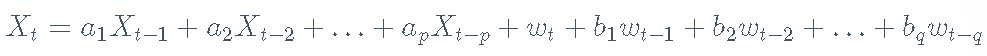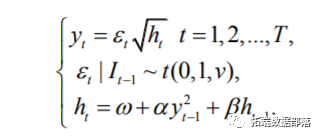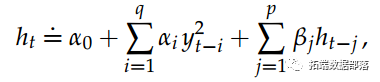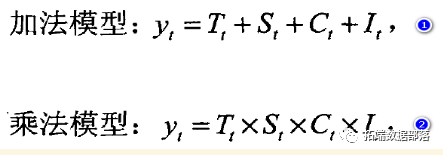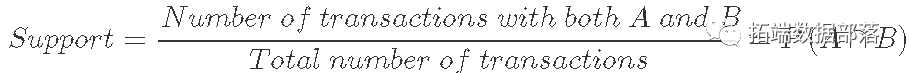热门
万字长文:一文彻底搞懂Elasticsearch中Geo数据类型查询、聚合、排序
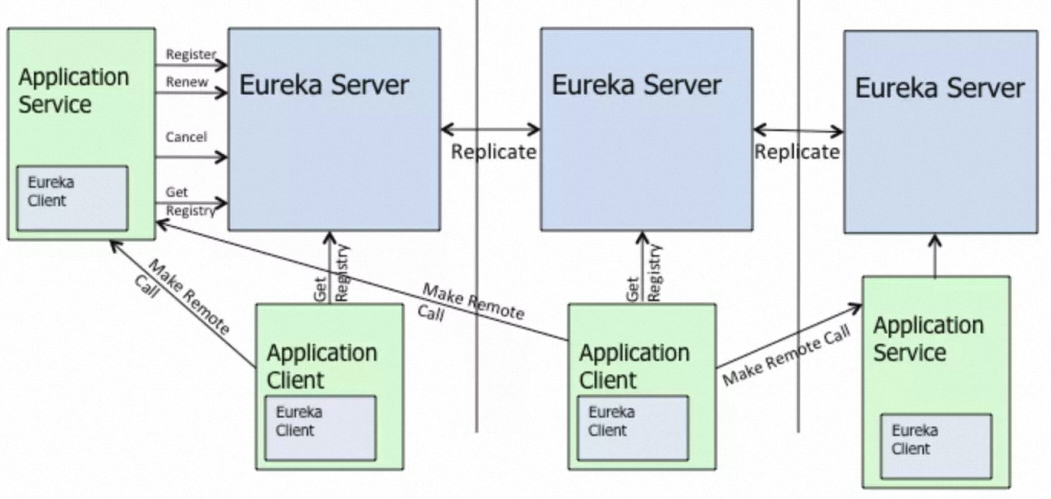
上一任留下的 Eureka,我该如何提升她的性能和稳定性(含数据比对)?
蚂蚁流场景状态演进和优化
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
