热门
【大模型】讨论 LLM 在更广泛的通用人工智能 (AGI) 领域中的作用
【大模型】在实际应用中大规模部署 LLM 会带来哪些挑战?
【大模型】小样本学习的概念及其在微调 LLM 中的应用
【大模型】LLM 如何处理域外或无意义的提示?
【大模型】在使用大语言模型的过程中,我们需要考虑到哪些道德问题?
【大模型】大语言模型存在的一些限制
【大模型】描述一些评估 LLM 性能的技术
【大模型】如何使用提示工程来改善 LLM 输出?
【大模型】大语言模型训练数据中的偏差概念及其可能的影响?
【大模型】在大语言模型的架构中,Transformer有何作用?
【AI 生成式】大语言模型(LLM)有哪些典型的应用场景?
【AI 生成式】LLM 通常如何训练?
Transformers从入门到精通:Transformers介绍
44缓存
【AIGC】LangChain Agent 最新教程详解及示例学习
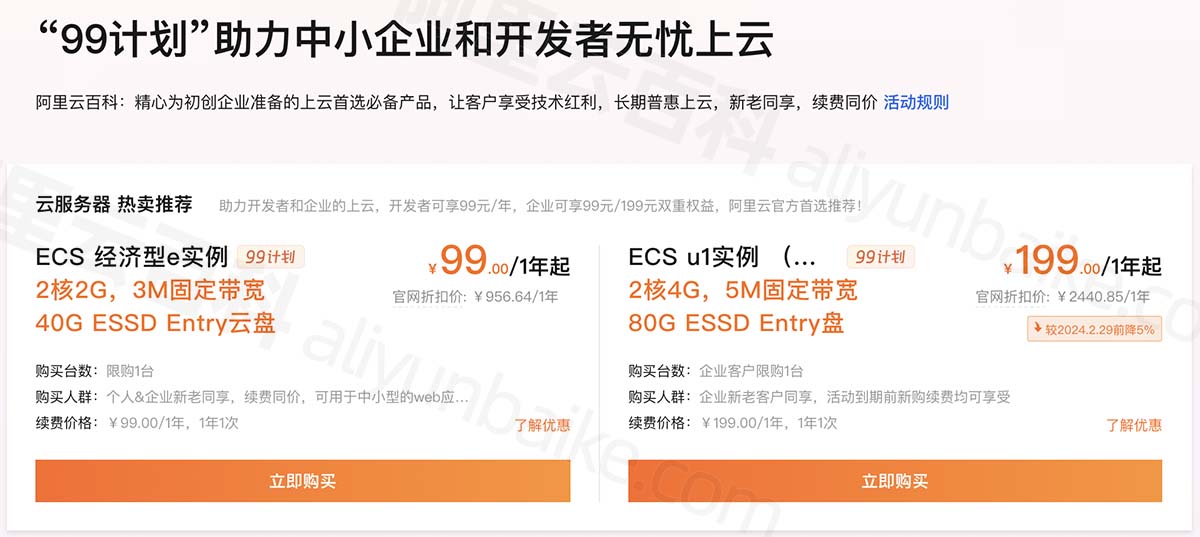
最新5月阿里云服务器租用价格表整理,连夜整理2024年降价后报价单
阿里云服务器配置选择指南,2024年全解析
Python模块化方式编程实践
Spring BeanUtils与Apache BeanUtils提供基本属性复制,适用于简单需求
Java为什么建议初始化HashMap的容量大小?
为什么禁止使用Executors创建线程池?
