4.6 典型使用场景参考
下面是Redis适用的一些场景:
1. 取最新 N 个数据的操作
比如典型的取你网站的最新文章,通过下面方式,我们可以将最新的 5000条评论的ID放在Redis的List集合中,并将超出集合部分从数据库获取。
使用LPUSH latest.comments命令,向 list集合中插入数据 插入完成后再用 LTRIM latest.comments 0 5000 命令使其永远只保存最近5000个 ID 然后我们在客户端获取某一页评论时可以用下面的逻辑
FUNCTION get_latest_comments(start,num_items):
id_list = redis.lrange("latest.comments",start,start+num_items-1)
IF id_list.length < num_items
id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...")
END
RETURN id_list
END
如果你还有不同的筛选维度,比如某个分类的最新 N 条,那么你可以再建一个按此分类的List,只存ID的话,Redis是非常高效的。
2. 排行榜应用,取 TOP N 操作
这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的 sorted set出马了,将你要排序的值设置成 sorted set的score,将具体的数据设置成相应的 value,每次只需要执行一条ZADD命令即可。
127.0.0.1:6379> zdd topapp 1 weixin
(error) ERR unknown command 'zdd'
127.0.0.1:6379> zadd topapp 1 weixin
(integer) 1
127.0.0.1:6379> zadd topapp 1 QQ
(integer) 1
127.0.0.1:6379> zadd topapp 2 meituan
(integer) 1
127.0.0.1:6379> zincrby topapp 1 meituan
"3"
127.0.0.1:6379> zincrby topapp 1 QQ
"2"
127.0.0.1:6379> zrank topapp QQ
(integer) 1
3) "meituan"
127.0.0.1:6379> zrank topapp weixin
(integer) 0
127.0.0.1:6379> zrange topapp 0 -1
1) "weixin"
2) "QQ"
3.需要精准设定过期时间的应用
比如你可以把上面说到的 sorted set 的 score 值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序,定时清除过期数据了,不仅是清除 Redis中的过期数据,你完全可以把 Redis 里这个过期时间当成是对数据库中数据的索引,用 Redis 来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录。
4.计数器应用
Redis的命令都是原子性的,你可以轻松地利用 INCR,DECR 命令来构建计数器系统。
5.Uniq 操作,获取某段时间所有数据排重值
这个使用Redis的 set数据结构最合适了,只需要不断地将数据往 set中扔就行了,set意为集合,所以会自动排重。
6.实时系统,反垃圾系统
通过上面说到的 set功能,你可以知道一个终端用户是否进行了某个操作,可以找到其操作的集合并进行分析统计对比等。
7.Pub/Sub 构建实时消息系统
Redis 的 Pub/Sub 系统可以构建实时的消息系统,比如很多用 Pub/Sub 构建的实时聊天系统的例子。
8.构建队列系统
使用list可以构建队列系统,使用 sorted set甚至可以构建有优先级的队列系统。
9.缓存
性能优于Memcached,数据结构更多样化。作为RDBMS的前端挡箭牌,redis可以对一些使用频率极高的sql操作进行cache,比如,我们可以根据sql的hash进行SQL结果的缓存:
def get_results(sql):
hash = md5.new(sql).digest()
result = redis.get(hash)
if result is None:
result = db.execute(sql)
redis.set(hash, result)
# or use redis.setex to set a TTL for the key
return result
10.使用setbit进行统计计数
下边的例子是记录UV
#!/usr/bin/python
import redis
from bitarray import bitarray
from datetime import date
r=redis.Redis(host='localhost', port=6379, db=0)
today=date.today().strftime('%Y-%m-%d')
def bitcount(n):
len(bin(n)-2)
def setup():
r.delete('user:'+today)
r.setbit('user:'+today,100,0)
def setuniquser(uid):
r.setbit('user:'+today,uid,1)
def countuniquser():
a = bitarray()
a.frombytes(r.get('user:'+today),)
print a
print a.count()
if __name__=='__main__':
setup()
setuniquser(uid=0)
countuniquser()
11.维护好友关系
使用set进行是否为好友关系,共同好友等操作
12.使用 Redis 实现自动补全功能
使用有序集合保存输入结果:
ZADD word:a 0 apple 0 application 0 acfun 0 adobe
ZADD word:ap 0 apple 0 application
ZADD word:app 0 apple 0 application
ZADD word:appl 0 apple 0 application
ZADD word:apple 0 apple
ZADD word:appli 0 application
再使用一个有序集合保存热度:
ZADD word_scores 100 apple 80 adobe 70 application 60 acfun
取结果时采用交集操作:
ZINTERSTORE word_result 2 word_scores word:a WEIGHTS 1 1
ZRANGE word_result 0 -1 withscores
13. 可靠队列设计
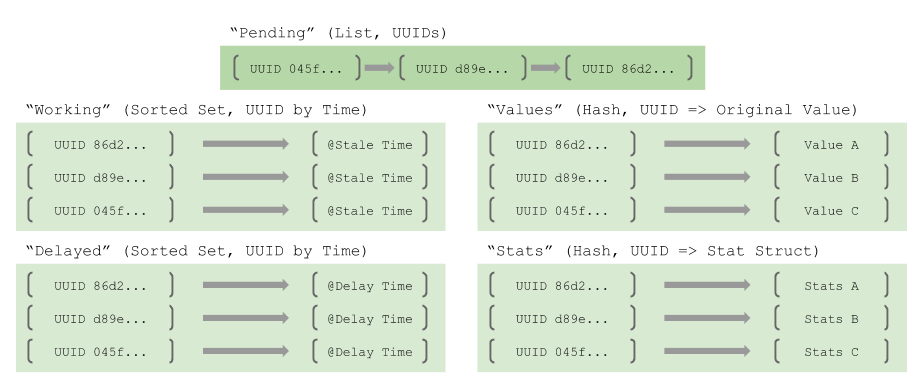 • UUIDs as Surrogate Keys Our strategy spreads information about the state of an item in the queue across a number of Redis data structures, requiring the use of a per-item surrogate key to tie them together. The UUID is a good choice here because 1) they are quick to generate, and 2) can be generated by the clients in a decentralized manner. • Pending List The Pending List holds the generated UUIDs for the items that have been enqueued(), and are ready to be processed. It is a RedisList, presenting the generated UUIDs in FIFO order. • Values Hash The Values Hash holds the actual items that have been enqueued. It is a Redis Hash, mapping the generated UUID to the binary form of the the item. This is the only representation of the original item that will appear in any of the data structures. • Stats Hash The Stats Hash records some timestamps and