更多深度文章,请关注:https://yq.aliyun.com/cloud

几个月前,我写了一篇关于如何使用CNN(卷积神经网络)尤其是VGG16来分类图像的教程,该模型能够以很高的精确度识别我们日常生活中的1000种不同种类的物品。
那时,模型还是和Keras包分开的,我们得从free-standing GitHub repo上下载并手动安装;现在模型已经整合进Keras包,原先的教程也已经不再适用,所以我决定写一篇新的教程。
在教程中,你将学习到如何编写一个Python脚本来分类你自己的图像。
博客结构
1. 简要说明一下这几个网络架构;
2. 使用Python编写代码:载入训练好的模型并对输入图像分类;
3. 审查一些样本图片的分类结果。
Keras中最新的深度学习图像分类器
Keras提供了五种开箱即用型的CNN:
1. VGG16
2. VGG19
3. ResNet50
4. Inception V3
5. Xception
什么是ImageNet
ImageNet曾是一个计算机视觉研究项目:(人工)打标签并分类成22000个不同物品种类。然而,当我们在讨论深度学习和CNN的时候,“ImageNet”意味着ImageNet Large Scale Visual Recognition Challenge,简写为ILSVRC。
ILSVRC的目的是训练一个能够正确识别图像并分类(1000种)的模型:模型使用约120万张图像用作训练,5万张图像用作验证,10万张图像用作测试。
这1000种分类涵盖了我们的日常生活接触到的东西,具体列表请点击。
在图像分类上,ImageNet竞赛已经是计算机视觉分类算法事实上的评价标准——而自2012年以来,排行榜就被CNN和其它深度学习技术所统治。
过去几年中ImageNet竞赛里表现优异的模型在Keras中均有收录。通过迁移学习,这些模型在ImageNet外的数据集中也有着不错的表现。
VGG16和VGG19
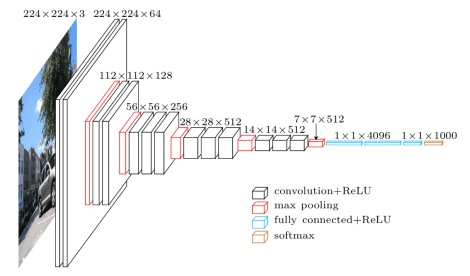
图1: VGG网络架构(source)
VGG网络架构于2014年出现在Simonyan和Zisserman中的论文中,《Very Deep Convolutional Networks for Large Scale Image Recognition》。
该架构仅仅使用堆放在彼此顶部、深度不断增加的3×3卷积层,并通过max pooling来减小volume规格;然后是两个4096节点的全连接层,最后是一个softmax分类器。“16”和“19”代表网络中权重层的数量(表2中的D和E列):
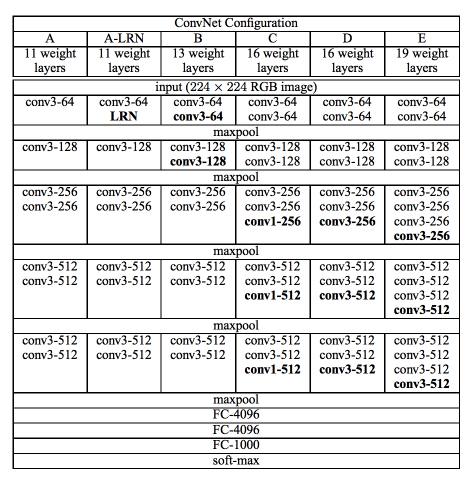
在2014年的时候,16还有19层网络还是相当深的,Simonyan和Zisserman发现训练VGG16和VGG19很有难度,于是选择先训练小一些的版本(列A和列C)。这些小的网络收敛后被用来作为初始条件训练更大更深的网络——这个过程被称为预训练(pre-training)。
预训练很有意义,但是消耗大量时间、枯燥无味,在整个网络都被训练完成前无法进行下一步工作。
如今大部分情况下,我们已经不再使用预训练,转而采用Xaiver/Glorot初始化或者MSRA初始化(有时也被称作He et al.初始化,详见《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》)。如果你感兴趣,可以从这篇文章中理解到weight initialization的重要性以及深度神经网络的收敛——《All you need is a good init, Mishkin and Matas (2015)》。
VGGNet有两个不足:
1. 训练很慢;
2. weights很大。
由于深度以及全连接节点数量的原因,VGG16的weights超过533MB,VGG19超过574MB,这使得部署VGG很令人讨厌。虽然在许多深度学习图像分类问题中我们仍使用VGG架构,但是小规模的网络架构更受欢迎(比如SqueezeNet, GoogleNet 等等)。
ResNet
与AlexNet、OverFeat还有VGG这些传统顺序型网络架构不同,ResNet的网络结构依赖于微架构模组(micro-architecture modules,也被称为network-in-network architectures) 。
微架构模组指构成网络架构的“积木”,一系列的微架构积木(连同你的标准CONV,POOL等)共同构成了大的架构(即最终的网络)。
ResNet于2015年出现在He et al的论文《Deep Residual Learning for Image Recognition》中,它的出现很有开创性意义,证明极深的网络也可以通过标准SGD(以及一个合理的初始化函数)来训练:
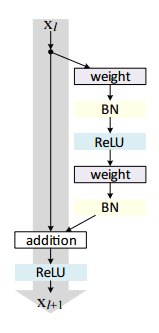
图3: He et al.于2015年提出的残差模组
在2016年的著作《Identity Mappings in Deep Residual Networks》中,他们证实了可以通过更新残差模组(residual module)来使用标志映射(identify mappings),达到提高精度的目的。
