热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
《Git 简易速速上手小册》第4章:Git 与团队合作(2024 最新版)
《Git 简易速速上手小册》第3章:分支管理(2024 最新版)
Java 中文官方教程 2022 版(二十七)(3)
《Git 简易速速上手小册》第2章:理解版本控制(2024 最新版)
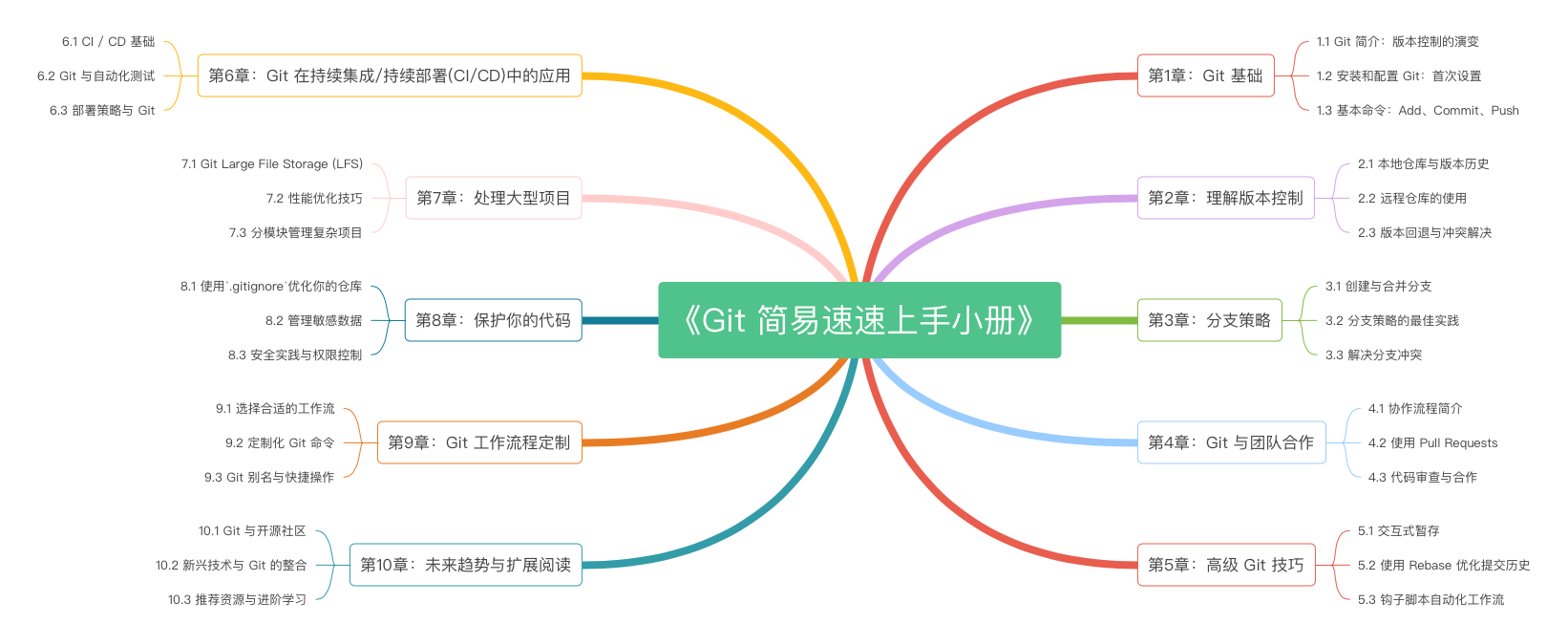
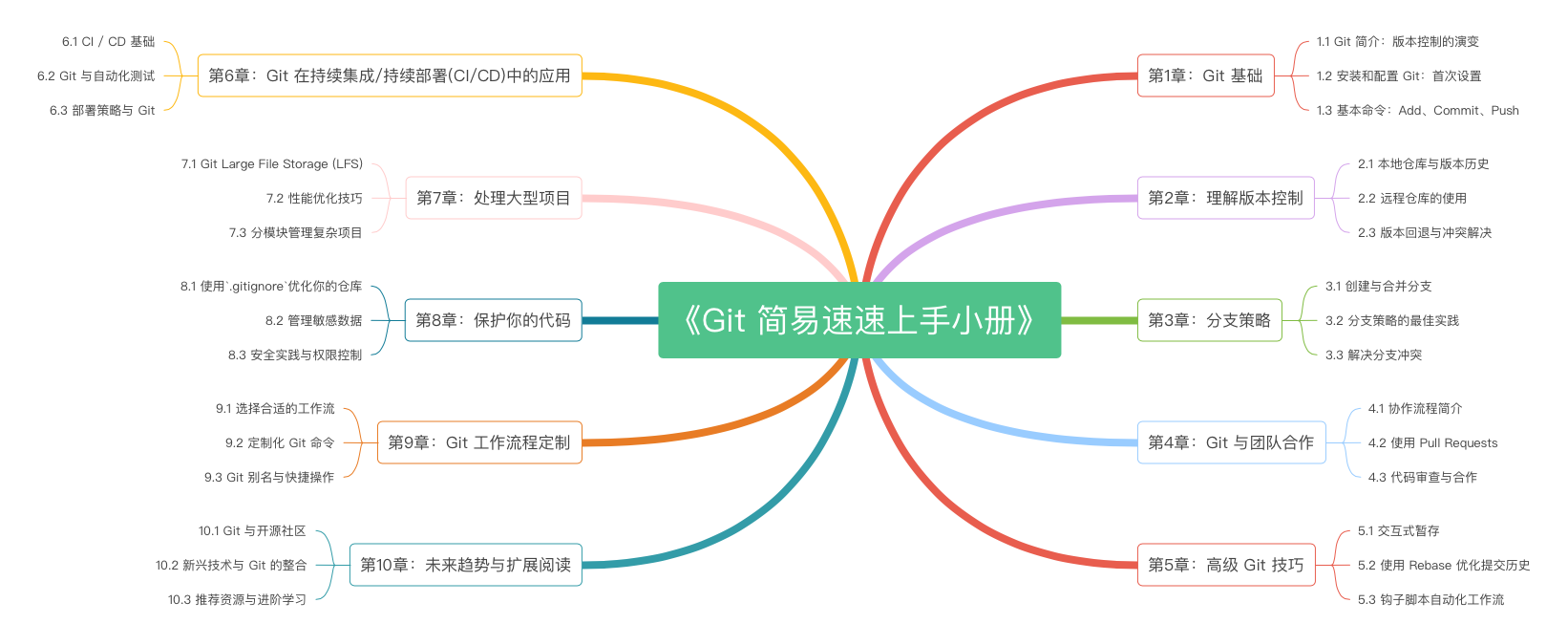
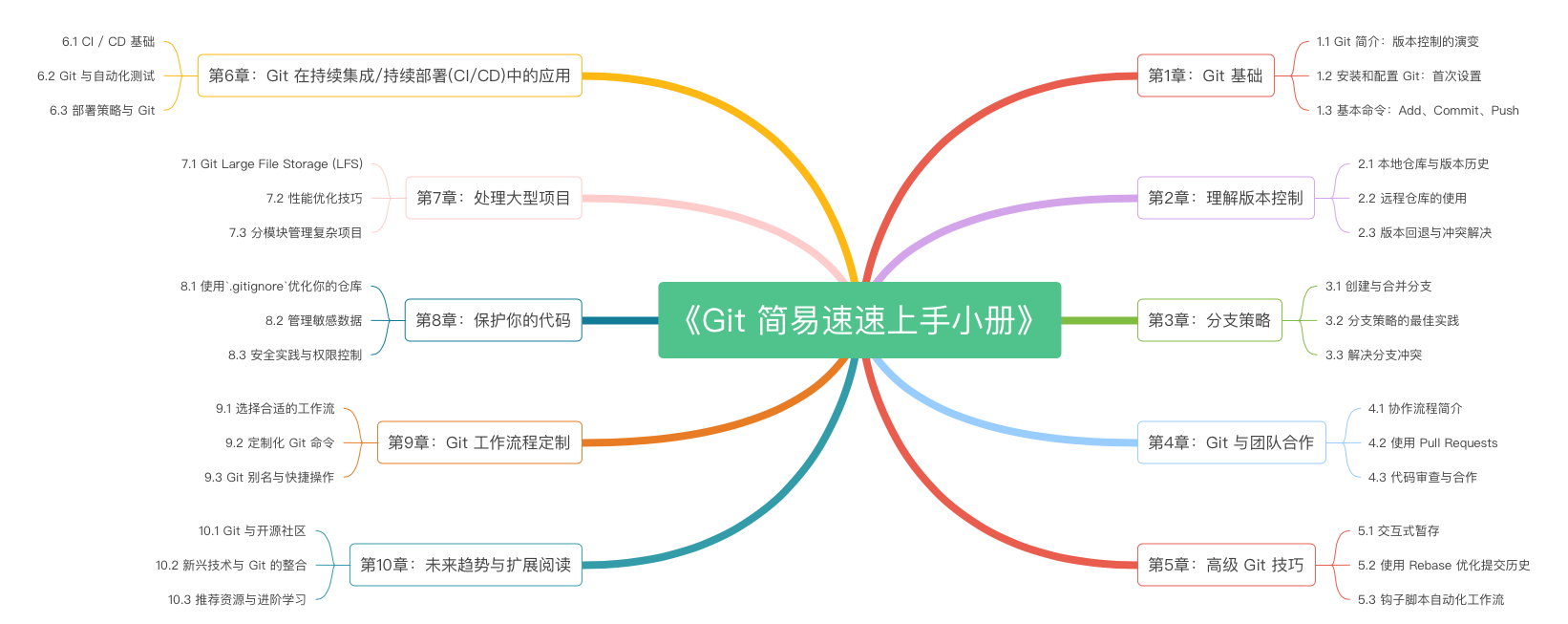
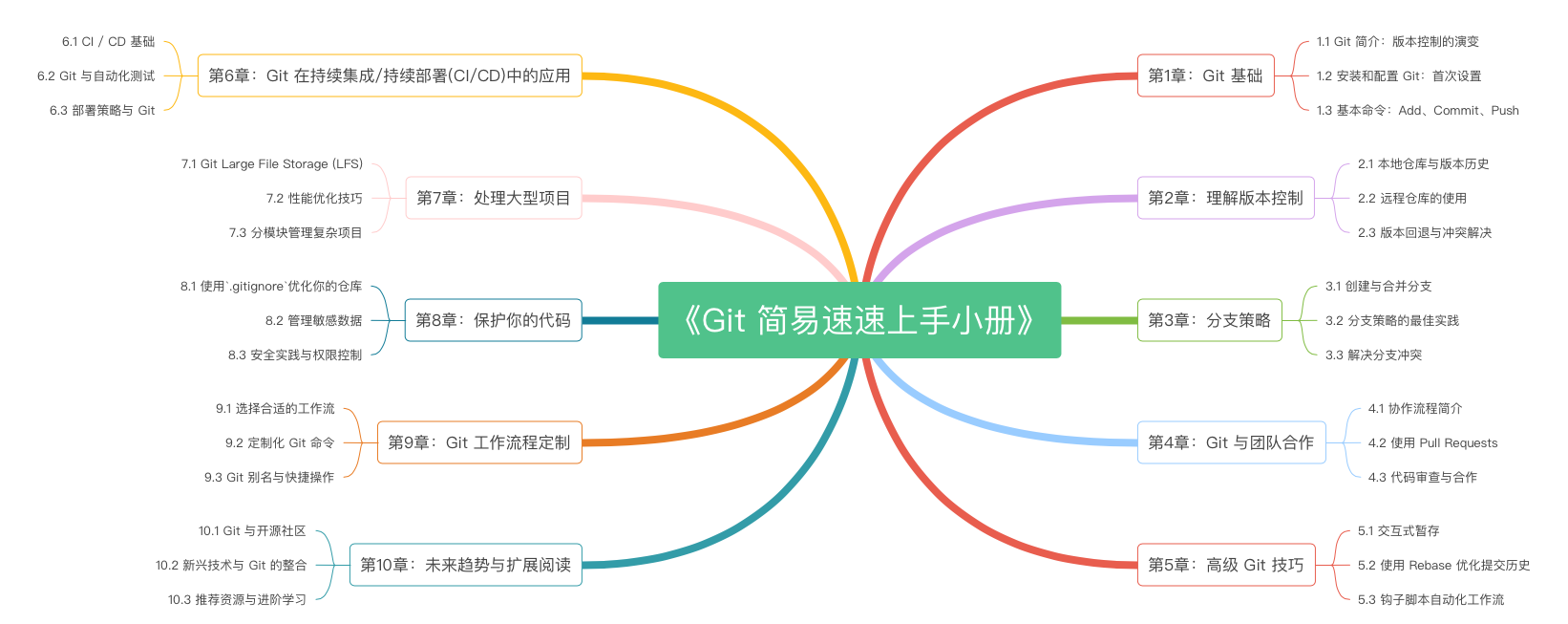
