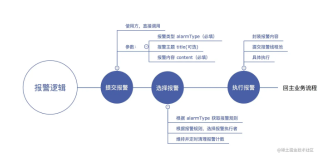
当企业上云后,监控云资源的异常操作就是一件非常重要的事情。比如:
• 针对主账号登陆行为进行通知,因为大部分情况企业都是使用子账号;
• 针对会产生费用的操作进行通知,避免异常购买行为对企业造成资损;
• 针对删除资源的事件进行报警,因为删除是个敏感操作,误删资源极可能导致服务不可用;
• 针对接口调用量突变进行报警,因为这很可能是业务出现了异常; 等等
那么如何监控这些异常操作呢?答案就是操作审计。接下来就以一些实际场景为例,介绍如何基于操作审计,监控云上异常操作或操作频率,进行报警。
技术方案
操作审计记录了云账号在阿里云上的所有操作事件,例如 OpenAPI 调用、售卖页购买资源等。用户可以使用操作审计的跟踪功能,将账号下的操作事件投递到指定的 SLS,接下来就可以利用 SLS 的报警能力,针对异常事件进行报警。

实现步骤
实现过程分为两步:
- 创建跟踪:将云账号的操作事件投递到 SLS
- 配置报警:在 SLS 中,根据不同场景配置报警规则
创建跟踪
如果您的账号中已经有投递到日志服务 SLS 的跟踪,则可以跳过这一步骤
操作审计默认会帮助您记录账号内最近 90 天的操作日志,但如果想要实现自定义监控报警,则需要创建一个跟踪,并设置投递到日志服务 SLS 中,利用 SLS 实现监控报警。
• 如果您习惯控制台操作,则可以参考 这篇文档,在操作审计控制台中,完成跟踪创建
• 如果您希望通过通过 SDK 调用 API 来操作,则可以参考操作审计的 CreateTrail API 介绍
• 如果您希望使用 IaC 方案自动化创建跟踪,则可以参考:
• 使用 阿里云资源编排 ROS 创建 操作审计跟踪
• 使用 Terraform 创建操作审计跟踪
创建了跟踪后,操作审计就会持续且实时地将您云账号下的操作事件投递到您指定的 SLS 中。
报警设置
设置报警可分为以下几个步骤:
• 确定异常操作事件
• 针对异常事件编写 SLS 查询语句
• 根据查询结果进行报警
接下来本文将针对一些常见场景,结合真实案例描述如何设置报警。
常见场景
监控主账号登陆
真实案例
当企业对云资源进行管控的时候,为了进行权限控制,一般都是使用子账号,很少直接使用主账号。所以企业希望主账号一旦登陆,就进行报警。这样当主账号可能密码泄漏、非法登陆时,能及时发现。
步骤一:确定登陆事件
在操作审计中,登陆事件名称为 ConsoleSignin 。
登陆事件中 userIdentity 标记登陆者信息:
• userIdentity.type 如果为 root-account 则表示主账号; ram-user 表示 RAM 用户;
• userIdentity.accountId 是主账号 ID;
• userIdentity.pricipalld 是当登陆者的 ID,如果是主账号登陆就是主账号 ID,如果是子账号登陆就是子账号 ID。
登陆事件如图所示:

操作事件主要有以下几类:
• ApiCall 阿里云 OpenAPI 调用事件,其 eventName 字段就是 API 名称
• PasswordReset 密码重置事件
• ConsoleSignin 控制登陆事件
• ConsoleSignout 控制台登出事件
• AliyunServiceEvent 实例到期自动释放事件
• ConsoleOperation 其他控制操作
关于事件结构定义可参考文档:操作事件结构定义 。
步骤二:查询主账号登陆事件
了解了以上信息,就可以编写 SQL 查询主账号登陆事件了。查询条件就是 eventName 为 ConsoleSignin ,且 event.userIdentity.type 为 root-account 。
* | SELECT COUNT(*) as count FROM log WHERE "event.eventName" = 'ConsoleSignin' AND "event.userIdentity.type" = 'root-account'.如图所示,查询出来主账号在 15 分钟内有 1 次登陆。
步骤三:配置报警
点击 “另存为告警”,就可以针对上述查询结果进行报警。
假设我们希望主账号只要登陆控制台就报警,则可以配置报警规则为:每隔 5 分钟,查询 5 分钟内主账号登陆事件数量,如果有大于等于一次登陆就报警。如果想要报警更及时,则可以调整间隔时间和查询区间。
配置如下:

$0 表示第一条查询语句, $0.count 就是查询结果中的 count 字段。接下来再完善通知信息即可,这里不再赘述。
关于 SLS 报警配置的详细说明可参考文档:日志服务-告警 。
报警示例
假设前面配置了钉钉群报警,则一旦主账号登陆,就会收到类似下图的报警:

高危操作报警
真实案例
某企业网站突然打不开了,经排查发现原来是 SSL 证书被误删了,导致 CDN 资源都无法访问。
资源删除操作是个高危操作,如果资源在被删除时能有报警,就能及时发现甚至避免业务故障了。
解决方案
要针对资源删除进行报警,就需要列举出删除资源的 API,可以在对应云产品文档中找到删除相关的 API;为了简单,也可以模糊查询 Delete 或 Remove 开头的 API,这类 API 基本是删除操作。
查询条件
* | SELECT "event.serviceName" AS service, "event.eventName" AS event, COUNT(*) AS count FROM log WHERE "event.eventName" LIKE 'Delete%' OR "event.eventName" LIKE 'Remove%' GROUP BY service,event ORDER BY count DESC触发条件
$0.count > 0 即只要有资源删除,就报警。
报警通知发送内容
${Results[0].RawResultsAsKv} ,即发送文本格式的查询结果,查询结果可能有多项。
报警示例

收到报警后,就能及时在跟踪投递的 SLS LogStore 中查询到删除操作以及操作者。
高频失败调用报警
真实案例
某运维在查看日志时,发现某 AccessKey 在一段时间内频繁出现 403 的错误。经过排查发现,是因为该 AccessKey 没有权限,但一直在尝试调用云服务。
此外还有其他调用失败的情况,这些调用失败,可能是权限问题,也可能是使用方式不正确。如果能针调用失败进行报警,就能及时发现并解决问题。
解决方案
操作审计记录了所有云服务调用操作,并且针对异常调用记录了错误码。所以可以通过有无错误码来判断调用是否正常。
• event.errorCode 错误码,如果有该字段,则表示调用出错
• event.errorMessage 错误消息,如果有该字段,则表示调用出错
因为正常调用 API 也可能出错,所以为了让报警更准确,可以根据频率来报警。最终设计报警规则为:每 5 分钟执行一次,查询当前 5 分钟至的错误总数 x,和前 5 分钟至前 10 分钟错误总数 y,如果 x 相比 y 增长了 30%,则报警。
查询条件
* |
SELECT
count_old AS "前10分钟至前5分钟接口调用失败",
count_new AS "前5分钟至现在接口调用失败",
if(count_old > 0, round((count_new-count_old + 0.0) / count_old, 6), 0) AS res
FROM (
SELECT
SUM(
CASE
WHEN "event.errorMessage" IS NOT NULL
AND __time__ >= to_unixtime(date_add('minute', -10, current_timestamp))
AND __time__ < to_unixtime(date_add('minute', -5, current_timestamp)) THEN 1
ELSE 0
END
) AS count_old,
SUM(
CASE
WHEN "event.errorMessage" IS NOT NULL
AND __time__ >= to_unixtime(date_add('minute', -5, current_timestamp))
AND __time__ < to_unixtime(date_add('minute', 0, current_timestamp)) THEN 1
ELSE 0
END
) AS count_new
FROM log
)注意:上述查询条件中,根据 event.errorMessage 是否为 NULL 来决定是否调用异常。因为当前操作审计创建跟踪时,默认创建的 SLS Project 及 LogStore 中,将 event.errorMessage 加入了索引;而 event.errorCode 没有加入索引。所以如果要使用 event.errorCode 作为查询条件,需要将其加入索引。
触发条件
$0.res > 0.3 即错误率增长 30% 就报警。
总结
本文基于一些真实案例,介绍了如何基于操作审计对云上资源异常操作进行监控报警,提高云上资源管控的安全性。当然,实际可能还会有更复杂的场景。希望通过本文的介绍,大家能够举一反三,实现更贴合自己业务的报警。