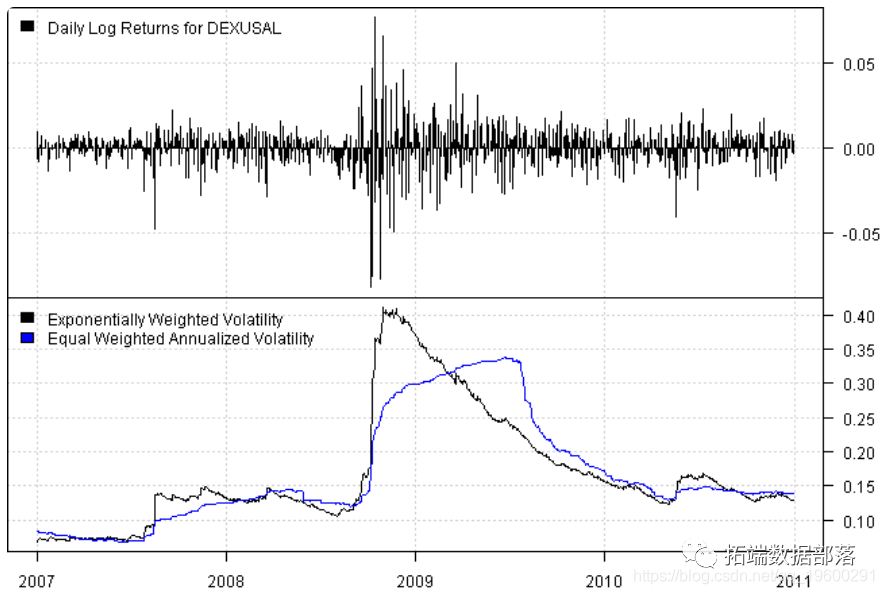
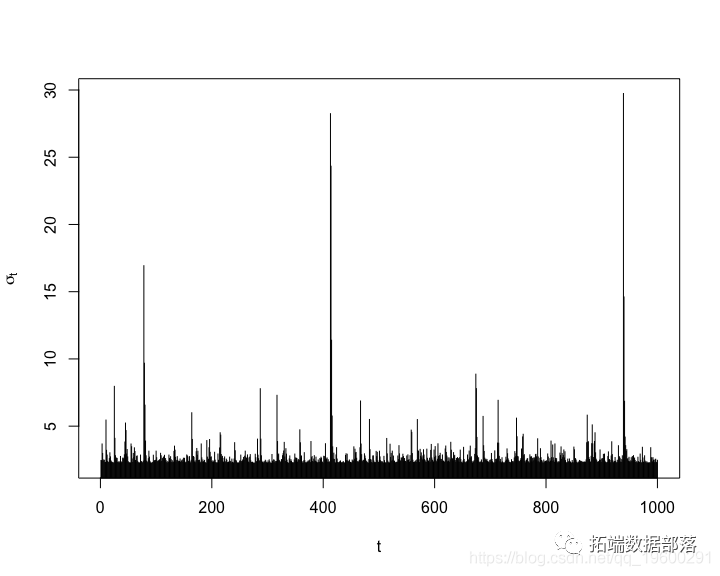
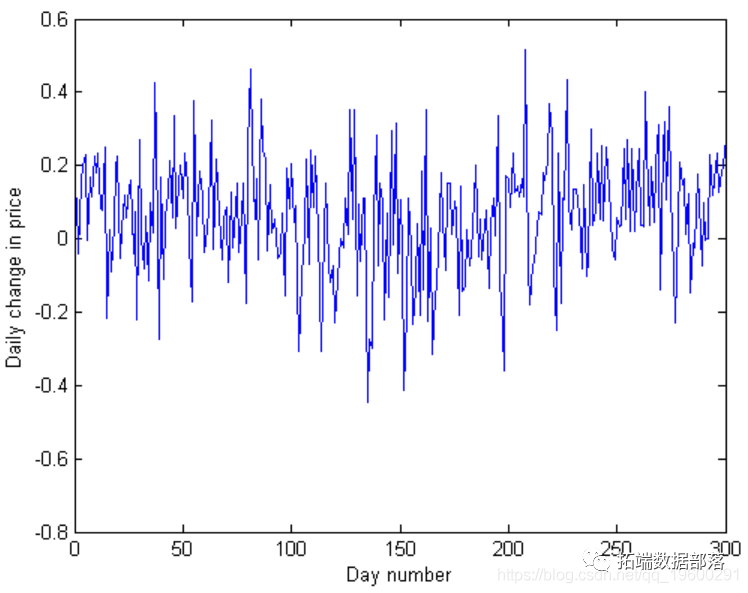
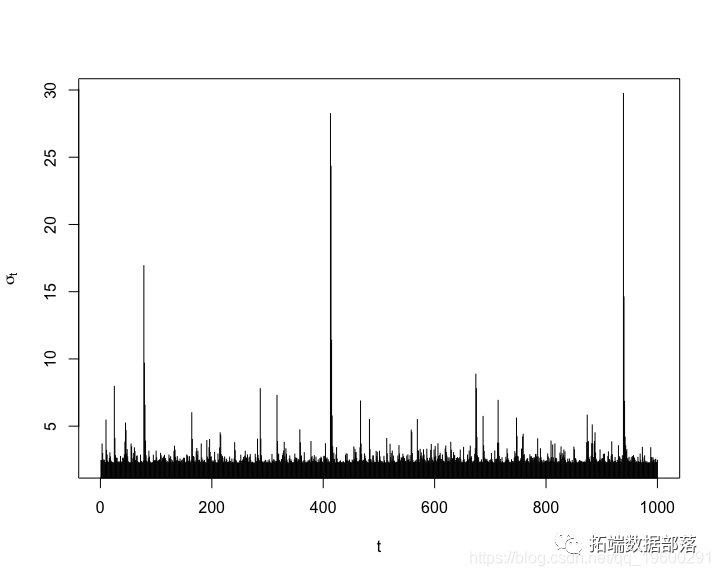
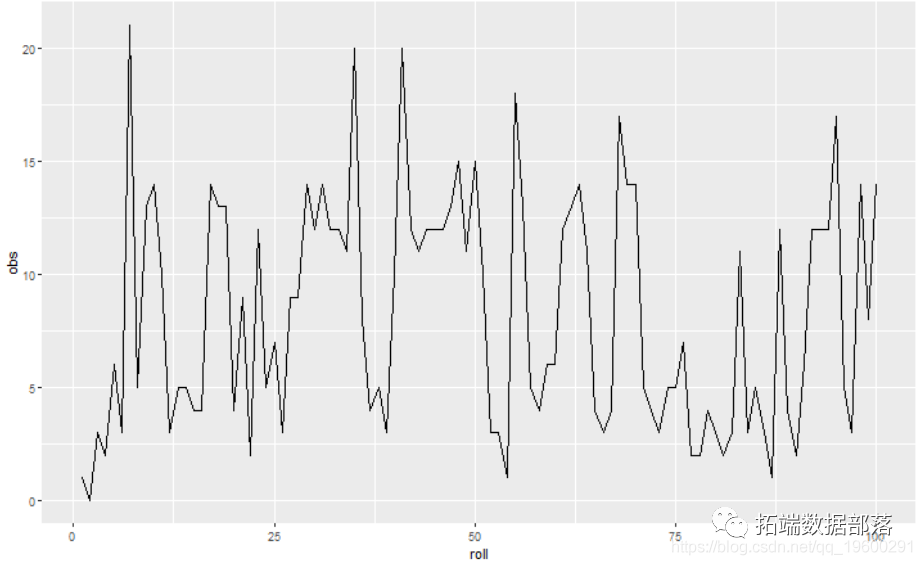
R语言中使用RCPP并行计算指数加权波动率
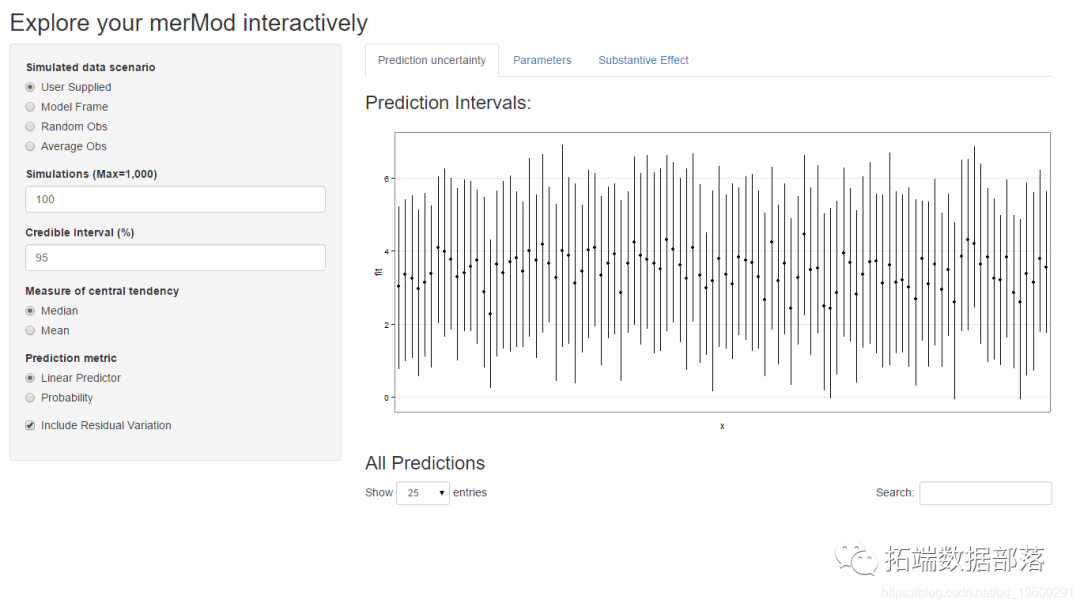
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
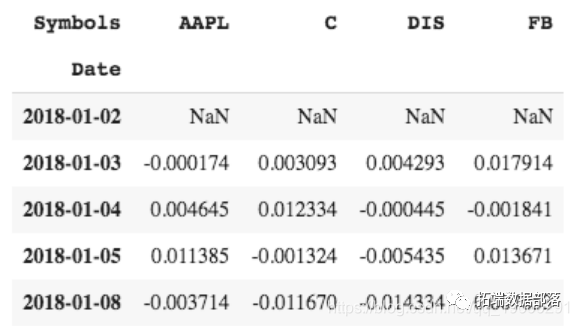
Python计算股票投资组合的风险价值(VaR)