《Git 简易速速上手小册》第1章:Git 基础(2024 最新版)
Java 中文官方教程 2022 版(二十七)(2)
Redis数据库
Java 中文官方教程 2022 版(二十七)(1)
数字堡垒的构建者:网络安全与信息保护的现代策略
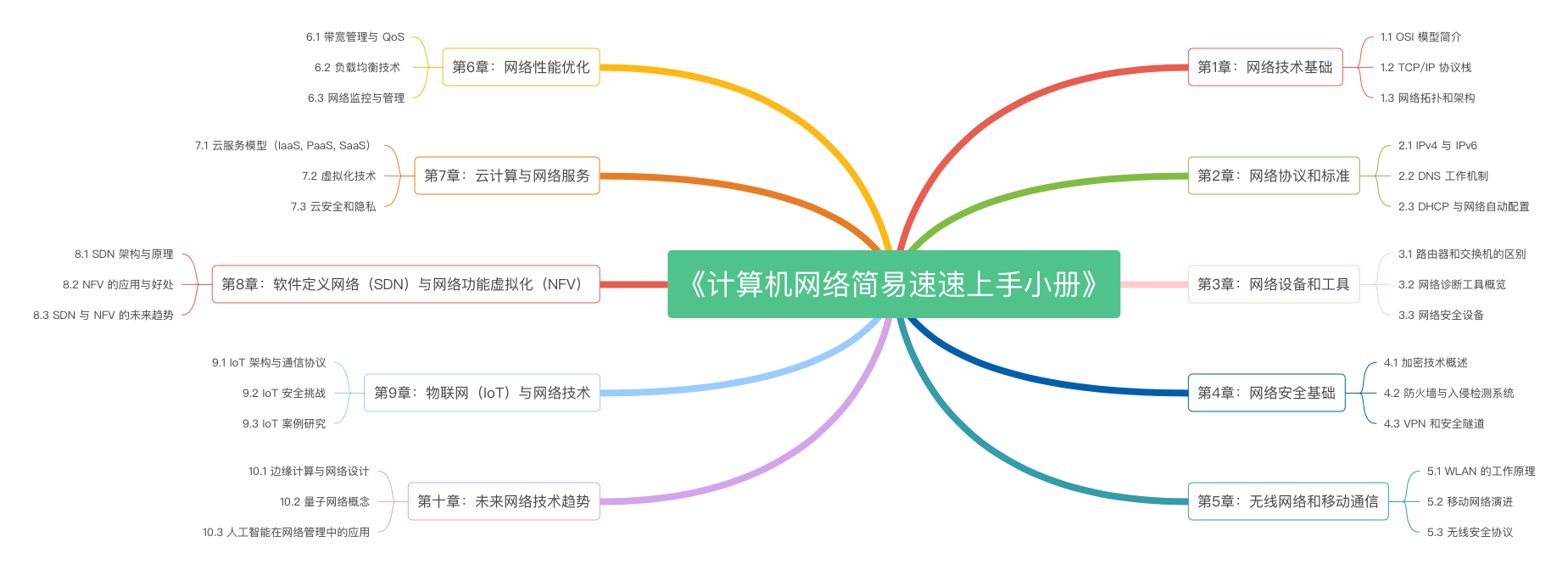
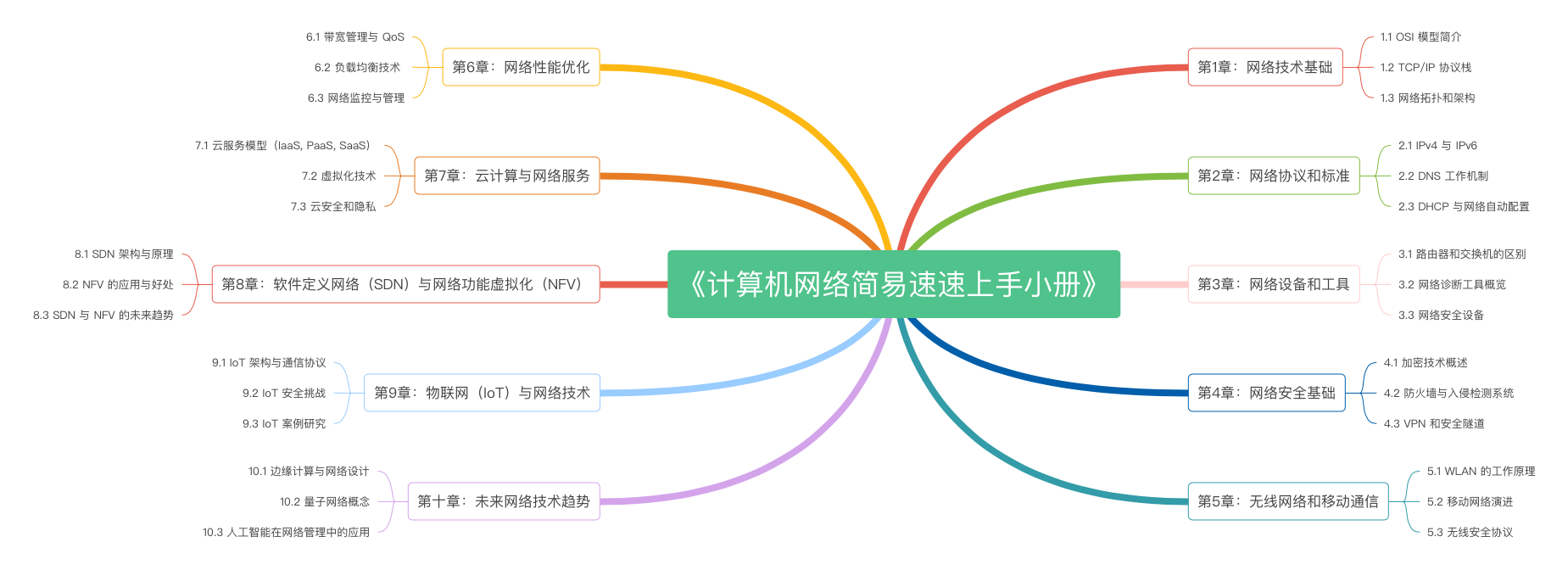
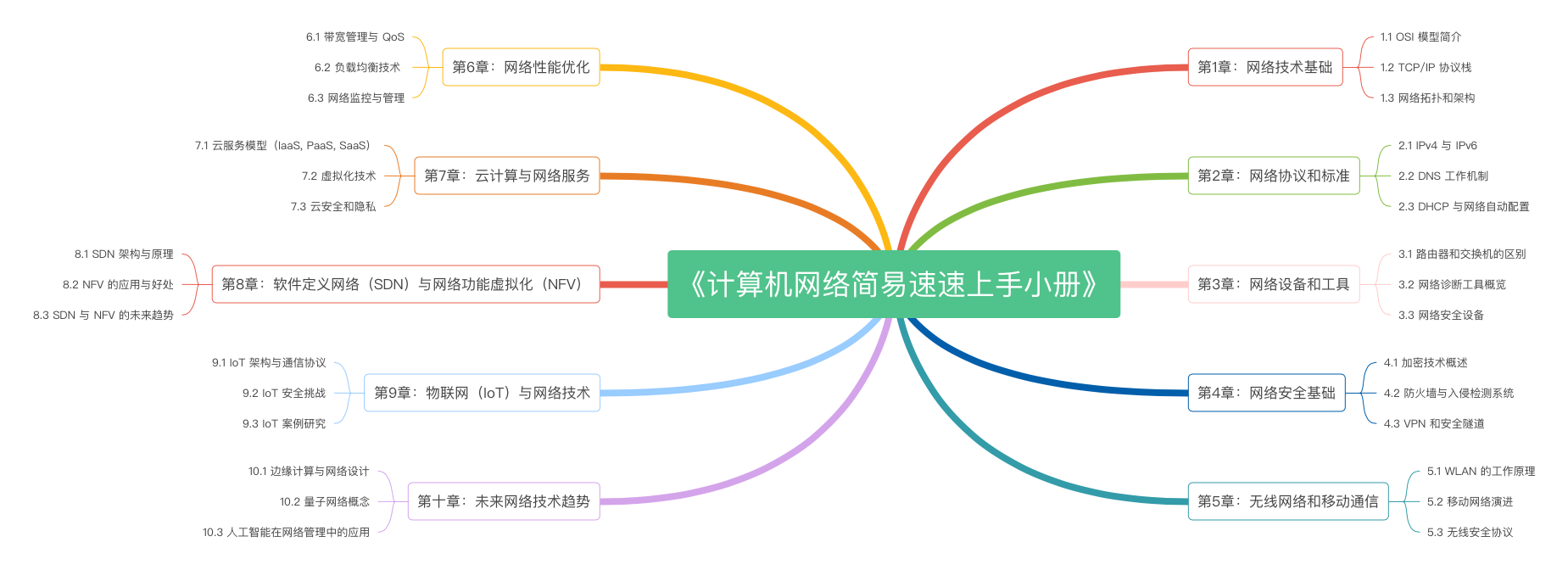
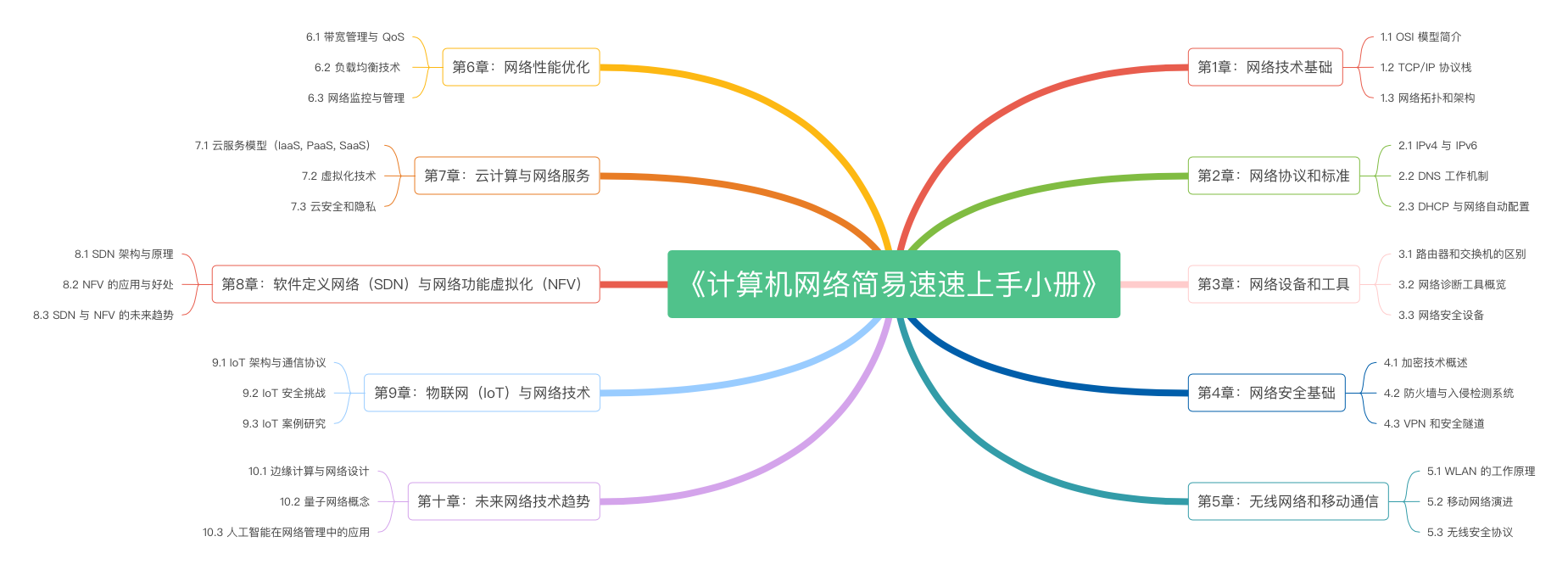
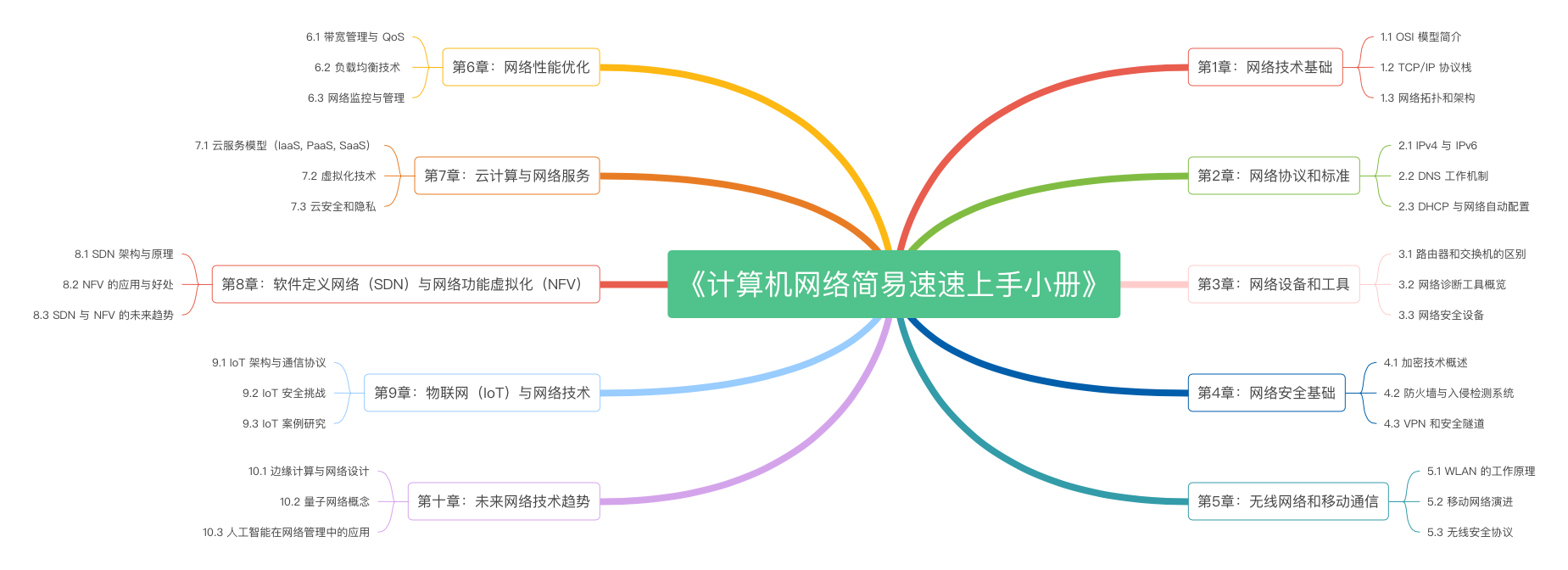
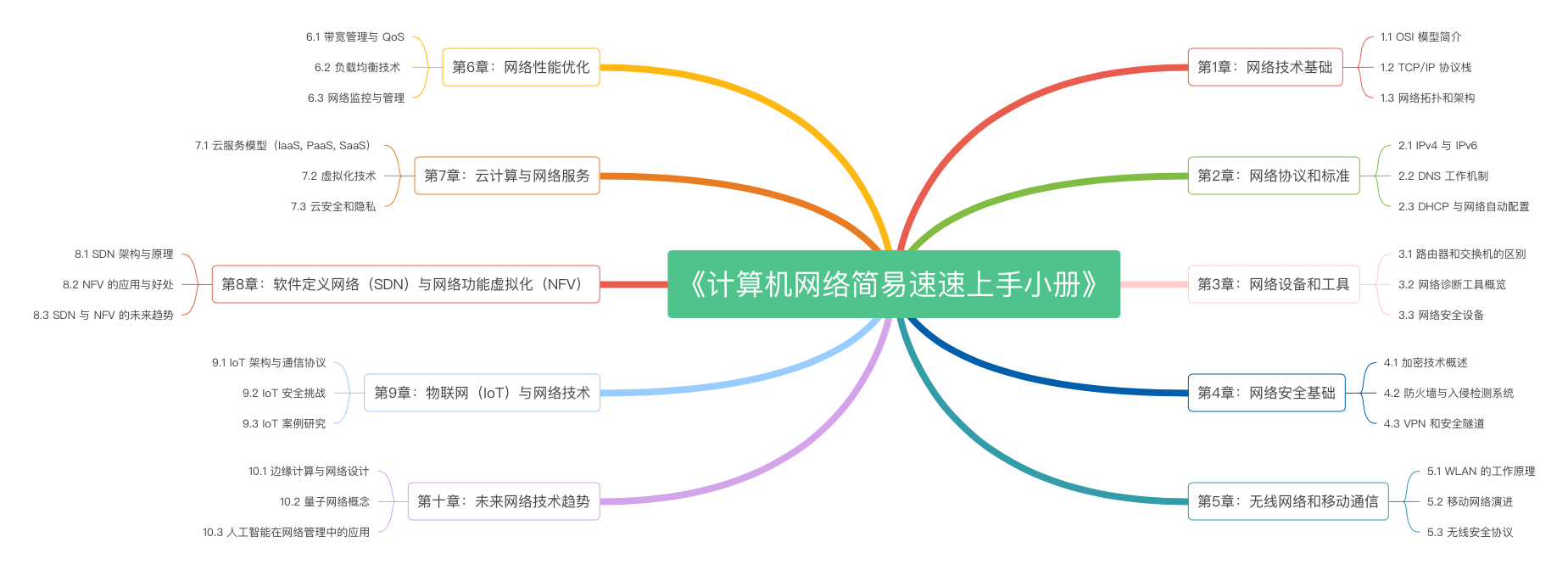
