本文作者:广富 — 阿里巴巴 Elasticsearch 高级开发工程师
简述:
阿里云 Elasticsearch 云服务平台,是阿里云依托于云上丰富的云计算资源,向用户推出的托管的 Elastic Stack 服务,目前已在全球部署了17个地域,存储了 PB 级以上的数据量。本文将揭秘阿里云在面对 PB 级数据量挑战下所做的内核优化实践。
一、阿里巴巴 Elasticsearch 云服务平台
阿里云 Elasticsearch 主要包括开源系统和自研系统两部分。开源系统依托于阿里云丰富的云计算资源,如 ECS, VPC, SLB 等,在此基础之上不仅向用户提供了 Elasticsearch, Kibana, Logstash, Beats 等 Elastic Stack 相关组件,还与 Elastic 官方合作向用户提供 免费白金版 X-Pack 商业套件, 用户可以在商业套件上体验如 Security, Altering, Monitoring, Graph, Reporting, MachineLearning 等高级特性。
在开源系统的基础之上, 阿里云ES还提供了自研系统。自研系统部分主要包括 Elasticsearch 增强优化,Eyou 智能诊断系统和 ElasticFlow 离线数据处理平台等。其中 Elasticsearch 增强优化是阿里云在原生 Elasticsearch 基础之上,借助云计算和自研能力,为 Elasticsearch 集群增加了弹性伸缩,冷热数据分离,高可用,向量检索,中文分词等功能,可以帮助用户轻松应对业务压力,集群成本,数据可靠性,查询效果等问题。智能诊断系统 Eyou 可以智能地对用户的集群进行诊断,及时发现集群潜在隐患,并对用户集群给出合理的优化建议。
ElasticFlow 离线数据处理平台致力于解决如全量数据写入和复杂处理逻辑实时写入等情况下的业务瓶颈,为用户集群迁移,数据再处理,实时写入性能优化等提供了新的解决方案。
阿里云 Elasticsearch 致力于打造基于开源生态的,低成本的,场景化的云上 Elasticsearch 解决方案,源于开源,又不止于开源,目前已经覆盖了全部阿里云数据中心,并支持本地化专用云交付和混合云方案。

二、阿里云 Elasticsearch 内核优化实践
阿里云在内核优化方面的实践主要分为通用增强和场景化内核两部分。通用增强针对于通用的Elasticsearch场景进行优化,主要包括性能优化,高可用方案,稳定性保障和成本优化等。场景化内核当前已经提供了对日志场景,搜索场景,时序场景进行的优化,后续会不断持续地推出更多场景优化方案。

三、通用增强 - 性能优化
离线数据处理平台
为了解决全量数据写入和复杂数据处理逻辑实时写入等场景的业务痛点,阿里云ES推出了离线数据处理平台ElasticFlow。
原生Elasticsearch集群在进行数据导入,集群迁移等全量数据写入操作时,集群的读写性能会受到较大影响,且由于全量写入数据较多处理时间较长,当面临海量数据时,耗时往往无法接受。 Elastic Flow 针对于这种场景推出了全量 ElasticBuild。

当用户需要将数据从 RDS, ODPS, SLS, KAFKA, ES 等其他数据存储组件迁移到新的 Elasticsearch 集群时,可以先将数据流接入 ElasticBuild。ElasticBuild 底层使用 Blink,对导入的数据进行并发索引构建。接着将构建好的索引文件存储在 OSS 中。目标集群通过原生 Elasticsearch 的 Snapshot restore 操作即可快速地完成数据导入。
全量 Elastic Build 由于在集群外部进行,因此索引构建过程对集群读写性能无影响,且由于使用 blink 将索引构建过程并发起来,并通过内存索引合并减少磁盘IO, 从而大大降低了索引构建时间,加快索了引构建速度,对于解决海量数据全量导入耗时过长问题效果显著。
将索引构建操作移到集群外部进行,虽然解决全量数据写入的性能问题,但无法使用 Elasticsearch 原生的 translog 来解决 failover 问题。对此, ElasticFlow 使用了 Blink 的 checkpoint 来实现 failover,相对于 translog 降低了一倍的 IO 开销,并可以实现 At Least Once 数据准确和秒级 Failover。
针对于复杂处理逻辑实时写入场景,ElasticFlow 推出了增量 ElasticBuild,通过将处理逻辑移至集群外部进行,减少 client node 的计算和网络开销。
Elastic Flow 离线数据处理平台充分利用阿里云在大数据处理的优势,通过优化全量 Build 相对于在线 build 性能提升3倍,增量数据 build 相对于实时写入性能提升了30%。
通用物理复制
原生 Elasticsearch 在进行写操作时,主副分片都需要进行写 translog 和写索引操作。写 translog 是为了保证数据的高可用,主副分片都需要单独保证。但是索引构建和 segment merge 等操作不一定需要主副分片分别重复执行。基于这种思想,我们推出了物理复制功能。

