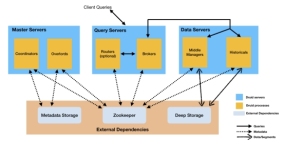
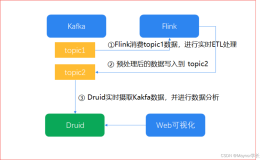
日前,SunGard亚太区保险业务首席运营官Peter Haslebacher来华,行程被排得满满的。
他先后拜访国内多位保险公司高管,寻找双方基于互联网与大数据分析模型开展保险创新业务的可行性。
“互联网正在悄悄改变保险业的整个生态圈,从产品设计、营销服务、流程再造、投资风险承受能力等等各个环节。”他接受21世纪经济报道记者采访时直言,越来越多亚太地区保险公司正在尝试各式各样的互联网保险创新,即便两者的“融合”绝非一帆风顺。
模拟“投资情景”
《21世纪》:保险产品本身已有大数据分析的基因,那么,基于互联网的大数据分析模型,还会给保险产品创新带来多大推动力?
Peter:的确,多数保险产品是由精算师借助各类数据设计的,但这些数据以往主要用于完善保险产品理赔责任与化解运营风险。在基于互联网大数据的分析下,保险公司可以加入个性化的投资风险承受程度,进而设计更多创新产品。比如保险公司可以用互联网与大数据分析模型模拟成千上万个“投资情景”,分析最坏状况下的投资回报与理赔状况,对保险公司经营风险带来多大的冲击,不断优化自身投资组合,设计高收益的个性化保险产品。近期,欧美保险公司开始尝试用互联网平台研发销售收益更高的保险产品,以往他们则倾向设计回报相对稳健的寿险类保障型产品。
《21世纪》:你认为互联网可能在未来某个时间,重塑现有保险业的营销体系吗?
Peter:亚太地区多家保险公司对互联网营销服务的战略定位,是提升客户的品牌忠诚度。长期以来,维系客户与保险公司纽带的是保险代理人。客户有理赔就找代理人,代理人时常帮助客户解决生活难题,这种线下营销模式带来的一个后果,是广大客户对保险公司没有太多感情,代理人一跳槽就容易带走一批客户。
如今,借助互联网手段,这些保险公司开始思考如何拉近自己与客户的距离。新加坡个别保险公司在官网开设烹饪、育儿、家居保养等频道,增加自己与客户之间的互动频率。
还有个别欧美保险公司借鉴云计算的技术优势,将客户与代理人的沟通信息存储起来,避免客户流失。但我觉得这未必能留住客户的心,因为它不能令客户产生情感共鸣。
业务流程改造
《21世纪》:互联网要改变保险业生态圈,最大的难点是改造保险公司的业务流程,这种改造如何进行?
Peter:过去两三年,不少欧美保险公司投入大量精力探索这些基于互联网的保险产品便捷服务,但成功者不多。究其原因,这对保险公司内部业务流程的改造完善提出很高挑战。一方面保险公司内部需要建立一套快速、高效、可靠的信息反应处理系统,确保客户信息从接收到执行,在最短时间完成且没有任何差错;另一方面保险公司有没有相应的投资能力,保证长期稳健的投资回报。
《21世纪》:全球保险业监管趋紧,对保险公司创造高收益带来哪些挑战?
Peter:全球保险业监管趋紧,主要表现在三个层面:保险投资资产从严分级,某些在次贷危机爆发前被视为安全的投资资产,包括个别存在债务危机的国家国债、次级高收益房贷证券化产品,都被剔除在保险公司可投资资产之外;可交易的货币种类被重新设定,某些国家监管部门要求保险公司调低某些货币资产的持仓比例,因为这些货币面临大幅贬值风险;三是投资范围收窄,某些亚太国家监管部门希望保险公司降低海外投资的比重。
其中最大的挑战,还是保险投资资产从严分级。通常,高风险资产对应高收益。但随着全球进入低利率时代,保险公司要获得高收益,就需要增持高风险资产。但在资产从严分级的情况下,高收益如何获取,又是一个问题。
可以预见的是,如果保险公司投资收益状况无法持续提高,保本保利型保险产品将逐步退出市场。我也听说国内保险公司的解决办法,是购买高收益、流动性较低的非标资产。或许,这类投资资产也需要从严分级与强化风险控制,因为金融风险往往出现在大家最容易忽略的环节。
原文发布时间为:2014-07-12
本文来自云栖社区合作伙伴“大数据文摘”,了解相关信息可以关注“BigDataDigest”微信公众号