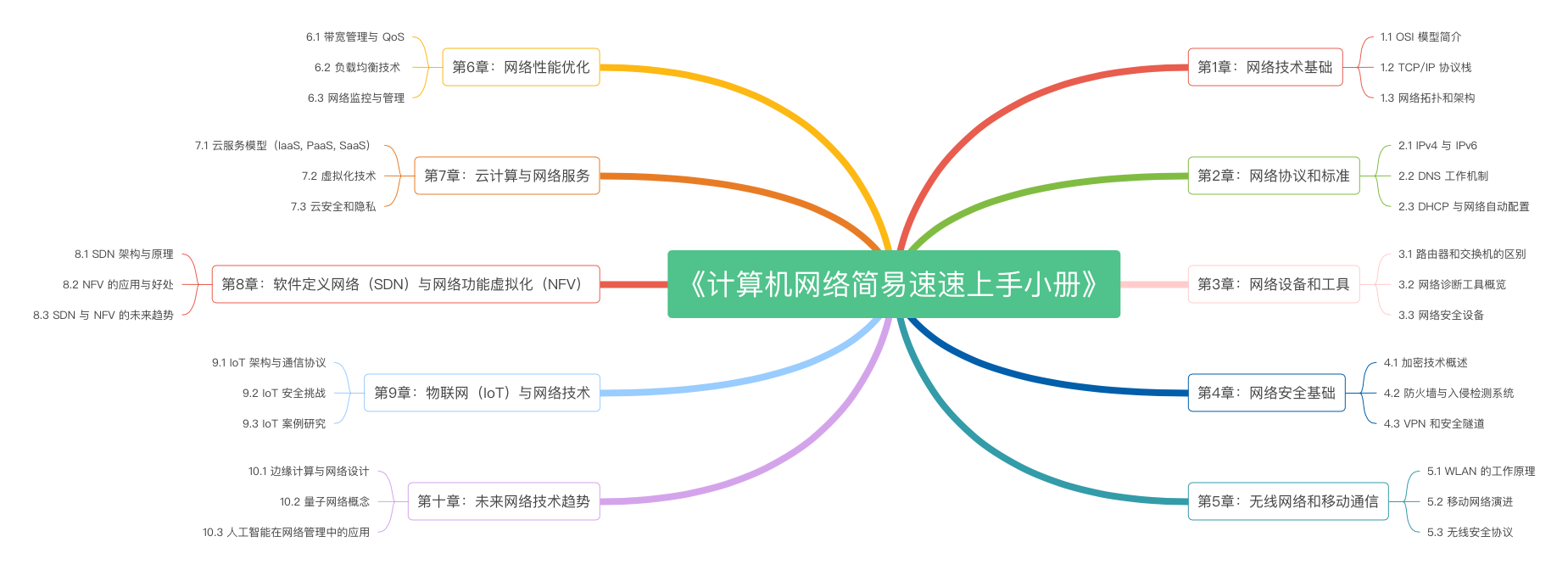
《计算机网络简易速速上手小册》第10章:未来网络技术趋势(2024 最新版)
《计算机网络简易速速上手小册》第9章:物联网(IoT)与网络技术(2024 最新版)
《计算机网络简易速速上手小册》第8章:软件定义网络(SDN)与网络功能虚拟化(NFV)(2024 最新版)
《计算机网络简易速速上手小册》第7章:云计算与网络服务(2024 最新版)
《计算机网络简易速速上手小册》第6章:网络性能优化(2024 最新版)
Java 中文官方教程 2022 版(二十六)(4)
《计算机网络简易速速上手小册》第5章:无线网络和移动通信(2024 最新版)
《计算机网络简易速速上手小册》第4章:计算机网络安全基础(2024 最新版)