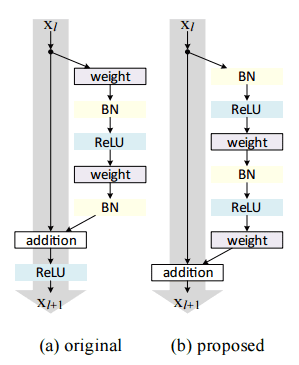
图4: (左)原始残差模组 (右)使用预激活(pre-activation)更新的残差模组
尽管ResNet比VGG16还有VGG19要深,weights却要小(102MB),因为使用了全局平均池化(global average pooling),而不是全连接层。
Inception V3
“Inception”微架构于2014年出现在Szegedy的论文中,《Going Deeper with Convolutions》。
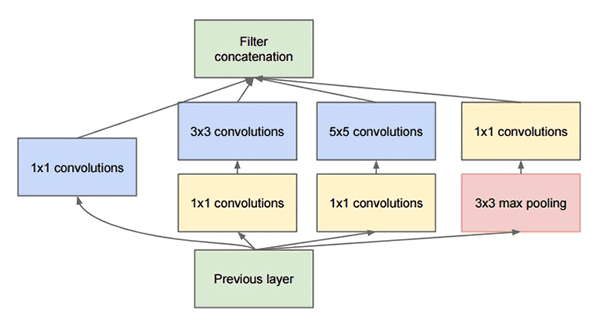
图5: GoogleNet中使用的Inception模组原型
Inception模组的目的是扮演一个“多级特征提取器”,在网络相同的模组内计算1×1、3×3还有5×5的卷积——这些过滤器的输出在输入至网络下一层之前先被堆栈到channel dimension。
该架构的原型被称为GoogleNet,后继者被简单的命名为Inception vN,N代表Google推出的数字。
Keras中的Inception V3架构来自于Szegedy et al.的后续论文,《Rethinking the Inception Architecture for Computer Vision(2015)》,该论文打算通过更新inception模组来提高ImageNet分类的准确度。
Inception V3比VGG还有ResNet都要小,约96MB。
Xception
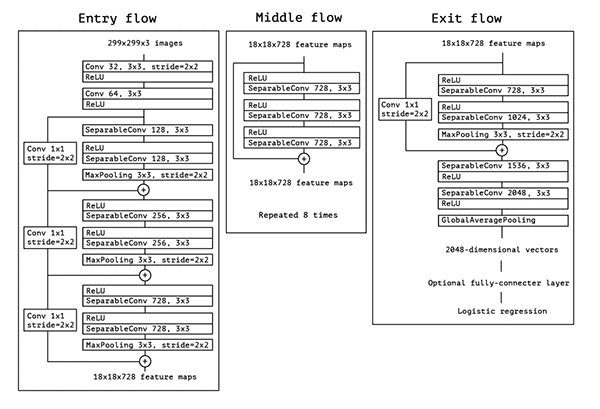
图6: Xception架构
Xception是被François Chollet提出的, 后者是Keras库的作者和主要维护者。
Xception是Inception架构的扩展,用depthwise独立卷积代替Inception标准卷积。
关于Xception的出版物《Deep Learning with Depthwise Separable Convolutions》可以在这里找到。
Xception最小仅有91MB。
SqueezeNet
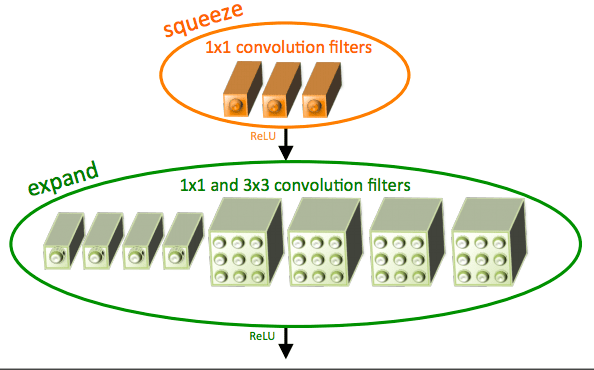
Figure 7: “fire”模组,由一个“squeeze”和一个“expand”模组组成。(Iandola et al., 2016)
仅仅4.9MB的SqueezeNet架构能达到AlexNet级别的精确度(~57% rank-1 and ~80% rank-5),这都归功于“fire”模组的使用。然而SqueezeNet的训练很麻烦,我会在即将出版的书——《Deep Learning for Computer Vision with Python》——中介绍如何训练SqueezeNet来处理ImageNet数据集。
使用Python和Keras通过VGGNet,ResNet,Inception和Xception对图像分类
新建一个文件,命名为classify_image.py,编辑插入下列代码
1 # import the necessary packages
2 from keras.applications import ResNet50
3 from keras.applications import InceptionV3
4 from keras.applications import Xception # TensorFlow ONLY
5 from keras.applications import VGG16
6 from keras.applications import VGG19
7 from keras.applications import imagenet_utils
8 from keras.applications.inception_v3 import preprocess_input
9 from keras.preprocessing.image import img_to_array
10 from keras.preprocessing.image import load_img
11 import numpy as np
12 import argparse
13 import cv2
第2-6行分别导入ResNet,Inception V3, Xception, VGG16, 还有VGG19——注意Xception只兼容TensorFlow后端。
第7行导入的image_utils包包含了一系列函数,使得对图片进行前处理以及对分类结果解码更加容易。
余下的语句导入其它有用的函数,其中NumPy用于数学运算,cv2用于与OpenCV结合。
15 # construct the argument parse and parse the arguments
16 ap = argparse.ArgumentParser()
17 ap.add_argument("-i", "--image", required=True,
18 help="path to the input image")
19 ap.add_argument("-model", "--model", type=str, default="vgg16",
20 help="name of pre-trained network to use")
