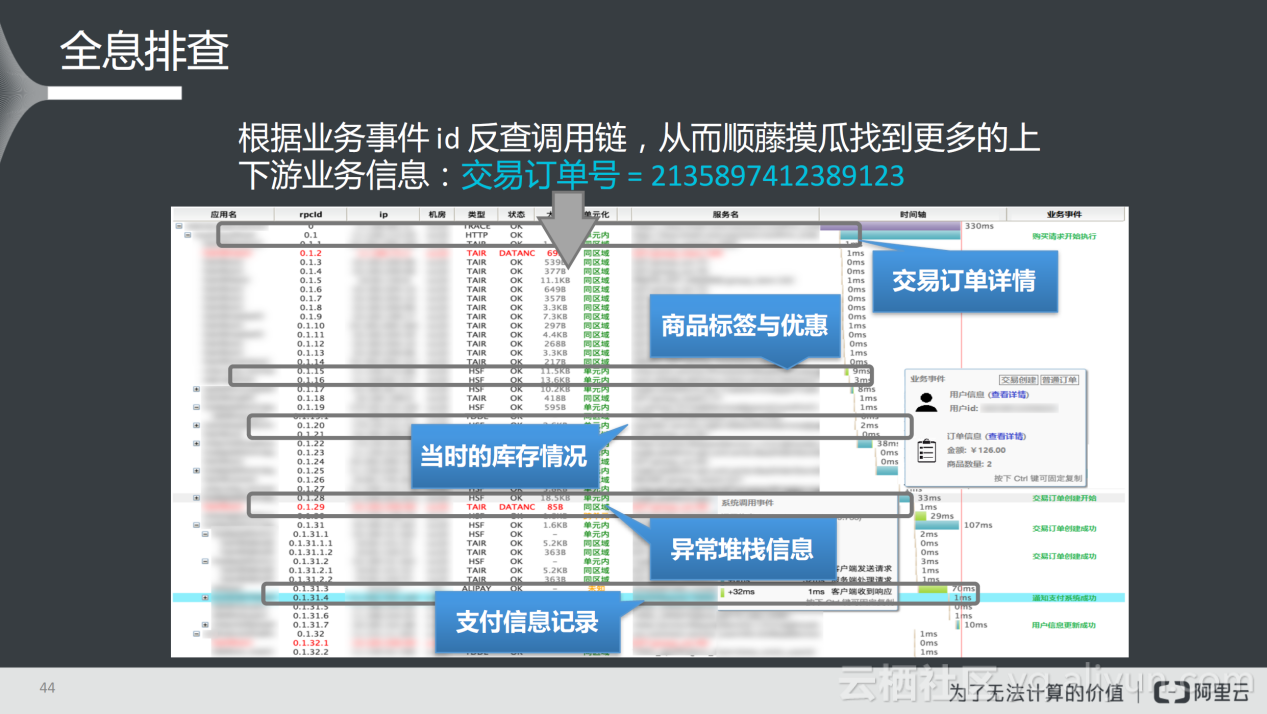
我们可以根据业务时间ID反查调用链,从而顺藤摸瓜找到更多的上下游业务信息。例如一个交易订单(2135897412389123)发现存在问题,我们可以根据订单号查到与之绑定的TraceId,根据TraceId不仅可以查看系统调用的事件,还可以看到与业务相关的事件,如用户下单、当前库存情况等,也就是说根据交易ID可以在调用链上查看交易、商品库存以及支付等信息,大大提升错误排查速度。

回到刚才提到的三个问题:要分析由哪笔订单操作引起的调用异常其实是TraceId到OrderId的一次关联;要分析异常订单是否由卖家对所在商品的运费模板的某些异常操作导致其实是根据OrderId关联ItemId再关联TemplateId,最后关联到TraceId;对于第三个问题,通常是由UserId关联到TraceId再关联到MyBizld。
根据这些问题及其解决方案可以看到,全息排查的关键在于:业务时间id与TraceId/RpcId的双向绑定。