《计算机网络简易速速上手小册》第3章:计算机网络设备和工具(2024 最新版)
明天!龙蜥在 2024 OceanBase 开发者大会上等你
《计算机网络简易速速上手小册》第2章:计算机网络协议和标准(2024 最新版)
Java 中文官方教程 2022 版(二十六)(3)
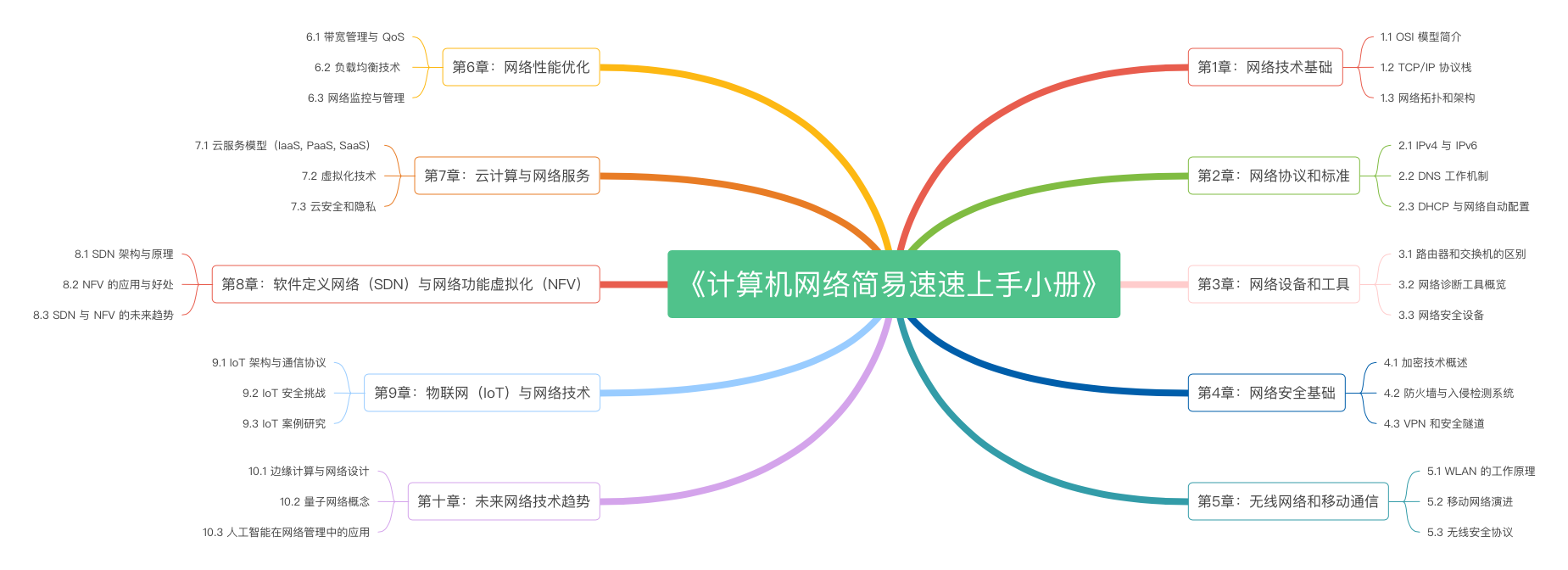
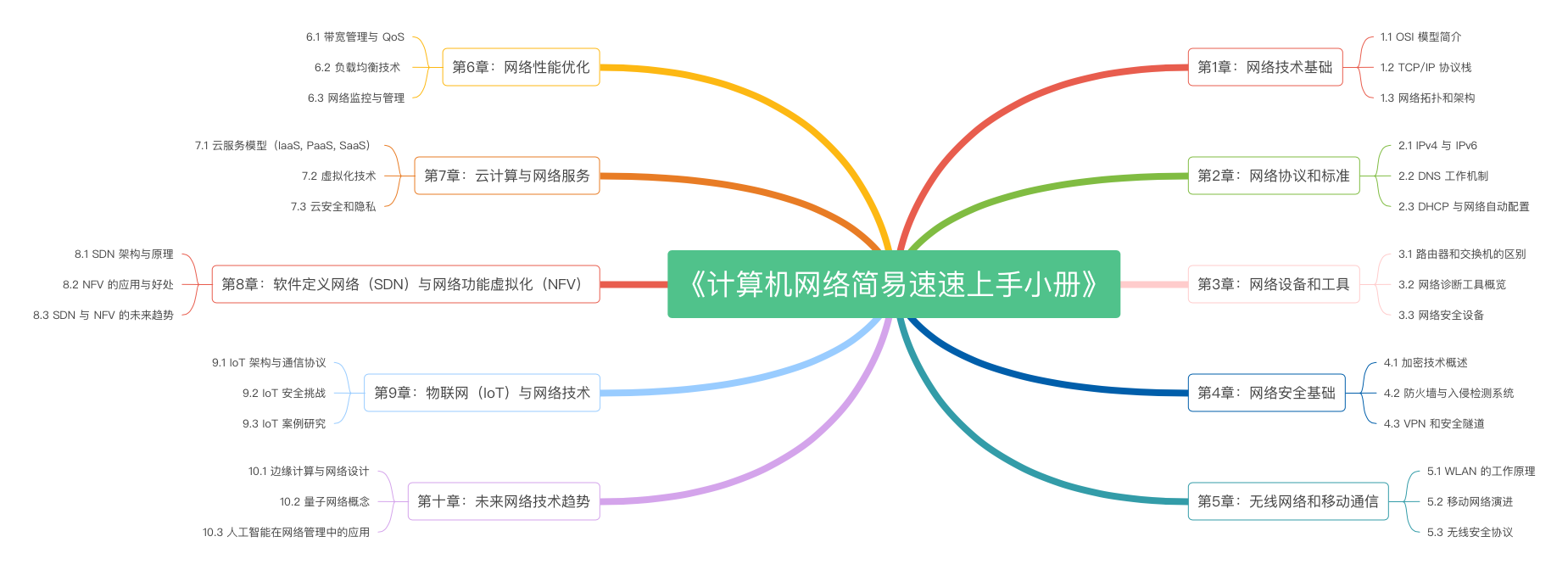
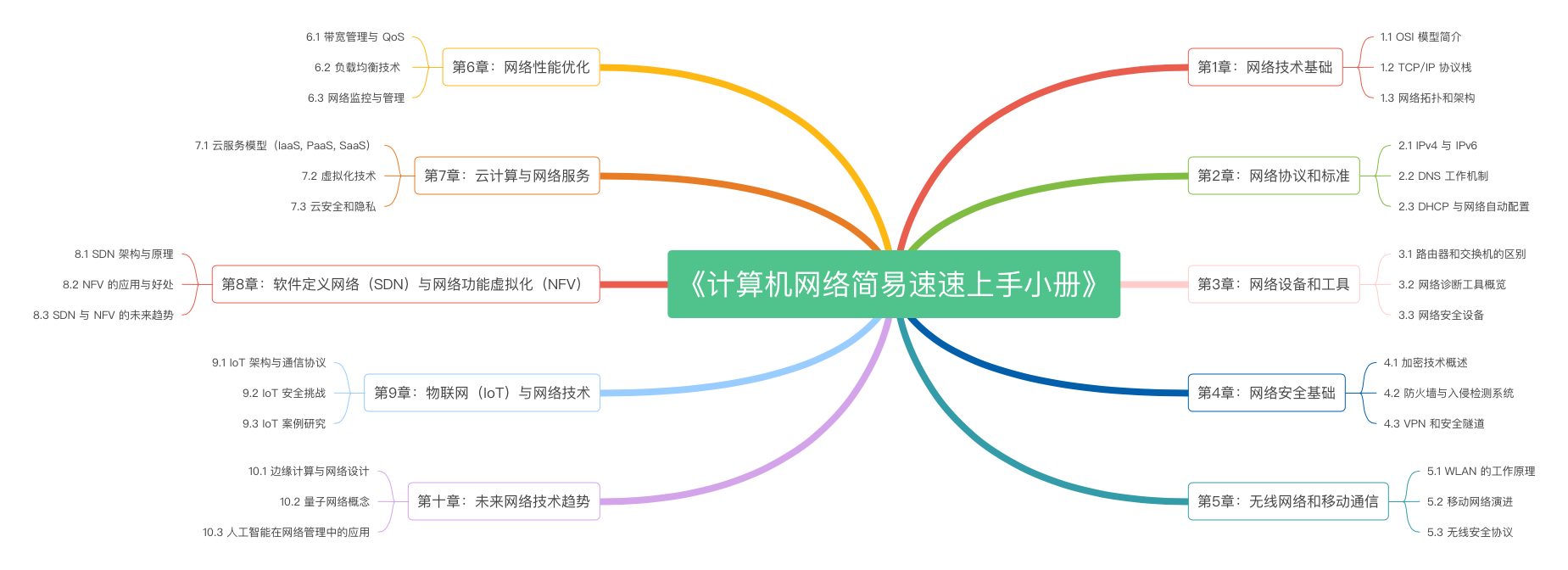
《计算机网络简易速速上手小册》第1章:计算机网络技术基础(2024 最新版)
新特性、新平台、新功能!Anolis OS 8.9 版本正式发布
阿里云服务器经济型e、通用算力型u1与c7/g7/r7/c8y/g8y/r8y实例区别及选择参考