21 args = vars(ap.parse_args())--model为选用的CNN的类别,默认为VGG16。
23 # define a dictionary that maps model names to their classes
24 # inside Keras
25 MODELS = {
26 "vgg16": VGG16,
27 "vgg19": VGG19,
28 "inception": InceptionV3,
29 "xception": Xception, # TensorFlow ONLY
30 "resnet": ResNet50
31 }
32
33 # esnure a valid model name was supplied via command line argument
34 if args["model"] not in MODELS.keys():
35 raise AssertionError("The --model command line argument should "
36 "be a key in the `MODELS` dictionary")如果没有在该词典中找到“--model”,就会报错。
输入一个图像到一个CNN中会返回一系列键值,包含标签及对应的概率。
ImageNet采用的图像尺寸一般为224×224, 227×227, 256×256, and 299×299,但是并不是绝对。
VGG16,VGG19以及ResNet接受224×224的输入图像, 而Inception V3和Xception要求为299×299,如下代码所示:
38 # initialize the input image shape (224x224 pixels) along with
39 # the pre-processing function (this might need to be changed
40 # based on which model we use to classify our image)
41 inputShape = (224, 224)
42 preprocess = imagenet_utils.preprocess_input
43
44 # if we are using the InceptionV3 or Xception networks, then we
45 # need to set the input shape to (299x299) [rather than (224x224)]
46 # and use a different image processing function
47 if args["model"] in ("inception", "xception"):
48 inputShape = (299, 299)
49 preprocess = preprocess_input如果使用Inception或者Xception,inputShape需要改为299×299 像素,预处理函数改为separate pre-processing函数。
下一步就是从磁盘载入网络架构的weights,并实例化模型:
51 # load our the network weights from disk (NOTE: if this is the
52 # first time you are running this script for a given network, the
53 # weights will need to be downloaded first -- depending on which
54 # network you are using, the weights can be 90-575MB, so be
55 # patient; the weights will be cached and subsequent runs of this
56 # script will be *much* faster)
57 print("[INFO] loading {}...".format(args["model"]))
58 Network = MODELS[args["model"]]
59 model = Network(weights="imagenet") 注意:VGG16和VGG19的weights大于500MB,ResNet的约等于100MB,Inception和Xception的介于90-100MB之间。如果这是你第一次运行某个网络,这些weights会自动下载到你的磁盘。下载时间由你的网络速度决定,而且下载完成后,下一次运行代码不再需要重新下载。
61 # load the input image using the Keras helper utility while ensuring
62 # the image is resized to `inputShape`, the required input dimensions
63 # for the ImageNet pre-trained network
64 print("[INFO] loading and pre-processing image...")