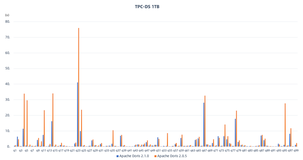
物理复制的基本原理是:Elasticsearch 主分片写入机制与原生 Elasticsearch 一样,既写索引文件也写 translog,而副本分片只写 translog 以保证数据的可靠性和一致性。主分片在每次 refresh 时,通过网络将增量的索引文件拷贝到副本分片,在主副分片分配可见性延迟略增加的情况下,大幅度提高了集群的写入性能。我们使用 esrally 自带的 nyc_taixs 数据集对 8 核 32GB 5 节点+2TB SSD 云盘集群进行测试,与原生 Elasticsearch 相比,阿里云 Elasticsearch 在开启了物理复制功能后,写入性能提升大于 45%。
四、通用增强 - 高可用方案
起新下老与读写分离
原生 Elasticsearch 在进行集群升级操作时有一些限制,如集群升级前要进行升级检查,本地升级集群中有不同版本节点容易出现兼容性问题,跨大版本升级要先升级到中间版本,不支持回滚等。为了解决平滑升级等问题,我们推出了起新下老和读写分离功能。
如下图,当需要升级集群 cluster1 时,我们先创建一个新版本的集群 cluster2,然后在 cluster1 和cluster2 的 client 与集群之间引入 nginx 实现读写分流,client 的读请求仍然落到原集群,写入请求落入一个异步数据处理服务。该异步数据处理服务可以接收对 Elasticsearch 的写入请求,并将写入操作存储在消息队列等数据储存组件,最后消费数据双写到 cluster1 和 cluster2。对于 cluster1 存量数据可以使用 ElasticFlow 全量 build 等方式同步到 cluster2。引入该架构后,cluster1 和cluster2 可以实现近实时数据同步,用户可以在 cluster2 上验证新版本功能,如果 cluster2 符合预期,则将 cluster1 下线,实现平滑升级,当 cluster2 不符合预期是,将 cluster2 下线,实现业务回滚。

起新下老和读写分离架构,在不影响原有集群业务的前提上,通过引入异步数据链路实现了新老集群的数据同步,对业务影响小,可以实现业务平滑升级和回滚,解决了 Elasticsearch 版本升级中面临的多种业务痛点。
数据备份
为了保证数据的高可用,阿里云 Elasticsearch 提供了数据自动备份功能。用户可以在阿里云 Elasticsearch 官网控制台通过简单配置,开启数据自动备份功能。开启后,Elasticsearch 集群会定时将数据快照备份到 OSS 仓库中。一旦集群出现异常,用户可以从 OSS 仓库中恢复数据,快速恢复业务。
跨可用区部署
阿里云 Elasticsearch 支持用户将集群部署在多个可用区。当单个可用区由于自然灾害或其他原因导致不可用时,阿里云 Elasticsearch 会自动检测可用区异常,并快速将故障可用区隔离。可用区故障期间,阿里云 Elasticsearch 会保障用户集群的可用性。若短期内故障可用区可以正常恢复,则集群会自动将故障节点加回集群,若故障可用区无法短期恢复,阿里云 Elasticsearch 会在其他可用区为集群创建数量及规格相同的节点恢复集群。采用跨可用区部署的集群可以实现自动的故障可用区检查,隔离及恢复,期间业务零影响,可以帮助用户在无感知的情况下平稳度过可用区故障。