从故障演练到运维工具产品力评测的探索 | 龙蜥技术
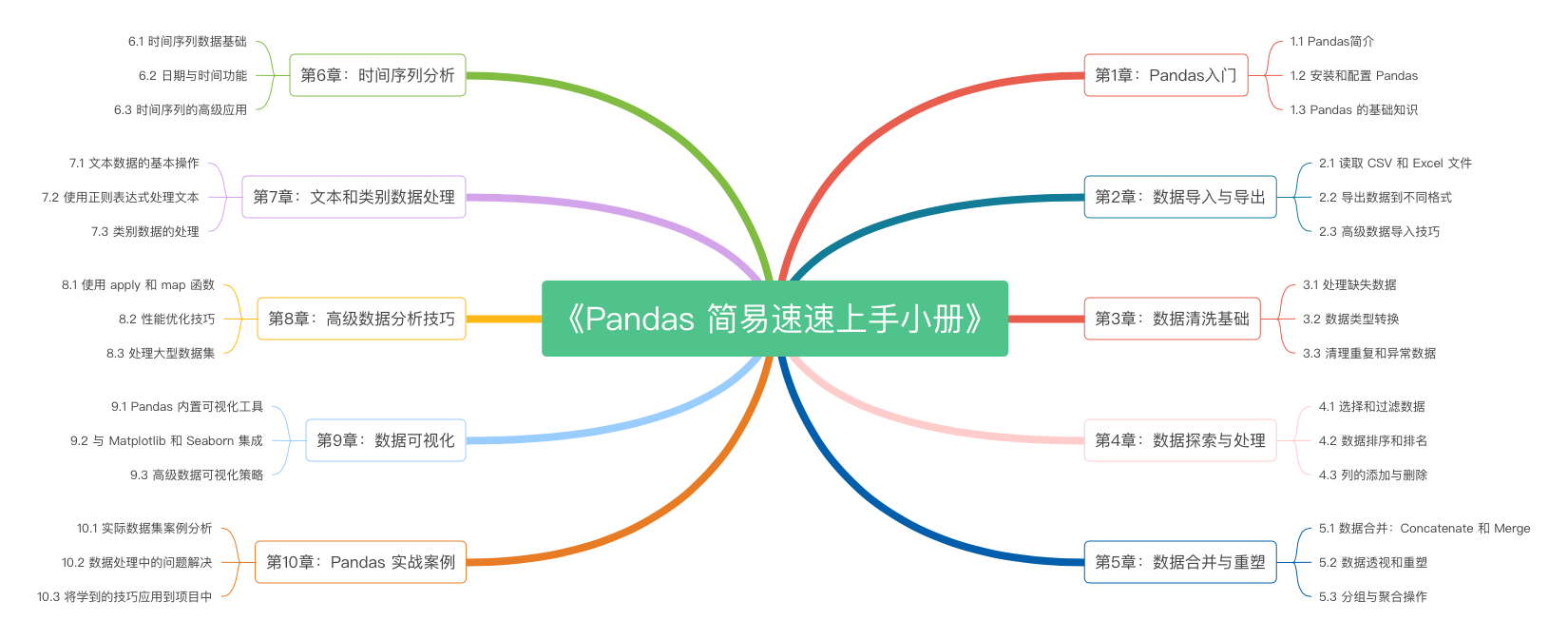
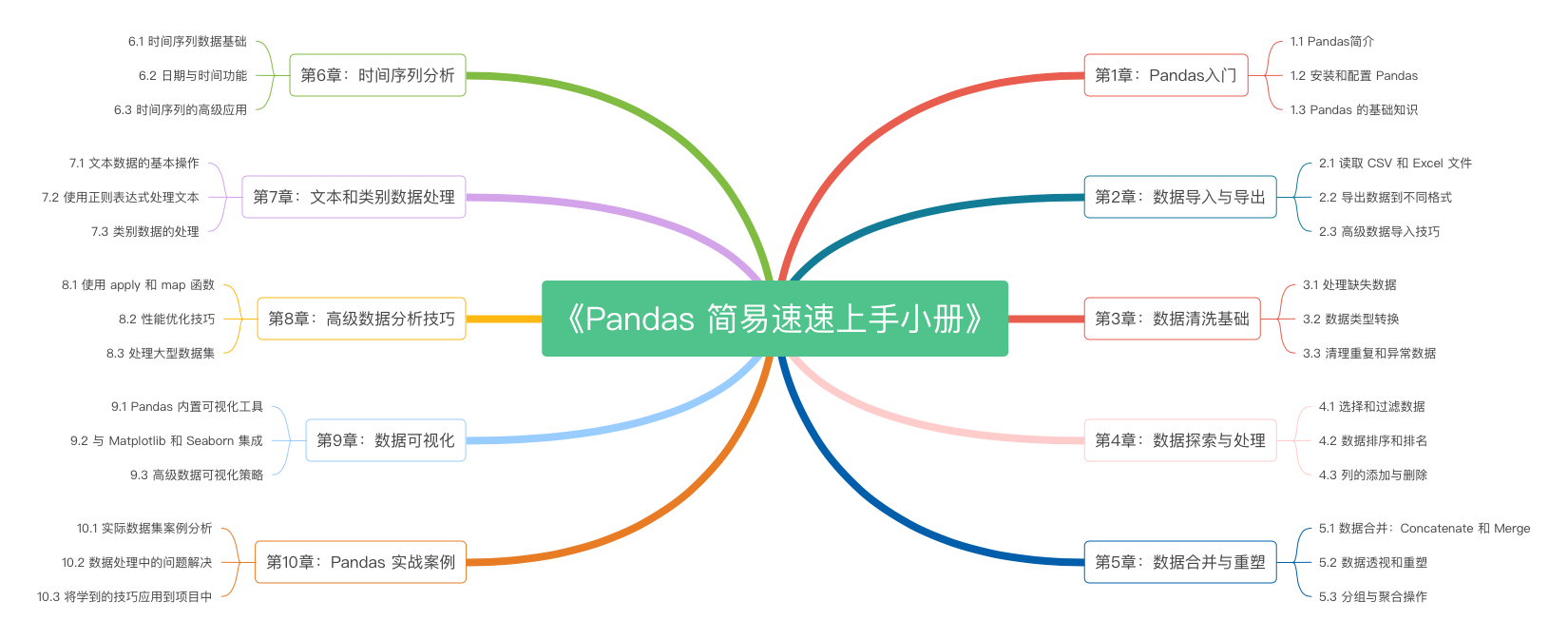
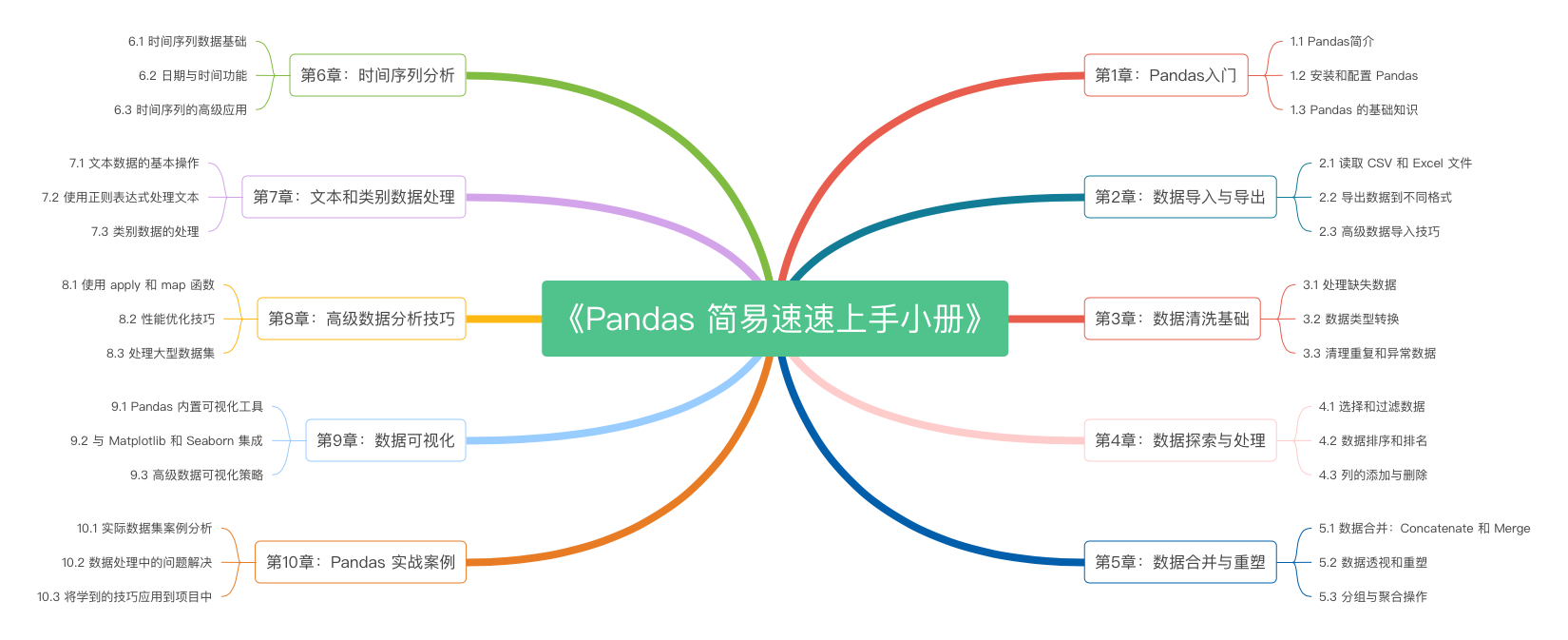
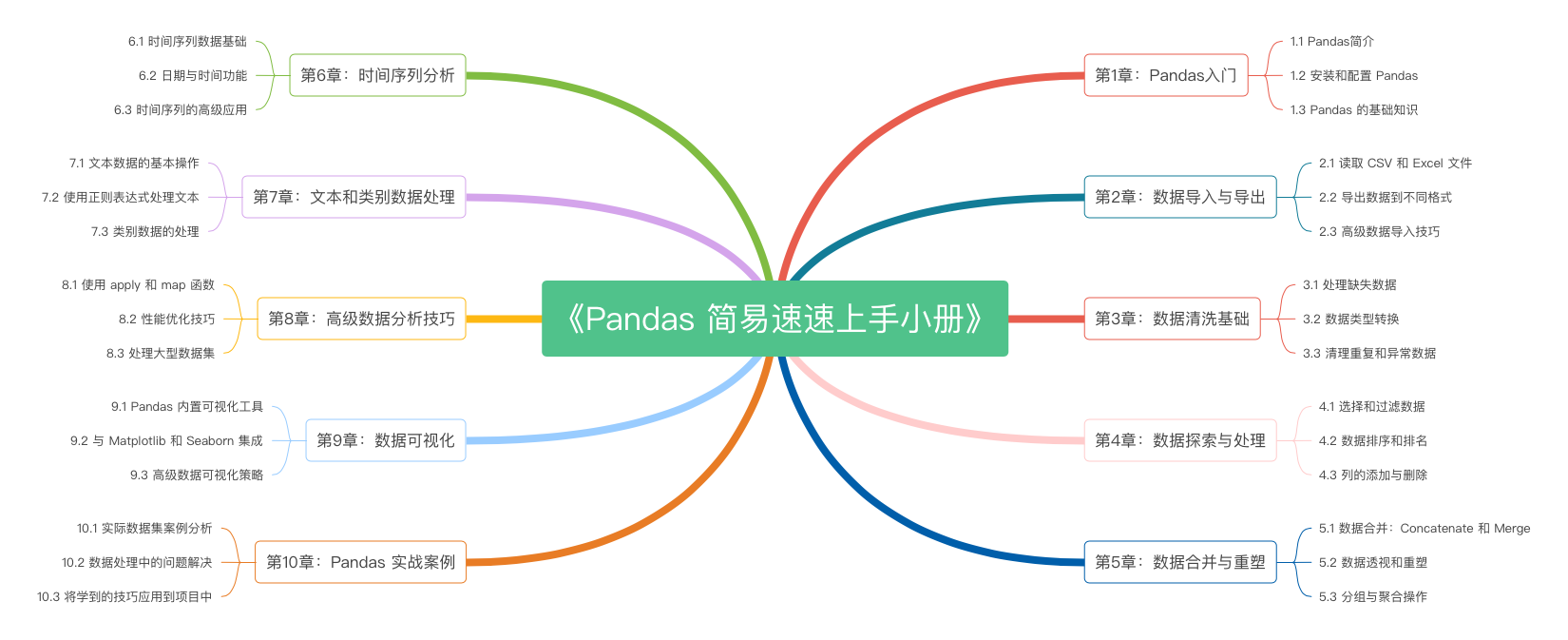
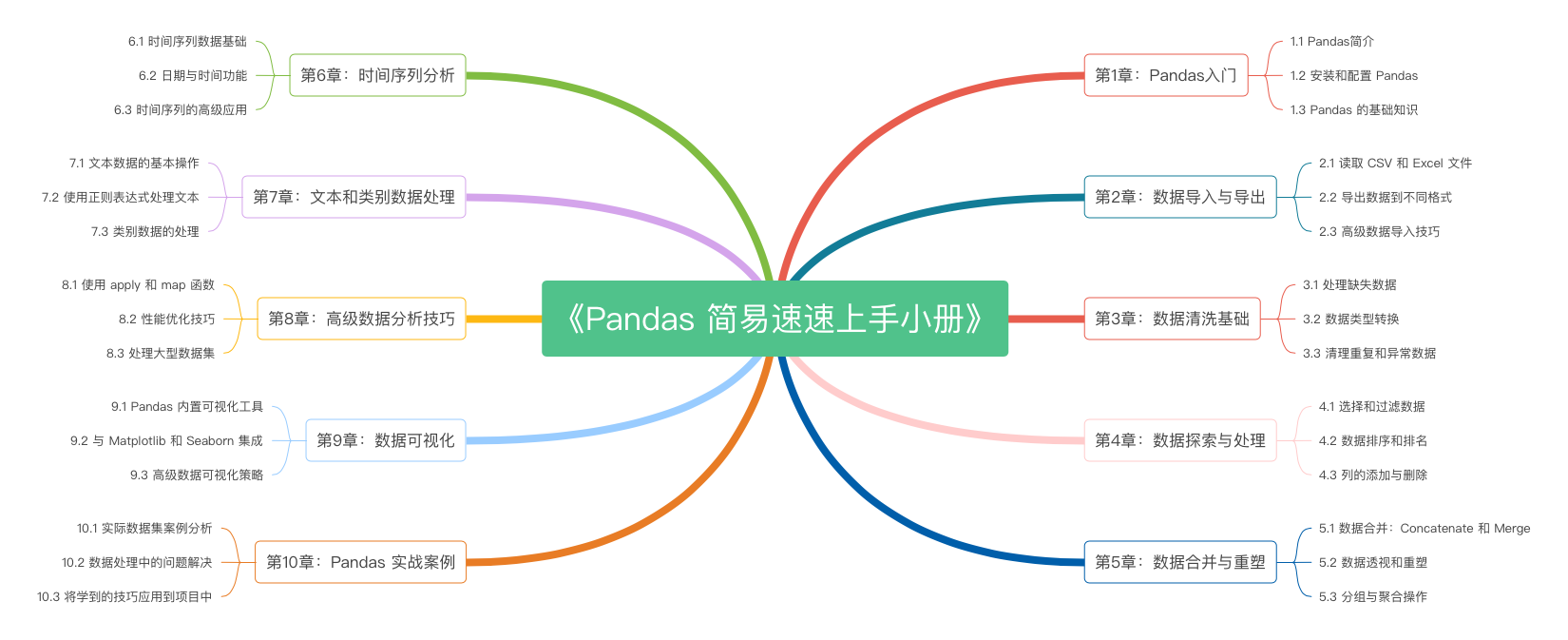
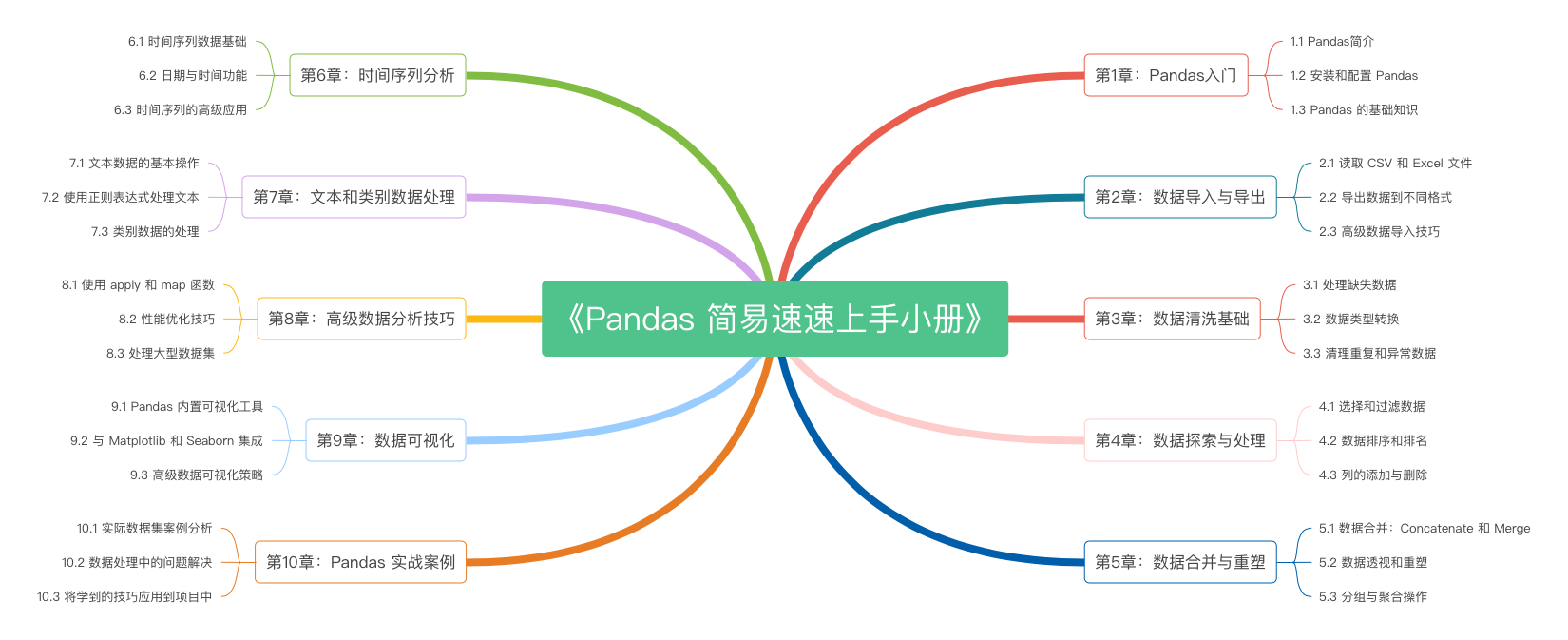
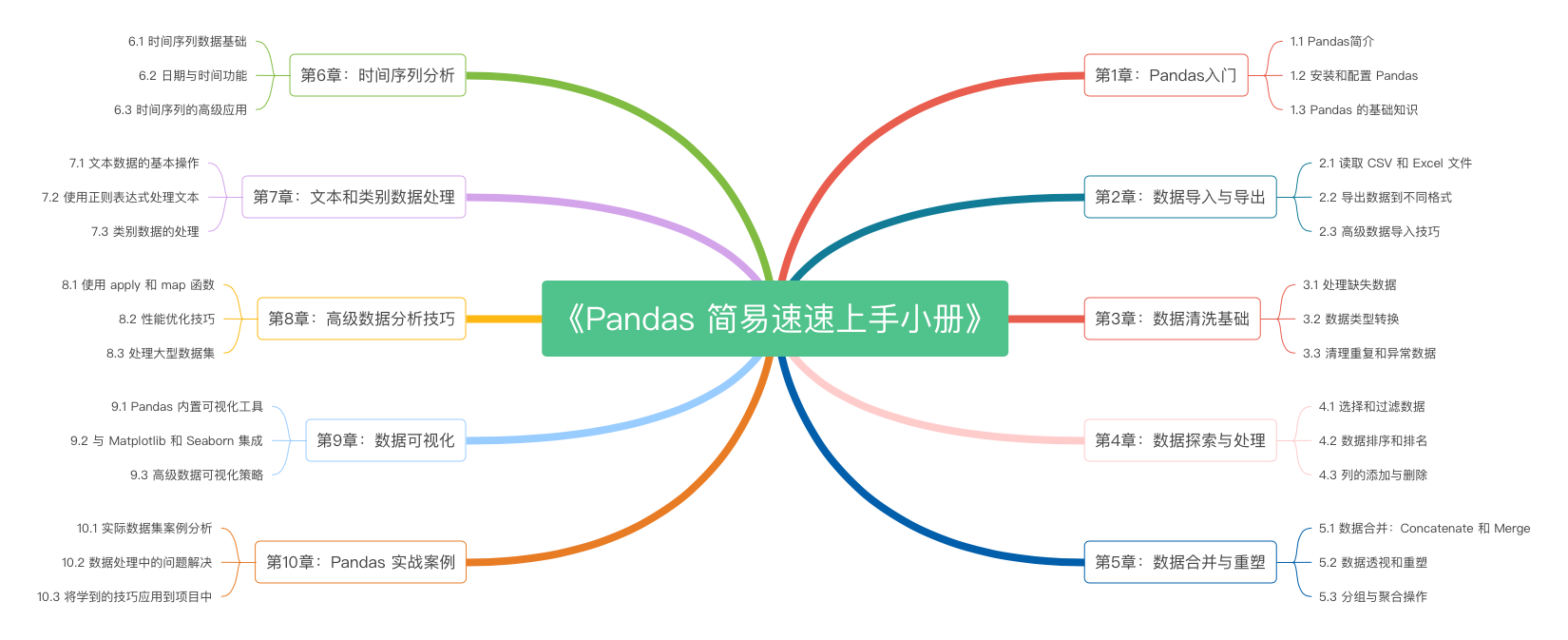
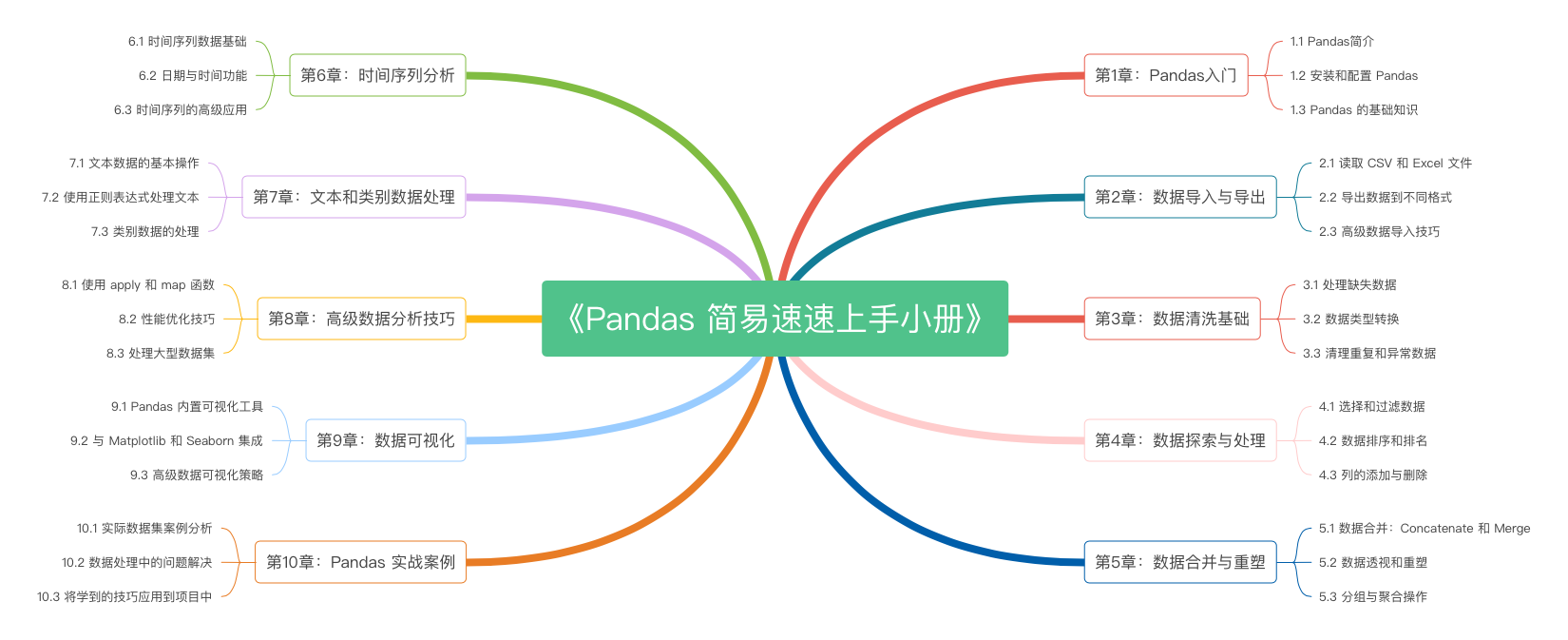