65 image = load_img(args["image"], target_size=inputShape)
66 image = img_to_array(image)
67
68 # our input image is now represented as a NumPy array of shape
69 # (inputShape[0], inputShape[1], 3) however we need to expand the
70 # dimension by making the shape (1, inputShape[0], inputShape[1], 3)
71 # so we can pass it through thenetwork
72 image = np.expand_dims(image, axis=0)
73
74 # pre-process the image using the appropriate function based on the
75 # model that has been loaded (i.e., mean subtraction, scaling, etc.)
76 image = preprocess(image)第65行从磁盘载入输入图像,并使用提供的inputShape初始化图像的尺寸。
第66行将图像从PIL/Pillow实例转换成NumPy矩阵,矩阵的shape为(inputShape[0], inputShape[1], 3)。
因为我们往往使用CNN来批量训练/分类图像,所以需要使用np.expand_dims在矩阵中添加一个额外的维度,如第72行所示;添加后矩阵shape为(1, inputShape[0], inputShape[1], 3)。如果你忘记添加这个维度,当你的模型使用.predict时会报错。
最后,第76行使用合适的预处理函数来执行mean subtraction/scaling。
下面将我们的图像传递给网络并获取分类结果:
78 # classify the image
79 print("[INFO] classifying image with '{}'...".format(args["model"]))
80 preds = model.predict(image)
81 P = imagenet_utils.decode_predictions(preds)
82
83 # loop over the predictions and display the rank-5 predictions +
84 # probabilities to our terminal
85 for (i, (imagenetID, label, prob)) in enumerate(P[0]):
86 print("{}. {}: {:.2f}%".format(i + 1, label, prob * 100))第81行的.decode_predictions函数将预测值解码为易读的键值对:标签、以及该标签的概率。
第85行和86行返回最可能的5个预测值并输出到终端。
案例的最后一件事,是通过OpenCV从磁盘将输入图像读取出来,在图像上画出最可能的预测值并显示在我们的屏幕上。
88 # load the image via OpenCV, draw the top prediction on the image,