五、通用增强 - 稳定性保障
Master 调度优化
原生 Elasticsearch 当集群分片数过多时,集群索引创建和删除耗时会显著增加。我们实际中遇到的一个典型用户集群有 3 个专用主节点,10 个热节点,2 个冷节点,超过 5 万个 shard, 索引创建和删除耗时超1分钟。通过对集群性能瓶颈和ES实现逻辑分析,我们最终发现原生 Elasticsearch 的 reroute 逻辑是性能瓶颈存在优化空间。通过引入新的数据结构,我们将 reroute 的调度算法复杂度从O(n^2) 降低到了 O(n), 万级分片集群索引创建和删除时间也降低到了 1s, 当前该PR已经提交并作为 co-author 合并
(https://github.com/elastic/elasticsearch/pull/48579)。
阿里云 QOS
为了帮助用户 Elasticsearch 集群更好地应对业务流程高峰,阿里云ES提供了阿里云 QOS 功能。使用该功能用户可以对集群的节点和索引级别的流量进行限流配置。当业务流量突增时,可以将流量控制在设定的范围内,保证集群稳定性。用户可以对不同的索引和节点设置不同的限流配置,在流量高峰时优先保证核心业务。该功能支持动态开关调整及动态限流规则调整,可以帮助用户在业务流量高峰时及时灵活地调整限流规则。
六、通用增强 - 成本优化
数据压缩
为了降低存储成本,原生 Elasticsearch 会对 store filed,doc_values 等进行数据压缩,以降低这些数据的存储空间。原生 Elasticsearch 提供的压缩算法是 LZ4 和 best-compression, 其中 LZ4 有较好的压缩性能,best-compression 有较高的压缩率,用户可以根据业务的情况选择符合业务场景的压缩算法。为了进一步提高数据的压缩率,阿里云 Elasticsearch 引入了 brotli 和 zstd 两种压缩算法。这两种压缩算法在保证读写性能的基础之上进一步提高了数据的压缩率,相对于 LZ4 提供了45%, 相对于 best-compression 提升了8%。
下表是使用 esrally 自带 nyc_taxis(74GB),对 16 核 64GB 3 节点 2TBSSD 磁盘集群,使用不同压缩算法的测试结果。

弹性伸缩
通过对大量 Elasticsearch 集群的分析,我们发现相当一部分集群存在明显流量的高/低峰情况。业务高峰时,集群承受较大的压力,集群的性能和稳定性面临挑战。业务低峰时,节点资源闲置,出现资源浪费。针对有明显高/低峰期规律的集群,阿里云ES近期新推出了弹性伸缩功能。该功能允许用户在创建集群时除了购买常规的集群节点,还可以额外购买一种新的节点类型——弹性节点,并可以指定弹性节点的扩容和缩容时间。通过这种方式创建出来的集群会根据用户设定的时间扩容弹性节点和缩容弹性节点。对于业务存在明显流量高峰和低峰的集群,可以使用该类型集群,在业务高峰时扩容出弹性节点,保证集群的性能和稳定性,在业务低峰时缩容弹性节点,降低集群成本,防止资源浪费。

七、场景化内核 - 场景化推荐模板
Elasticsearch 的优势之一是上手快,集群搭建简单,初学者即可通过简单的配置快速拉起一个 Elasticsearch 集群,这一优势得益于 Elasticsearch 合理的默认配置。这些默认配置不仅帮助用户简化集群搭建成本,集群在功能和性能上也都会有不错的表现。然而 Elasticsearch 的默认配置是针对所用场景通用的,在特定使用场景下并不一定是最优的。基于这种思想,阿里云 Elasticsearch 推出了场景化推荐模板功能。

场景化推荐模板基于阿里云 Elasticsearch 丰富的 Elasticsearch 使用,运维和内核优化经验,根据用户的使用场景为用户推荐符合其使用场景的集群配置,索引模板和索引生命周期管理策略等。用户只需要在创建集群时指定其使用场景,其创建出的集群就会将上述推荐模板自动配置到集群中。用户还可以在后续使用中根据业务的实际情况对推荐模板进行调整。
八、场景化内核 - 日志场景
日志场景是典型的写多读少场景,数据量较大,对存储成本比较敏感,为此我们主要针对存储成本进行优化,包括计算存储分离和冷热分离等。
计算存储分离
原生 Elasticsearch 通过多副本的方式来保证数据高可用。然而在云计算环境下,集群节点底层存储通常使用云盘,云盘为了保证数据高可用已经对数据保存了三副本。这样对于开启一副本的索引,云计算环境下相当于保存了六份数据,这对于存储空间是一种巨大的浪费。基于这种思想,阿里云 Elasticsearch 推出了计算存储分离功能。