小程序开发框架
LRU(Least Recently Used)算法是一种常用的计算机缓存替换算法
要进入智能汽车公司开发,需要掌握以下基本知识
智能汽车自动驾驶技术开发需要以下知识储备
使用Python读取本地行情csv文件,做出web网页画出K线图实现案例
SpringCloudAlibaba:4.1云原生网关higress的搭建
【C 言专栏】C 语言中的多线程编程
【C 言专栏】用 C 语言开发游戏的实践
【C 言专栏】C 语言中的字符串处理技巧
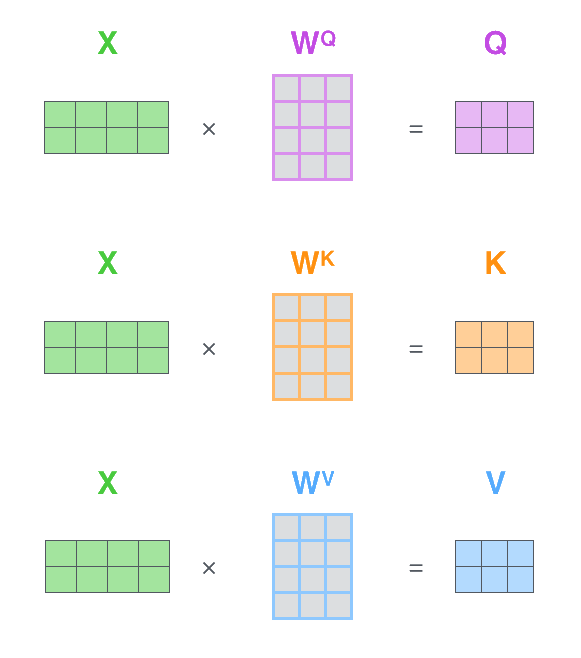
从头开始构建 Transformer: 注意力机制
SpringCloudAlibaba:3.1dubbo
SpringCloudAlibaba:3.2dubbo的高级特性
2024十款客户关系管理系统排行榜:效率巅峰与系统之选
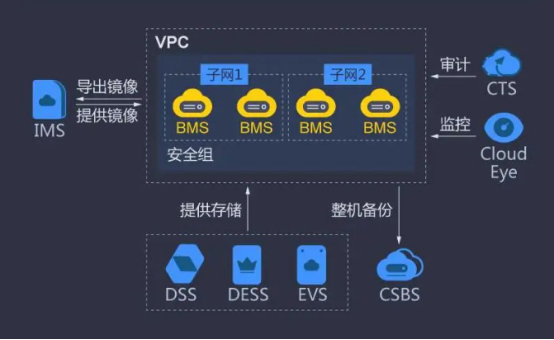
裸金属服务器,云用户的新体验
Java中ArrayList和顺序表
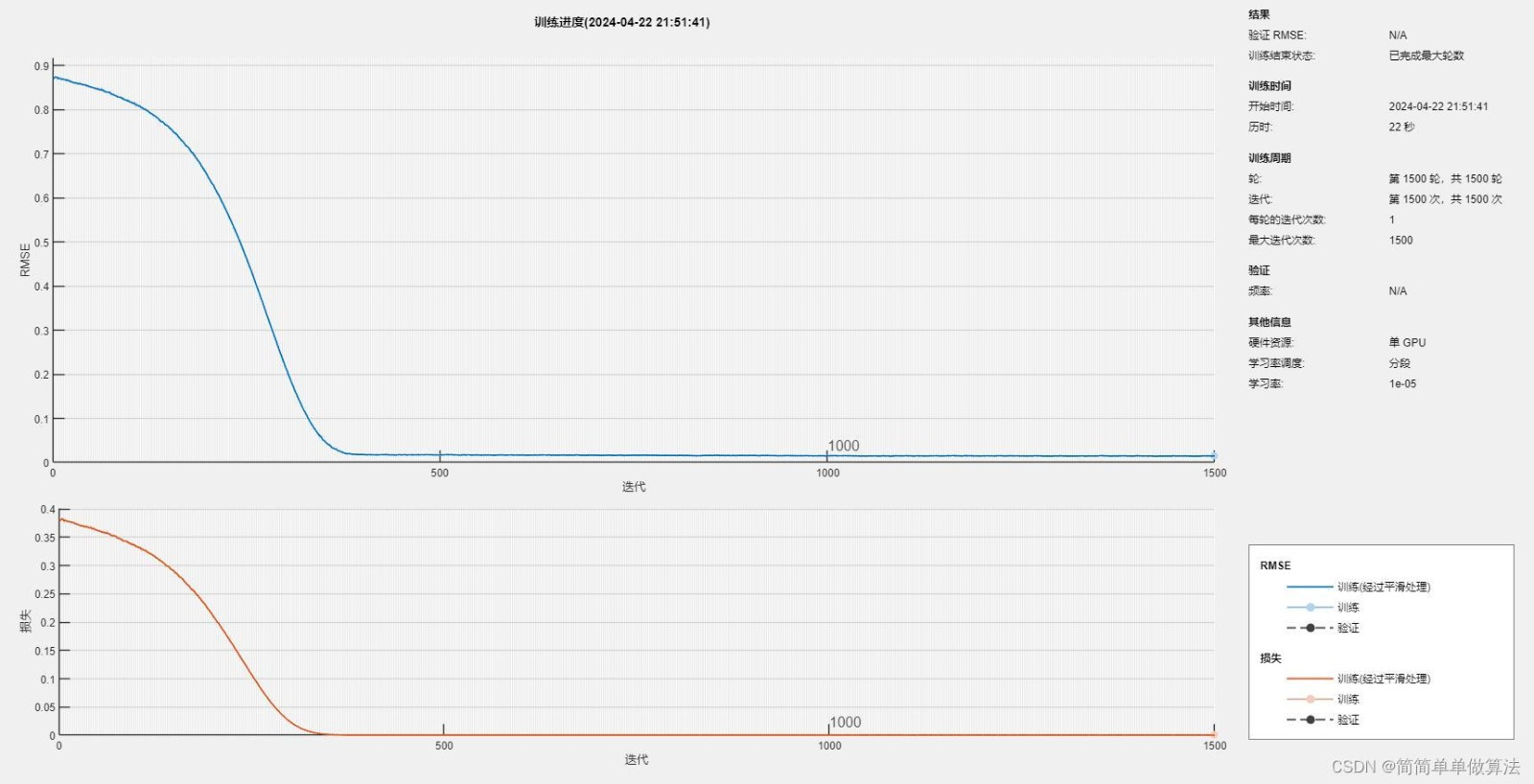