89 # and display the image to our screen
90 orig = cv2.imread(args["image"])
91 (imagenetID, label, prob) = P[0][0]
92 cv2.putText(orig, "Label: {}, {:.2f}%".format(label, prob * 100),
93 (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
94 cv2.imshow("Classification", orig)
95 cv2.waitKey(0)VGGNet, ResNet, Inception, 和Xception的分类结果
所有的例子都是使用2.0以上版本的Keras以及TensorFlow后台做的。确保你的TensorFlow版本大于等于1.0,否则会报错。所有例子也都使用Theano后端做过测试,工作良好。
案例需要的图片以及代码请前往原文获取。
使用VGG16分类:
1 $ python classify_image.py --image images/soccer_ball.jpg --model vgg16
图8: 使用VGG16来分类足球(source)
输出为:soccer_ball,精确度为93.43%。
如果要使用VGG19,只需要替换下--network参数。
1 $ python classify_image.py --image images/bmw.png --model vgg19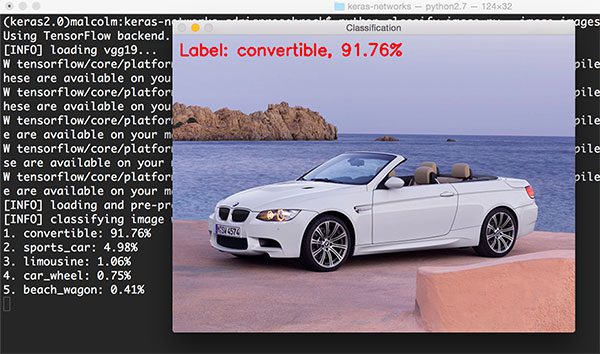
图9: 使用VGG19来分类汽车(source)
输出为:convertible(敞篷车),精确度为91.76%。然而,我们看一下其它的4个结果:sports car(跑车), 4.98%(也对);limousine(豪华轿车),1.06%(不正确,但也合理);car wheel(车轮),0.75%(技术上正确,因为图中确实出现了轮子)。
从下面的例子,我们可以看到类似的结果:
1 $ python classify_image.py --image images/clint_eastwood.jpg --model resnet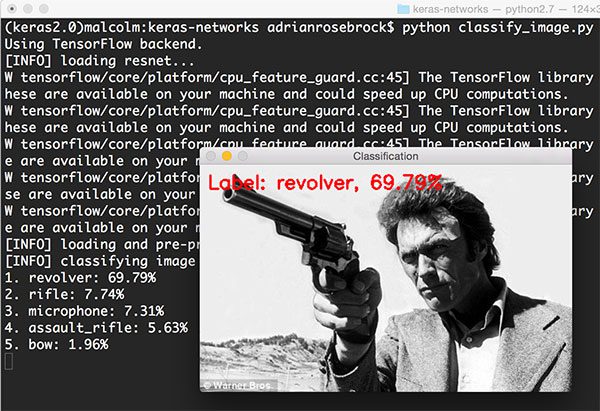
图10: 使用ResNet分类(source).
ResNet成功将图像分类为revolver(左轮手枪),精确度69.79%。有趣的是rifle(步枪)为7.74%,assault rifle(突击步枪)为5.63%。考虑到revolver的观察角度还有相对于手枪来说巨大的枪管,CNN得出这么高的概率也是合理的。
1 $ python classify_image.py --image images/jemma.png --model resnet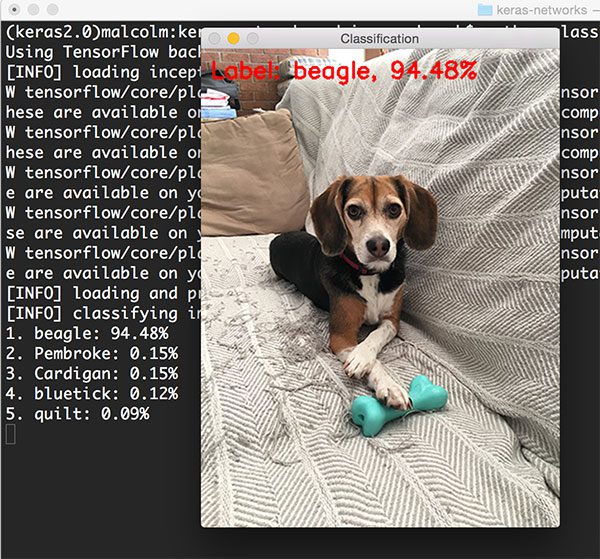
图11: 使用ResNet对狗进行分类
狗的种类被正确识别为beagle(小猎兔狗),精确度94.48%。
然后我试着分类《加勒比海盗》中的图片:
1 $ python classify_image.py --image images/boat.png --model inception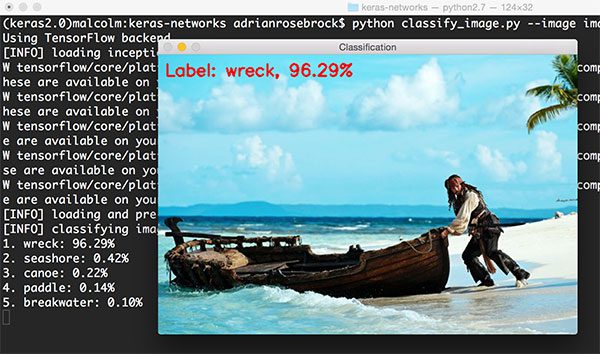