常见的双向绑定有三种实现方式:
- 在调用链的Tags 或UserData 中放入业务事件id,从而建立调用链到业务事件id 的关联;
- 打通TraceId 到数据库的数据变更的关联,从而建立调用链到每次数据变更的关联;
- 在业务日志中记录TraceId、业务事件id 等信息,从而建立调用链与业务事件日志的关联。
目前,基于阿里云ARMS集成了上述三种双向绑定实现方式,用户可以在产品上轻松配置搞定。
全息排查全景图
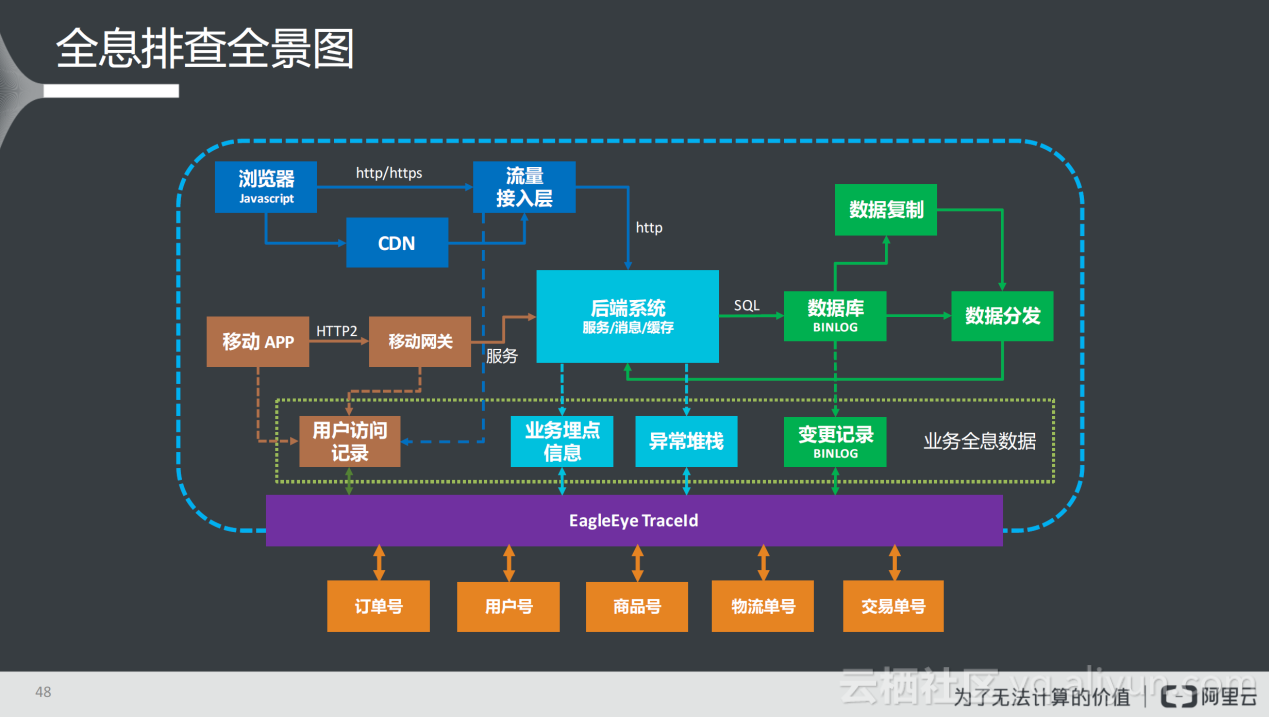
上图是阿里巴巴内部的全息排查全景图。该图的核心部分是鹰眼最初覆盖的的后端系统,包括服务、消息和缓存;在前端层面涉及前端用户访问日志,具有关联TraceId的能力;在移动端也具有关联TraceId的能力;通过对TraceId进行关联,可以打通用户访问日志;在数据库层面,通过SQL语句将TraceId传到数据库的binlog中,在数据复制和数据分发时可以非常容易获取到每次数据变更的记录与TraceId的关联;