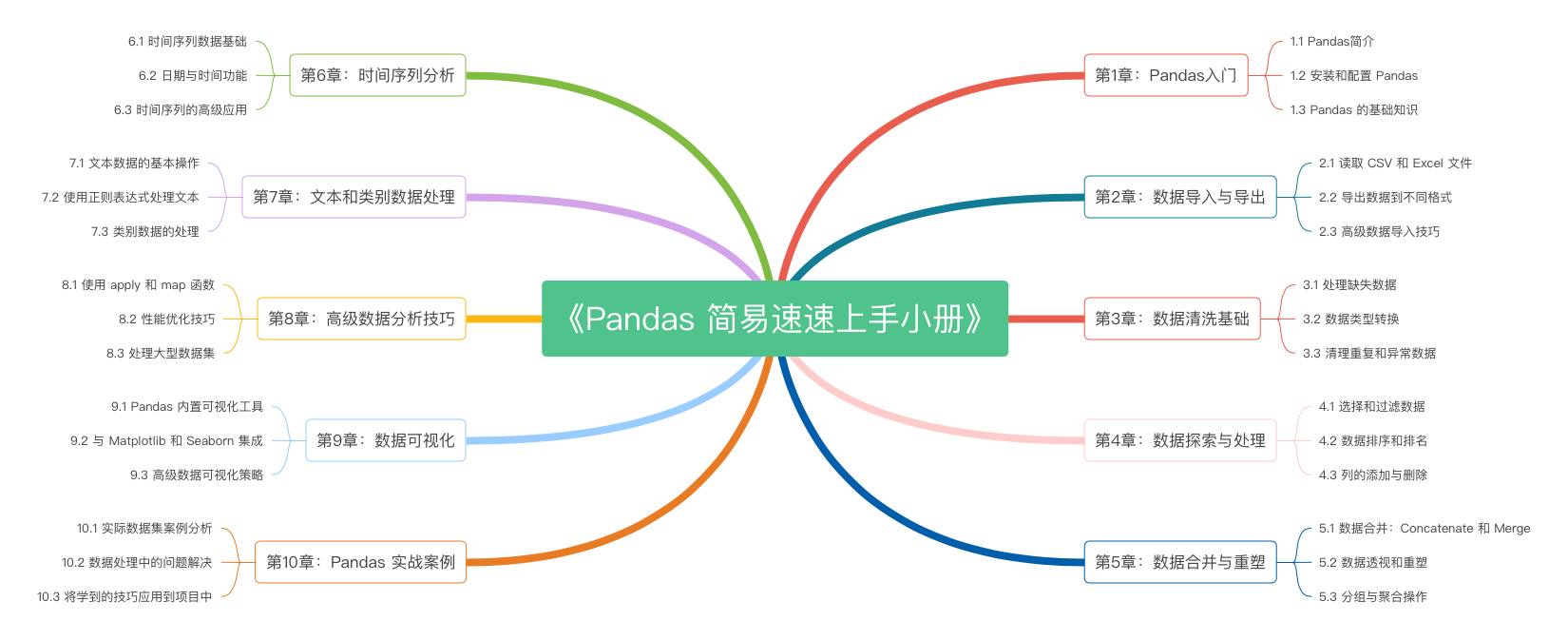
《Pandas 简易速速上手小册》第10章:Pandas 实战案例(2024 最新版)
Java 中文官方教程 2022 版(二十六)(2)
《Pandas 简易速速上手小册》第9章:Pandas 数据可视化(2024 最新版)
《Pandas 简易速速上手小册》第8章:Pandas 高级数据分析技巧(2024 最新版)
Java 中文官方教程 2022 版(二十六)(1)
《Pandas 简易速速上手小册》第7章:Pandas 文本和类别数据处理(2024 最新版)
《Pandas 简易速速上手小册》第6章:Pandas 时间序列分析(2024 最新版)
《Pandas 简易速速上手小册》第5章:Pandas 数据合并与重塑(2024 最新版)