基于WOA优化的CNN-GRU-Attention的时间序列回归预测matlab仿真
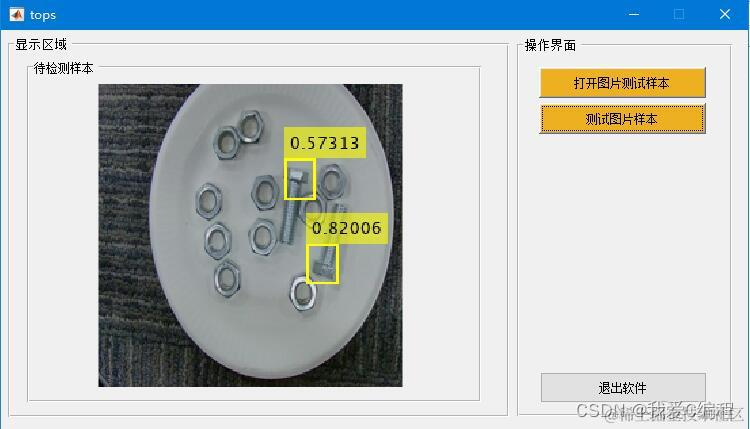
m基于Yolov2深度学习网络的螺丝检测系统matlab仿真,带GUI界面
自动导包设置
工业仪器通常需要稳定、可靠的电源供应。
AC/DC电源模块广泛应用于工业仪器领域,为工业仪器提供稳定可靠的电源供应
AC/DC电源模块在工业仪器中的应用案例
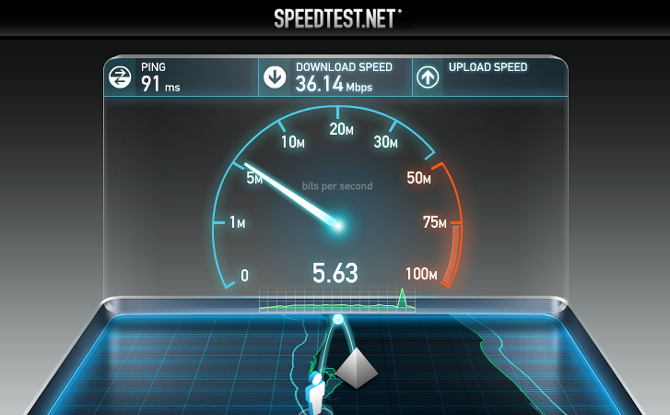
如何测试 Linux、Windows 和 macOS 中的本地网络速度?
如何使用s3fs将minio存储挂载到本地磁盘?
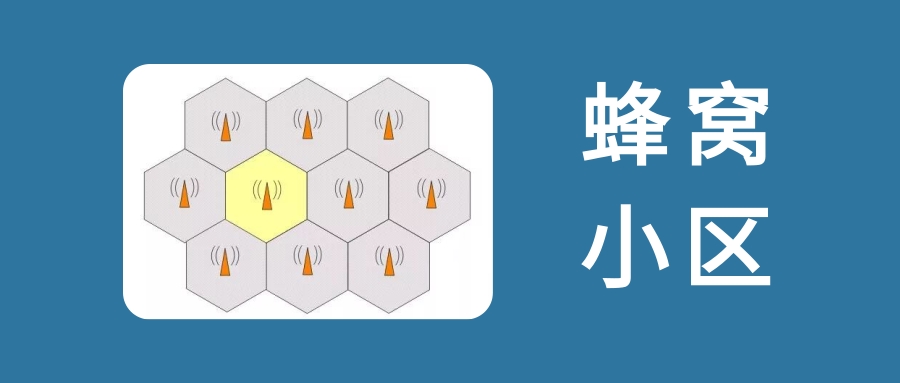
IT知识百科:什么是蜂窝小区?
g命令:Linux 中 ls 命令的优雅替代方案
云原生之使用Docker部署Nas-Cab个人NAS平台
mongoDB查看数据的插入日志
neo4j如何查看日志信息
高级架构师考试的过关率是多少