另外,业务通过自身的业务日志和异常堆栈也可以打印TraceId;这样一来,业务层、移动端、前端、数据层所有的组件都与TraceId进行了关联,再关联上业务中的订单号、用户号、商品号、物流单号、交易单号,最后形成一个非常强大的生态——从一个调用链可以看到上下游相关的订单、用户的详细信息,同时可以根据订单查到与该订单相关的业务ID,再根据业务ID扩展到与其相关的更多ID,甚至是TraceId,最后形成TraceId-->业务ID-->新的TraceId的网状结构,将排查问题转化为从网状结构中寻找需要的整段信息。
通过EDAS+ARMS打造的立体化监控体系
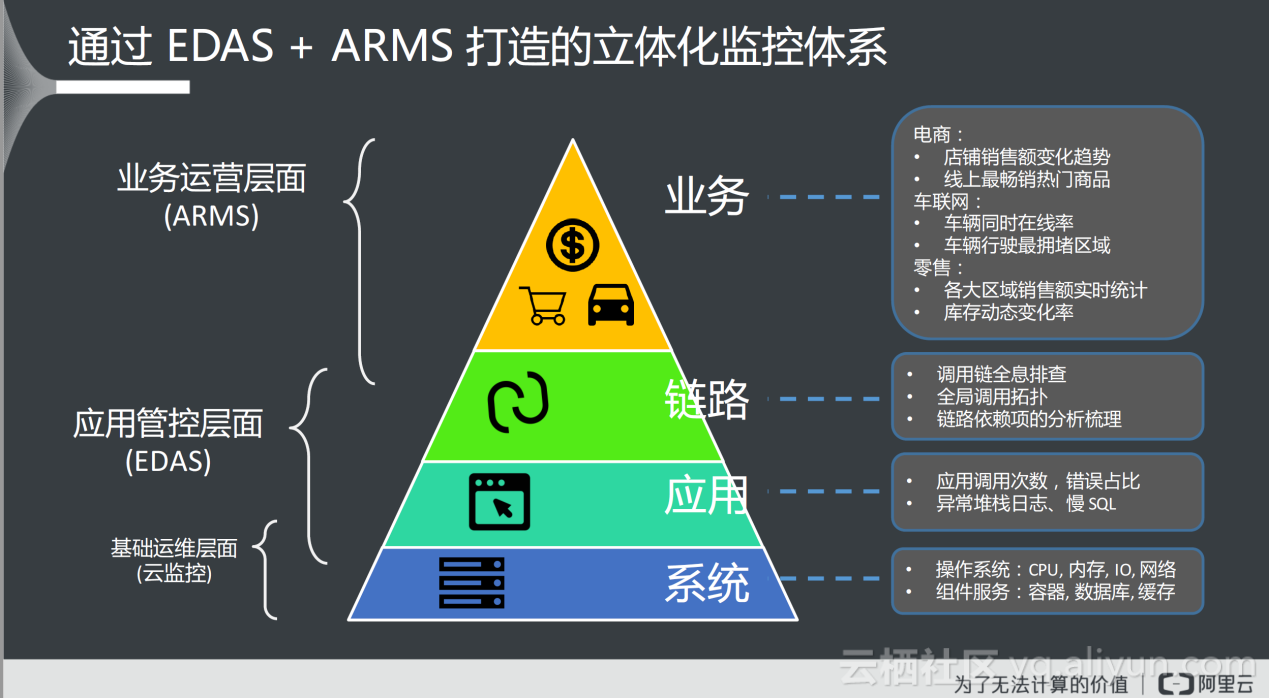
目前,通过阿里云提供的EDAS结合ARMS可以打造立体化监控体系,其中EDAS用于应用管控层面,用于控制链路和应用;而ARMS更关注业务运营层面,如电商交易、车联网、零售;实际上,监控需要全方位关注业务、链路、应用、系统,通过ARMS与EDAS相互补全,形成了立体化监控体系。