《Pandas 简易速速上手小册》第4章:Pandas 数据探索与处理(2024 最新版)
使用URL的实例命名空间
Java 中文官方教程 2022 版(二十五)(4)
《Pandas 简易速速上手小册》第3章:Pandas 数据清洗基础(2024 最新版)
URL的应用命名空间
《Pandas 简易速速上手小册》第2章:Pandas 数据导入与导出(2024 最新版)
URL命名空间
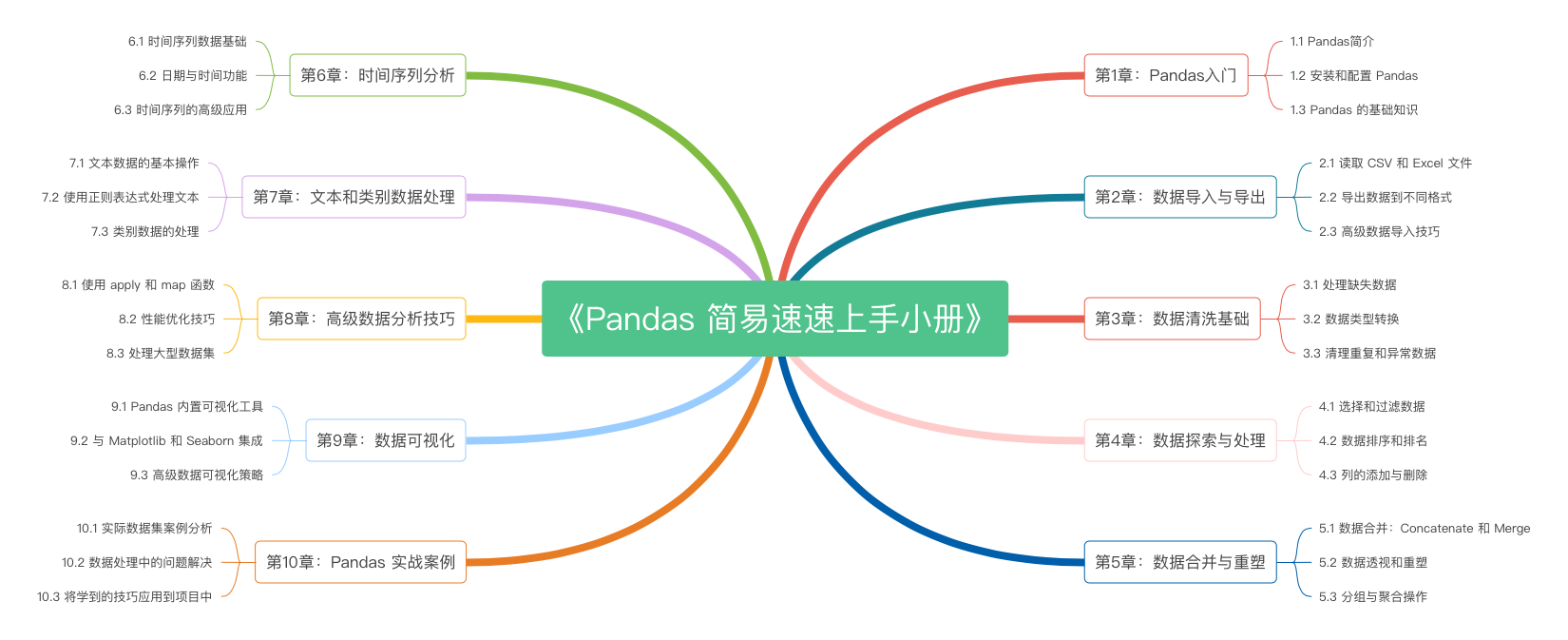
《Pandas 简易速速上手小册》第1章:Pandas入门(2024 最新版)
Java 中文官方教程 2022 版(二十五)(3)
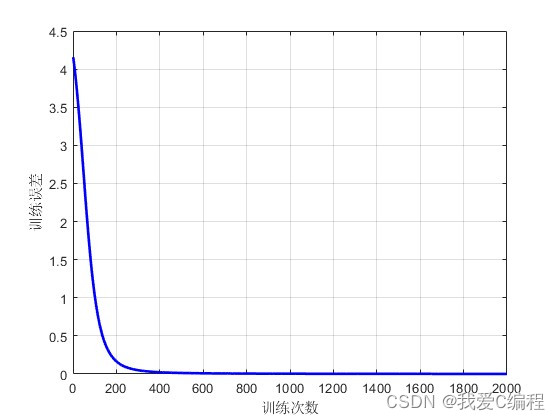