计算存储分离功能使用 NFS 共享存储作为节点底层存储,多个节点共享一份底层存储。主分片使用 ReadAndWriteEngine 既可进行写操作又可以进行读操作。副本分片使用 ReadOnlyEngine 仅提供读操作。集群写入文档时,只对主分片进行写操作,主分片定时将增量 segment 拷贝到副本分片的临时目录保证副本分片的实时性。
计算存储分离架构多节点底层共享一份数据文件,实现了一写多读,在将写入性能提升 100% 的情况下,成倍降低了存储成本。数据的高可用由底层 NFS 的三副本来保证。另外由于多个节点共享一份存储,扩缩新节点时不需要进行数据的拷贝操作,因此可以提供秒级弹性扩缩容能力。
冷热分离
相当一部分 Elasticsearch 的集群存在明显的数据热点情况。用户的读写操作往往只集中在部分数据集上,其他数据的读写频率很低。对于日志场景,这种情况尤其明显,用户的读写操作主要集中在最近一段时间的索引,对于历史索引的读写操作很少。针对于这种情况,阿里云 Elasticsearch 推出了分热分离功能。
使用冷热分离功能,用户可以在创建索引时除创建正常数据节点外,额外指定一定数量的冷节点。数据节点使用计算资源和磁盘性能较好的机器,如核数内存较大的SSD磁盘机器,冷节点使用计算资源和磁盘性能较差的机器,如核数内存小的SATA磁盘机器。接着用户在 Elasticsearch 集群中为索引配置索引生命周期管理策略,即可实现新创建的索引落在热节点上,当索引创建超过一定的时间,会被迁移到冷节点上。这样一方面保证了热点数据在性能较好的节点上,数据读写性能得到保障,另一方面冷数据存储在性能较差的节点上,降低了集群成本。
九、场景化内核 - 搜索场景
向量检索库
阿里云基于达摩院高性能向量检索库为用户提供了向量检索功能,该功能已成熟应用于手淘猜你喜欢、拍立淘、优酷视频、指纹识别等大规模生产应用场景。该功能使用 Elasticsearch Codec 机制将高性能向量检索库与 Elasticsearch 结合,完美兼容 Elasticsearch 分布式能力。基于 Hnsw 算法,无需训练,查询速度快,召回率高。

下表是使用阿里云6.7.0版本ES对向量检索功能的测试结果:
机器配置:数据节点16c64g*2 + 100G SSD云盘
数据集:sift128维float向量
数据量:2千万

阿里分词
阿里云基于阿里巴巴 alinlp 分词技术推出了阿里分词功能,该功能支持多种模型和分词算法包括 CRF、结合词典的 CRF、MMSEG 等,应用于多种业务场景包括淘宝搜索、优酷、口碑等,提供近1G 的海量词库,并且支持热更新分词能力。
下图是几种分词器的分词效果对比

在对"南京市长江大桥"进行分词时,standard 分词器直接按照单个汉字进行分词,虽然有较高的查全率,但是查准率和查询性能很差,基本没有分词效果。中日韩文分词器 cjk 和 ik_max_word 虽然可以将短语切分为中文分词,但是其分词结果中出现了如"市长"等错误分词,虽然有较好的查全率和查询性能,但是查准率较差。ik_smart 分词器将短语分词为”南京市“和”长江大桥“,没有将”南京“,”长江“,”大桥“等作为单独分词,在查全率上表现不佳。而阿里分词将短语分词为”南京“,”市“,”长江“,”大桥“, 在查全率,查准率,查询精度等方面均有不错表现。
aliyun-sql
阿里云 Elasticsearch 最新还推出了 aliyun-sql 功能,该功能基于 Apache Calcite 开发了部署在服务端的 SQL 解析插件,使用此插件可以像使用普通数据库一样使用 SQL 语句查询 Elasticsearch 中的数据,从而极大地降低学习和使用ES的成本。
下表是 x-pack-sql, opendistro-for-elasticsearch, aliyun-sql 的功能对比图。可以看到,X-pack-sql 不支持 join 操作,也不支持 Case Function 和扩展 UDF。opendistro-for_elasticsearch 不支持分页查询,也不支持 Case Function 和扩展 UDF。而 aliyun-sql 对分页查询,Join,Case Function, UDF 等均有较好支持,功能更为全面。

阿里云 Elasticsearch 将阿里云丰富的云计算能力与 Elastic Stack 开源生态相结合。在为用户提供原生 Elastic Stack 服务的同时,不断地在 Elasticsearch 内核上进行优化实践。我们源于开源,又不止于开源,将不断地在内核方面做出更多的优化,回馈开源,赋能用户。

【阿里云Elastic Stack】100%兼容开源ES,独有9大能力,提供免费 X-pack服务(单节点价值$6000)
相关活动
更多折扣活动,请访问阿里云 Elasticsearch 官网
阿里云 Elasticsearch 商业通用版,1核2G ,SSD 20G首月免费
阿里云 Logstash 2核4G首月免费