counts for each of the items. Specifically: • enqueue time • last dequeue time • dequeue count • last requeue time • last requeue count. It is a Redis Hash, mapping the generated UUID to a custom data structure that holds this data in a packed, binary form. Why keep stats on a per-item basis? We find it really useful for debugging (e.g. do we have a bad apple item that is being continuously requeued?), and for understanding how far behind we are if queues start to back up. Furthermore, the cost is only ~40 bytes per item, much smaller than our typical queued items. • Working Set The Working Set holds the set of UUIDs that have been dequeued(), and are currently being processed. It is a Redis Sorted Set, and scores each of the UUIDs by a pre-calculated, millisecond timestamp. Any object that has exceeded its assigned timeout is considered abandoned, and is available to be reclaimed. • Delay Set The Delay Set holds the set of UUIDs that have been requeued() with a per-item deferment. It is a Redis Sorted Set, and scores each of the UUIDs by a pre-calculated, millisecond timestamp. Once the deferment timestamp has expired, the item will be returned to the Pending List. Why support per-item deferment? We have a number of use cases where we might want to backoff specific pieces of work — maybe an underlying resource is too busy — without backing off the entire queue. Per-item deferment lets us say, “requeue this item, but don’t make it available for dequeue for another n seconds.”
• UUIDs as Surrogate Keys Our strategy spreads information about the state of an item in the queue across a number of Redis data structures, requiring the use of a per-item surrogate key to tie them together. The UUID is a good choice here because 1) they are quick to generate, and 2) can be generated by the clients in a decentralized manner. • Pending List The Pending List holds the generated UUIDs for the items that have been enqueued(), and are ready to be processed. It is a RedisList, presenting the generated UUIDs in FIFO order. • Values Hash The Values Hash holds the actual items that have been enqueued. It is a Redis Hash, mapping the generated UUID to the binary form of the the item. This is the only representation of the original item that will appear in any of the data structures. • Stats Hash The Stats Hash records some timestamps and counts for each of the items. Specifically: • enqueue time • last dequeue time • dequeue count • last requeue time • last requeue count. It is a Redis Hash, mapping the generated UUID to a custom data structure that holds this data in a packed, binary form. Why keep stats on a per-item basis? We find it really useful for debugging (e.g. do we have a bad apple item that is being continuously requeued?), and for understanding how far behind we are if queues start to back up. Furthermore, the cost is only ~40 bytes per item, much smaller than our typical queued items. • Working Set The Working Set holds the set of UUIDs that have been dequeued(), and are currently being processed. It is a Redis Sorted Set, and scores each of the UUIDs by a pre-calculated, millisecond timestamp. Any object that has exceeded its assigned timeout is considered abandoned, and is available to be reclaimed. • Delay Set The Delay Set holds the set of UUIDs that have been requeued() with a per-item deferment. It is a Redis Sorted Set, and scores each of the UUIDs by a pre-calculated, millisecond timestamp. Once the deferment timestamp has expired, the item will be returned to the Pending List. Why support per-item deferment? We have a number of use cases where we might want to backoff specific pieces of work — maybe an underlying resource is too busy — without backing off the entire queue. Per-item deferment lets us say, “requeue this item, but don’t make it available for dequeue for another n seconds.”
Redis开发运维实践指南
本文为《Redis开发运维实践指南》内容,该书作者为黄鹏程,已授权云栖社区转载。