热门
一文解读:阿里云AI基础设施的演进与挑战
Apache RocketMQ ACL 2.0 全新升级
5月更文挑战赛火热启动,坚持热爱坚持创作!
案例分析|线程池相关故障梳理&总结
给技术新人的ODPS优化建议
如何提高密码的复杂度?
安全通信的未来趋势是什么?
数据库sqlserver-----触发器的插入,更新和删除
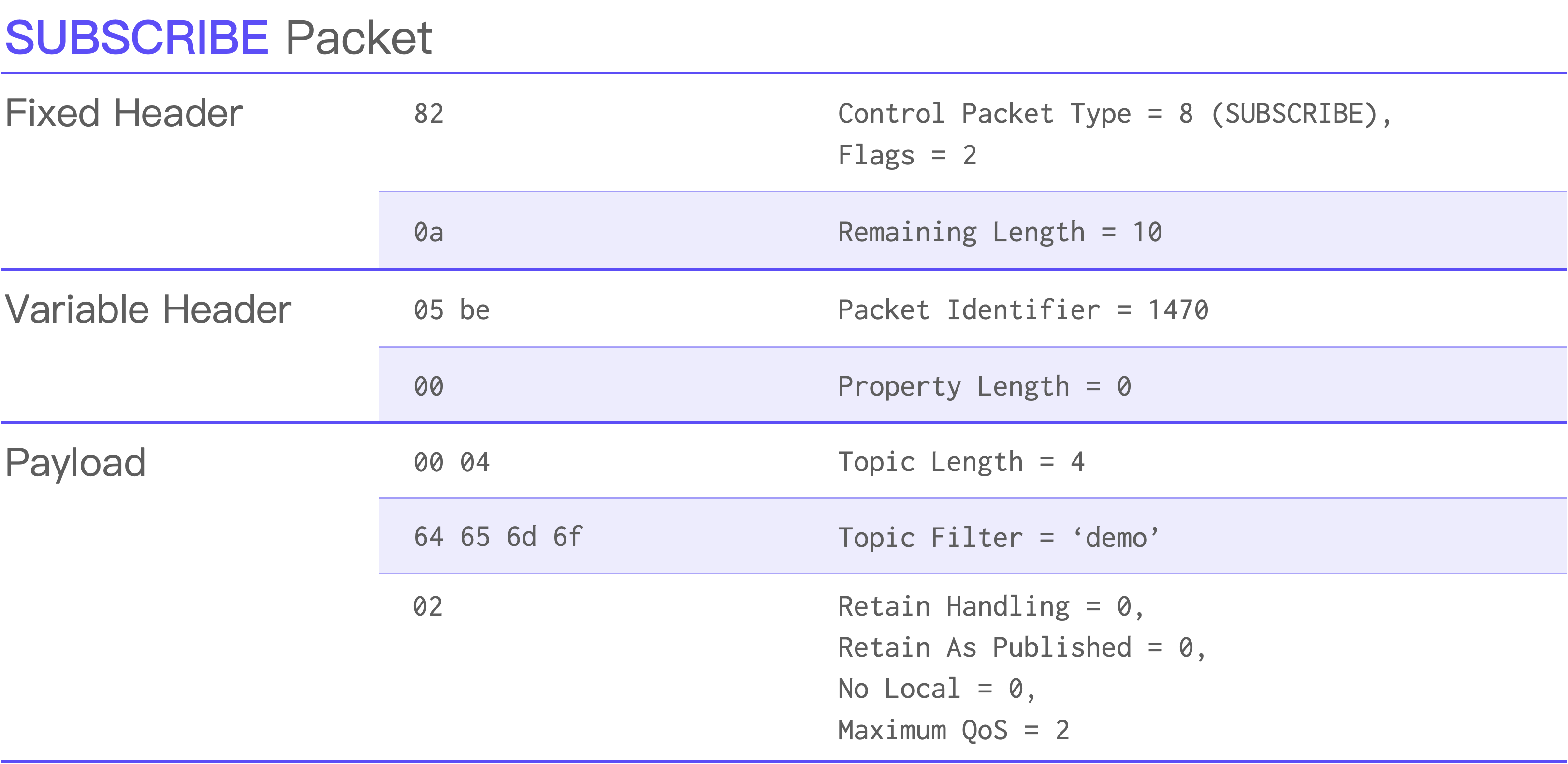
MQTT 5.0 报文解析 03:SUBSCRIBE 与 UNSUBSCRIBE
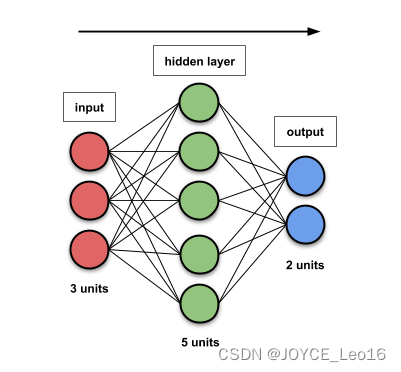
一文搞懂 FFN / RNN / CNN 的参数量计算公式 !!