m基于深度学习的QPSK调制解调系统频偏估计和补偿算法matlab仿真
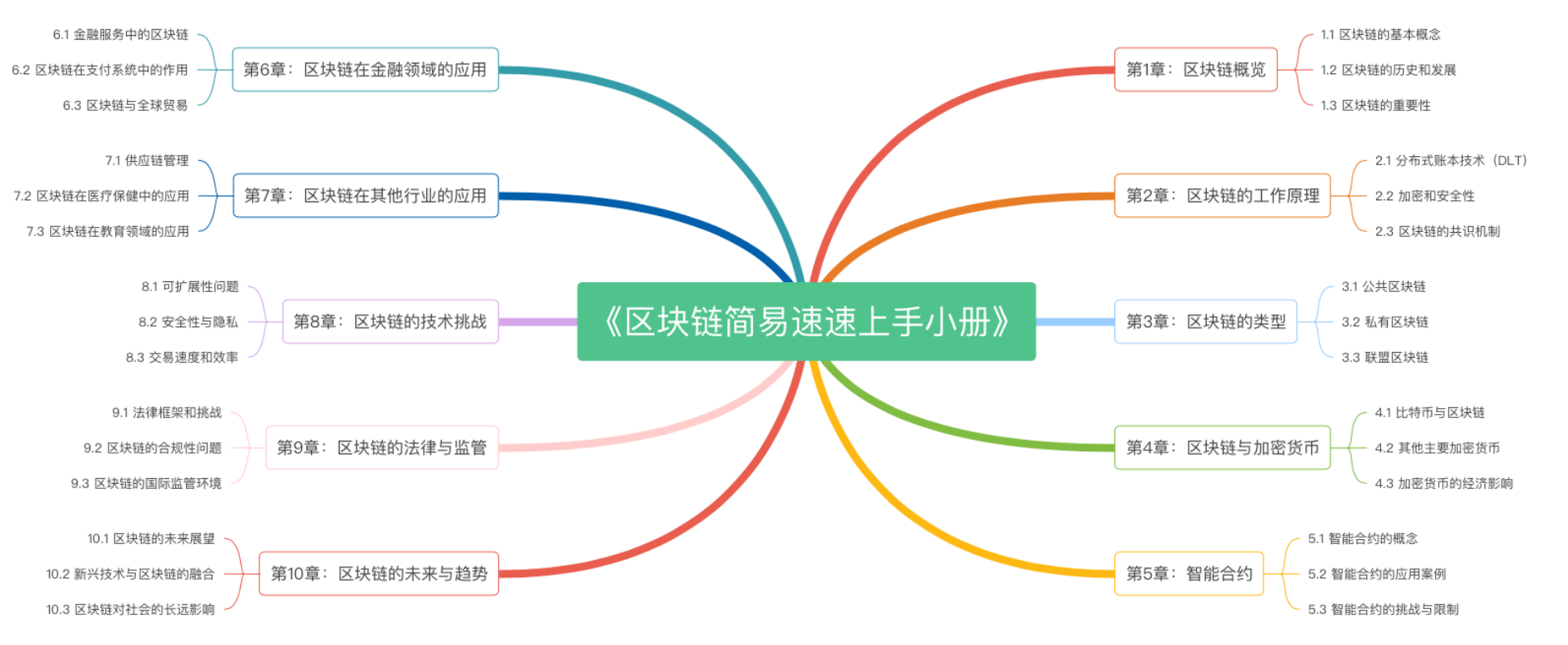
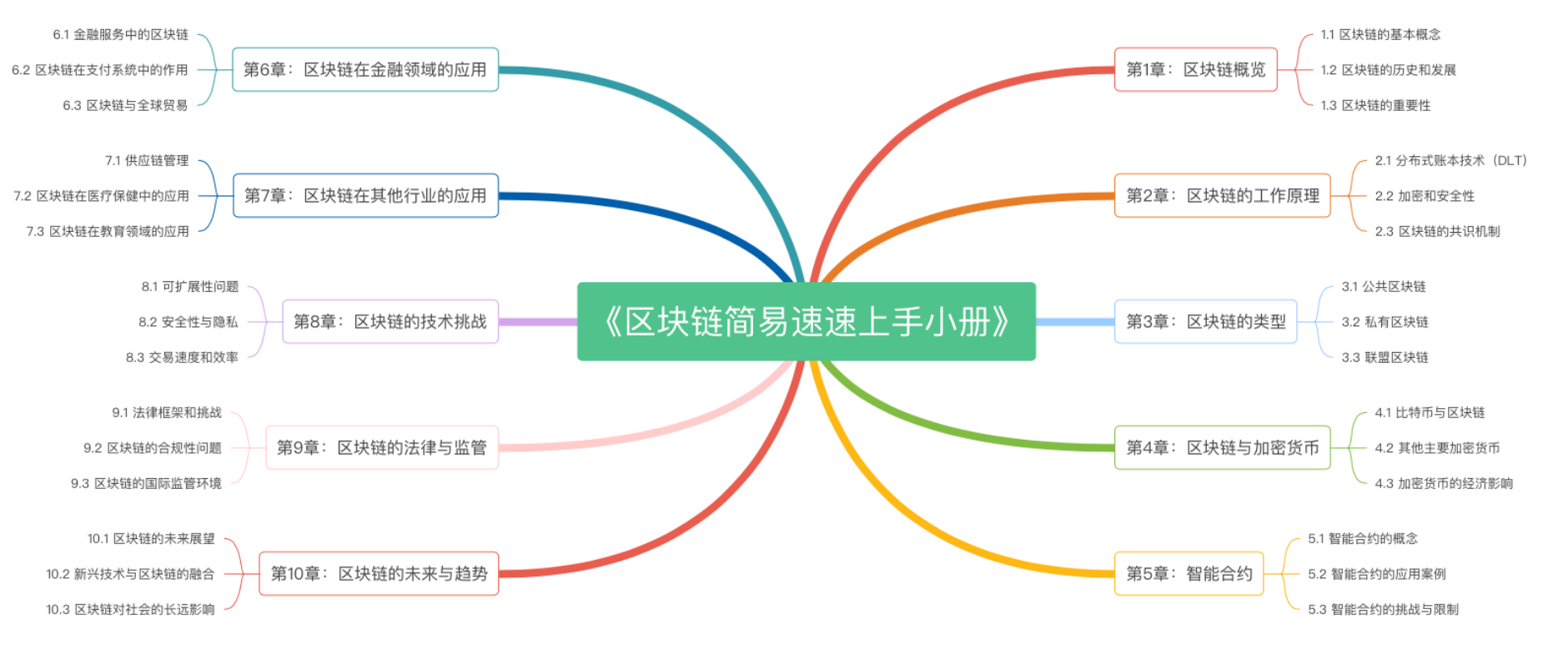
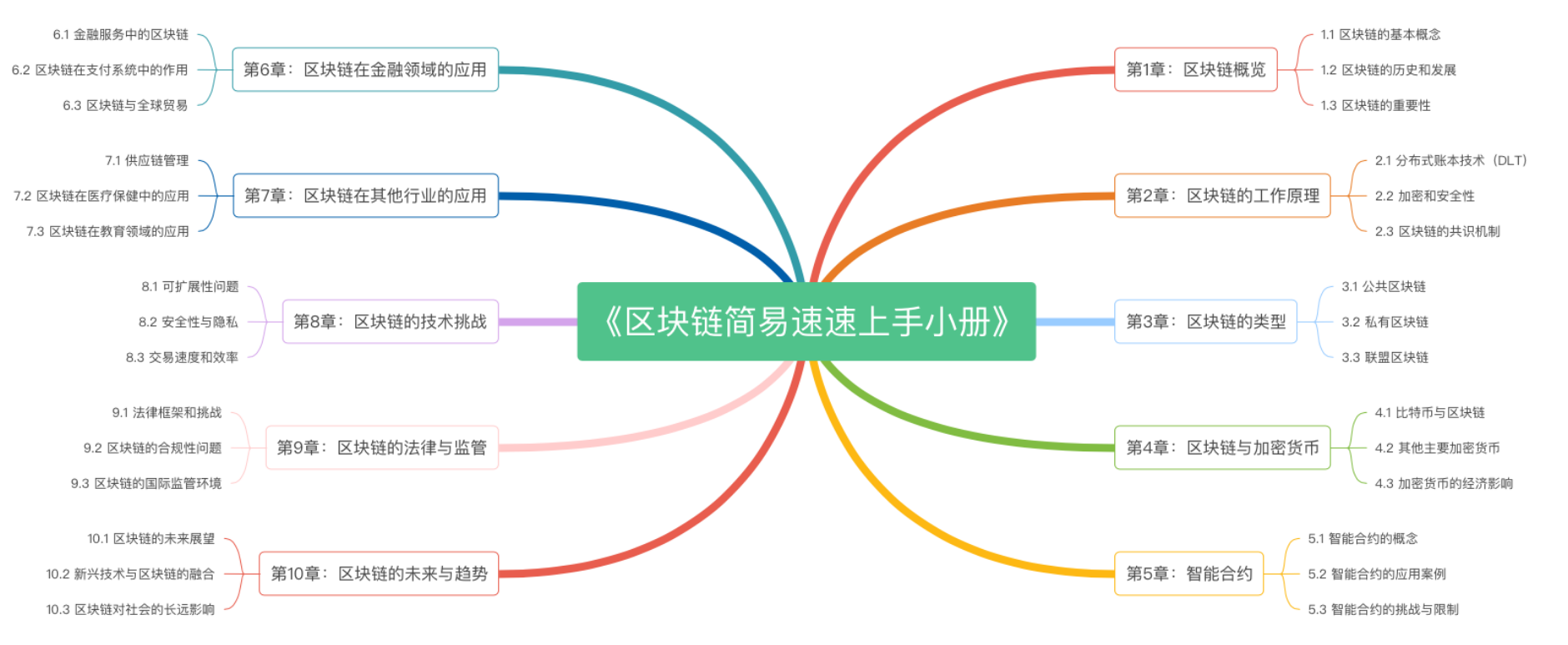
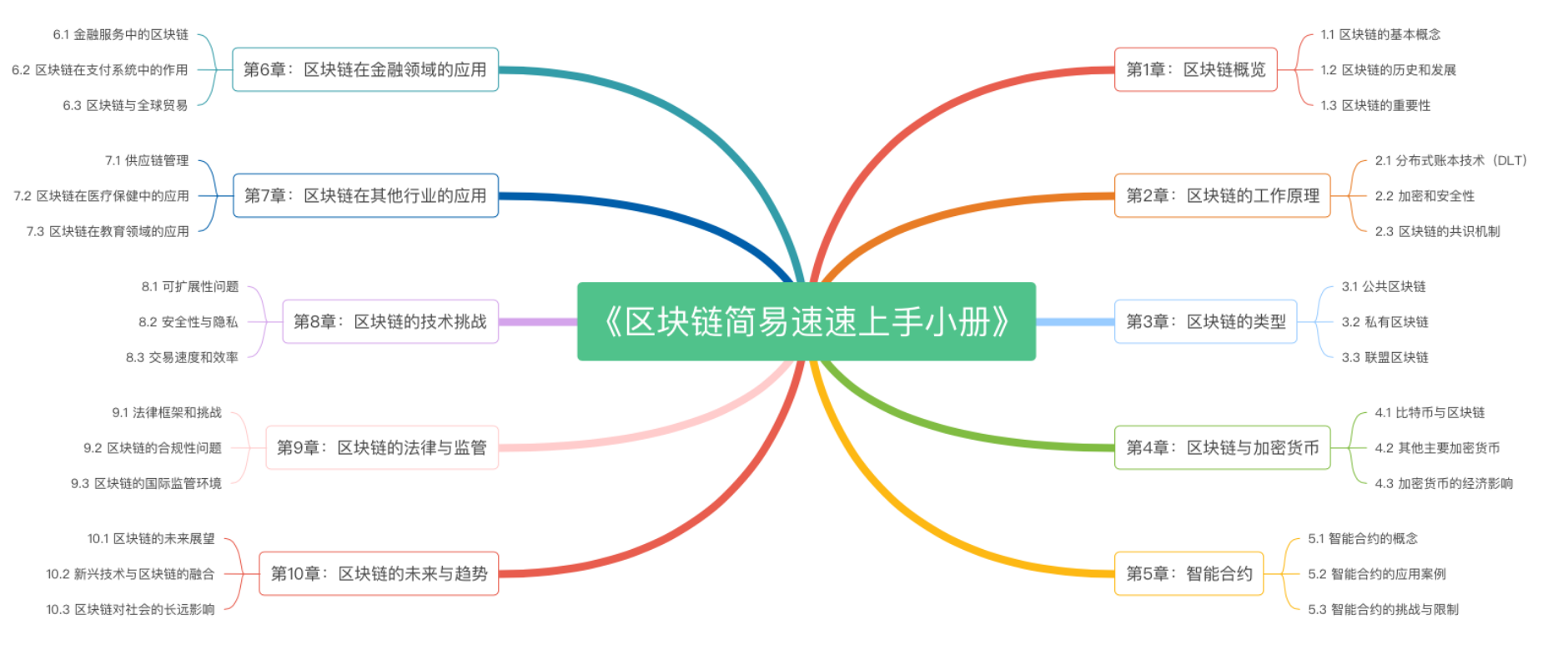
《区块链简易速速上手小册》第10章:区块链的未来与趋势(2024 最新版)
《区块链简易速速上手小册》第9章:区块链的法律与监管(2024 最新版)
Java 中文官方教程 2022 版(二十五)(2)
《区块链简易速速上手小册》第8章:区块链的技术挑战(2024 最新版)
《区块链简易速速上手小册》第7章:区块链在其他行业的应用(2024 最新版)