图12: 使用ResNet对沉船进行分类(source)
尽管ImageNet中有“boat”(船)这个类别,Inception网络仍然正确地将该场景识别为“(ship) wreck”(沉船),精确度96.29%。其它的标签,比如“seashore”(海滩), “canoe”(独木舟), “paddle”(桨),还有“breakwater”(防波堤),也都相关,在特定的案例中也绝对正确。
下一个例子是我办公室的长沙发,使用Inception进行分类。
1 $ python classify_image.py --image images/office.png --model inception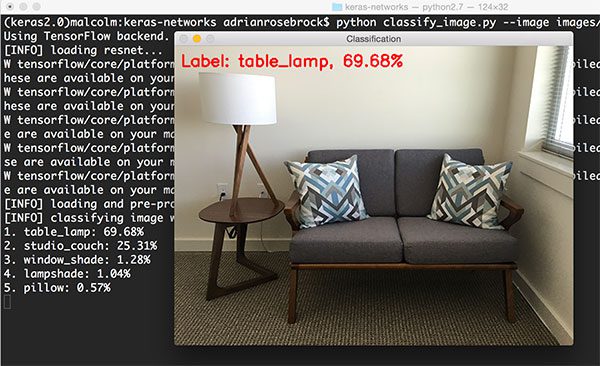
图13: 使用Inception V3分类
Inception准确地识别出图中有“table lamp”(台灯),精确度69.68%。其它的标签也完全正确:“studio couch”(两用沙发),“window shade”(窗帘), “lampshade”(灯罩), 还有“pillow”(枕头)。
下面是Xception:
1 $ python classify_image.py --image images/scotch.png --model xception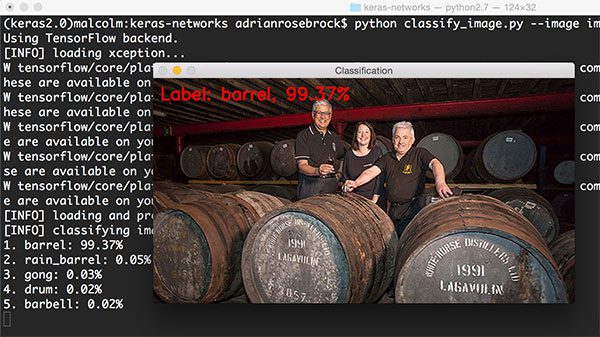
图14: 使用Xception分类(source)
Xception将图片正确分类为“barrels”(桶)。
最后一个例子使用VGG16:
1 $ python classify_image.py --image images/tv.png --model vgg16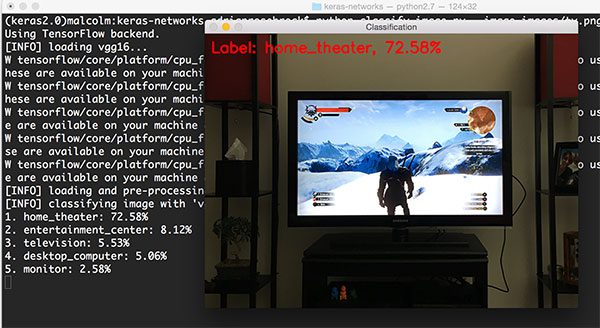
图15: 使用VGG16分类。
图片来自于《巫师3:狂猎》。VGG16的第一个预测值为“home theatre”(家庭影院),前5个预测中还有一个“television/monitor”(电视/显示器),预测很合理。
正如你从上述例子中所看到的,使用IamgeNet数据集训练的模型能够准确识别大量日常生活中的物品。希望你能在自己的项目中用到这些代码。
之后呢?
如果你想从头开始训练自己的深度学习网络,该怎么做?
我的新书能够帮助你做到这些,从一个为深度学习的菜鸟成长为专家。
总结
在今天的博客中,我们回顾了5种卷积神经网络(CNN):
1. VGG16
2. VGG19
3. ResNet50
4. Inception V3
5. Xception
然后是使用这些架构对你自己的图像进行分类。
如果你对深度学习还有卷积神经网络有更多的兴趣,一定要看一看我的新书《Deep Learning for Computer Vision with Python》,现在就可以进行订购。
博客代码下载。
关于作者:
Adrian Rosebrock,企业家兼博士,推出了两个成功的图像搜索引擎:ID My Pill和Chic Engine。
本文由北邮 @爱可可-爱生活 老师推荐, 阿里云云栖社区 组织翻译。
文章原标题《ImageNet: VGGNet, ResNet, Inception, and Xception with Keras》,作者:Adrian Rosebrock,译者:杨辉,审阅:董昭男,附件为原文的pdf。
文章为简译,更为详细的内容,请查看原文





{kind=link}