手写操作系统(4)——计算机是如何启动的?BIOS、GRUB、文件系统......
Allure2添加用例标题、用例步骤
深度学习500问——Chapter07:生成对抗网络(GAN)(1)
内存
inux权限管理
局部变量和成员变量
默认值
DHCP的option43
IEEE802.1, IEEE802.3和IEEE802.11的分类(仅为分类)
一文介绍CNN/RNN/GAN/Transformer等架构 !!
第五十练 请以递归方式实现计算给定数字的幂的函数
网络设备的部署(串行与并行)
Mamba入局遥感图像分割 | Samba: 首个基于SSM的遥感高分图像语义分割框架
认证方式总结(802.1x,PPPOE,IPOE,Portal,MAC认证)
手写操作系统(3)——开发环境建立与内核架构设计
【JavaEE】Servlet的API详解(下)
深度学习500问——Chapter06: 循环神经网络(RNN)(4)
【JavaEE】Servlet的API详解(上)
DVD复制与DVD翻录,有何差异?
无线网络管理设备
软考网工计算题总结(一):总共35类题型,进来复习啦!
深度学习500问——Chapter06: 循环神经网络(RNN)(3)
【JavaEE】HTTP状态码-HTTP数据报的构造
BERT时代,向量语义检索我们关注什么?
深度学习500问——Chapter06: 循环神经网络(RNN)(2)
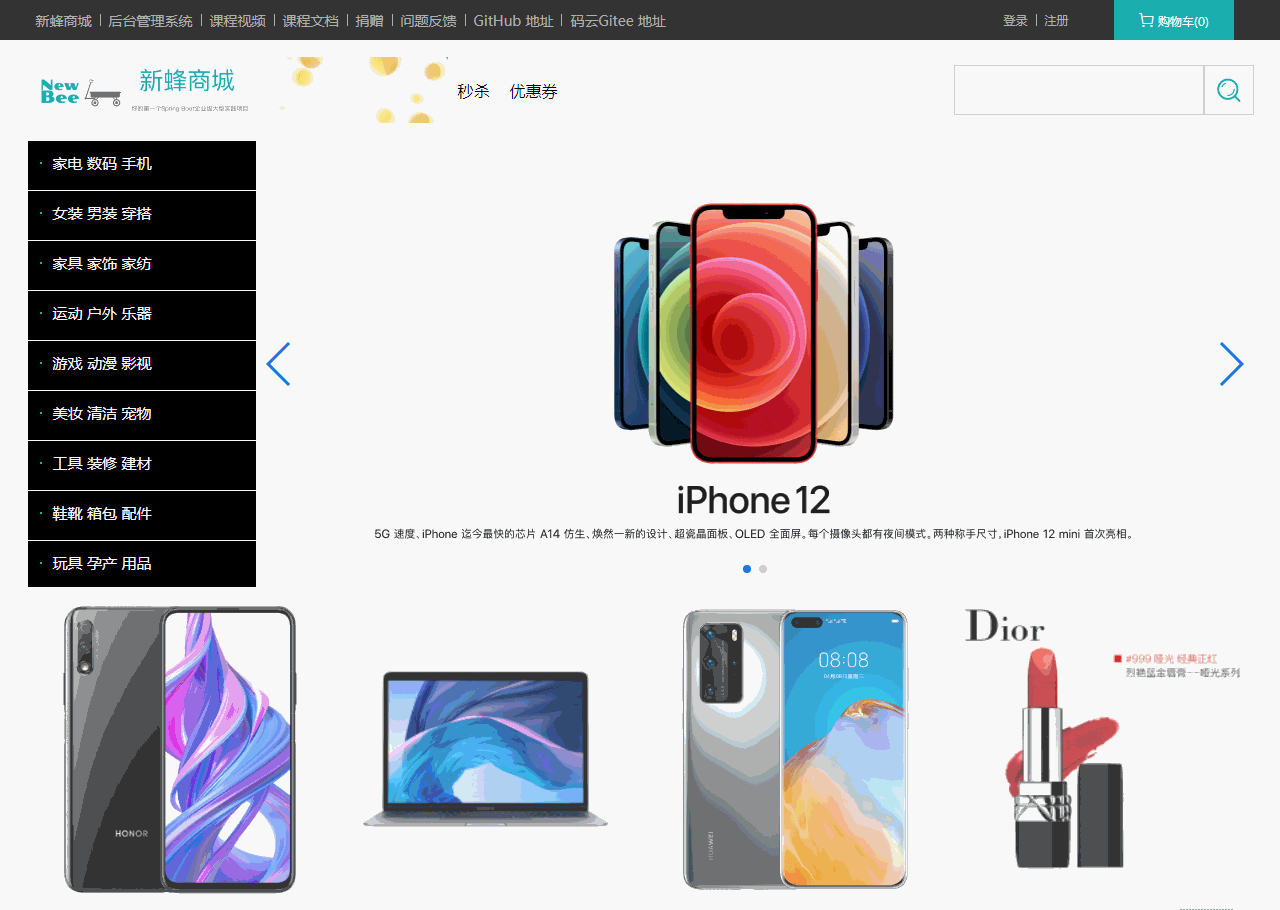
【Java Spring开源项目】新蜂(NeeBee)商城项目运行、分析、总结
实验 3:图形数据结构的实现与应用
【布客技术评论】大模型开源与闭源:原因、现状与前景
Vue3中定义变量是选择ref还是reactive?
Three.js加载glb / gltf模型,Vue加载glb / gltf模型(如何在vue中使用three.js,vue使用threejs加载glb模型)
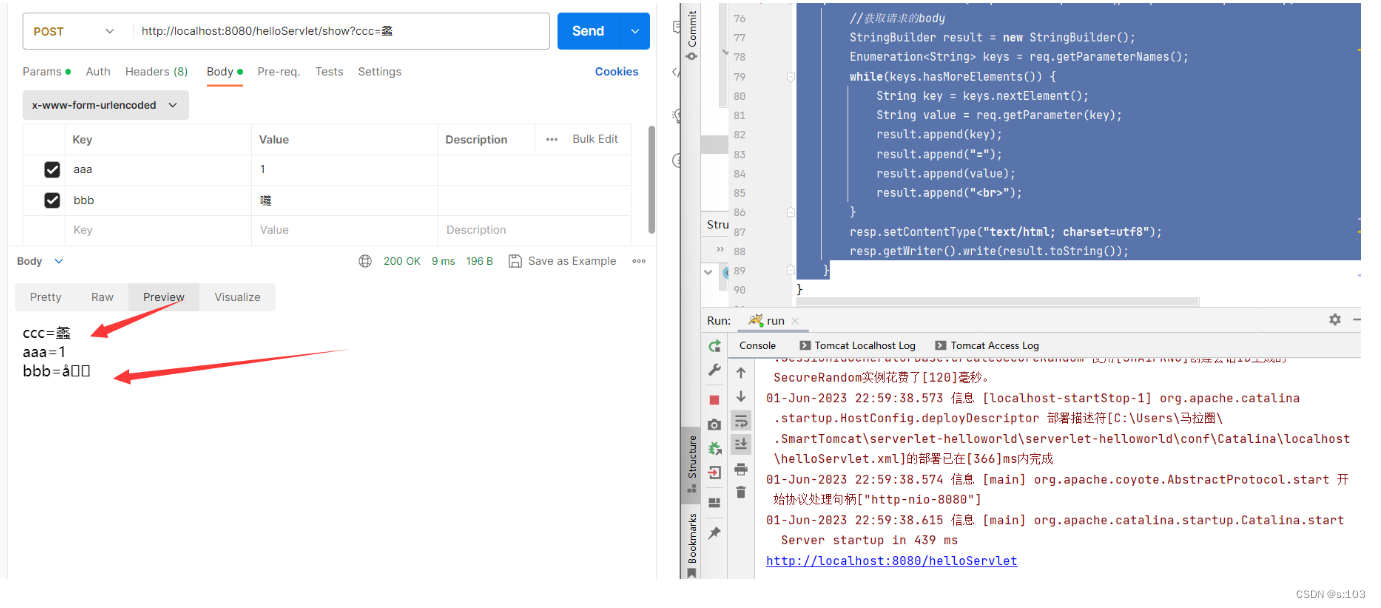
【JavaEE】Tomcat-Servelet第一个helloworld程序(下)
【JavaEE】Tomcat-Servelet第一个helloworld程序(中)
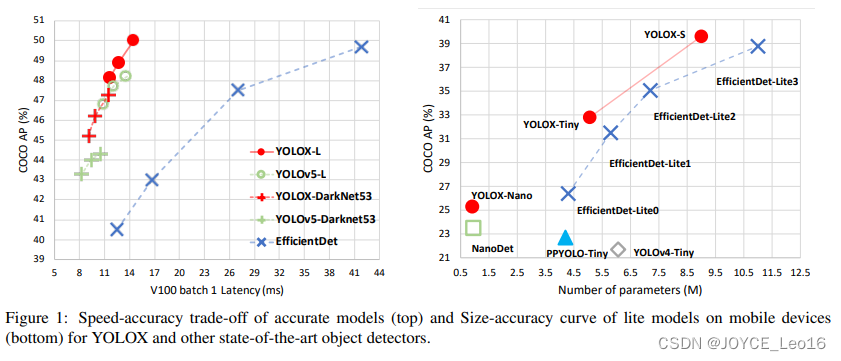
YOLO系列算法全家桶——YOLOv1-YOLOv9详细介绍 !!(二)
【实习总结】Java学习最佳实践!
常用shell整理
【JavaEE】Tomcat-Servelet第一个helloworld程序(上)
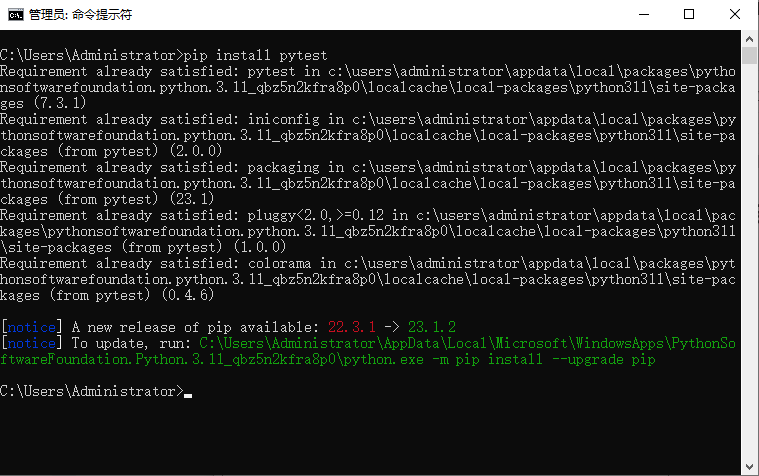
Pytest测试框架
Spring特性之二——IOC控制反转
特殊的ip地址
数据结构作业4-图