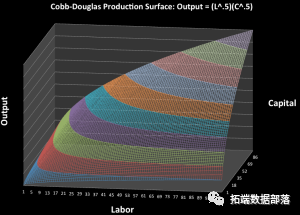
用excel来构建柯布-道格拉斯Cobb-Douglas生产函数的可视化
R语言使用马尔可夫链Markov Chain, MC来模拟抵押违约
R语言使用Bass模型进行手机市场产品周期预测
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言基于ARMA-GARCH-VaR模型拟合和预
R语言检验独立性:卡方检验(Chi-square test)
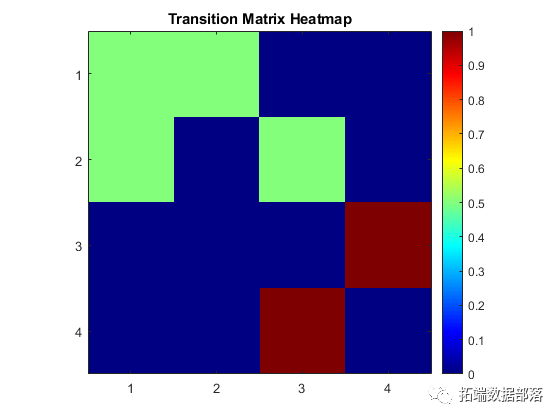
MATLAB中的马尔可夫区制转换(Markov regime switching)模型
R语言计量经济学与有时间序列模式的机器学习预测
R语言参数检验 :需要多少样本?如何选择样本数量
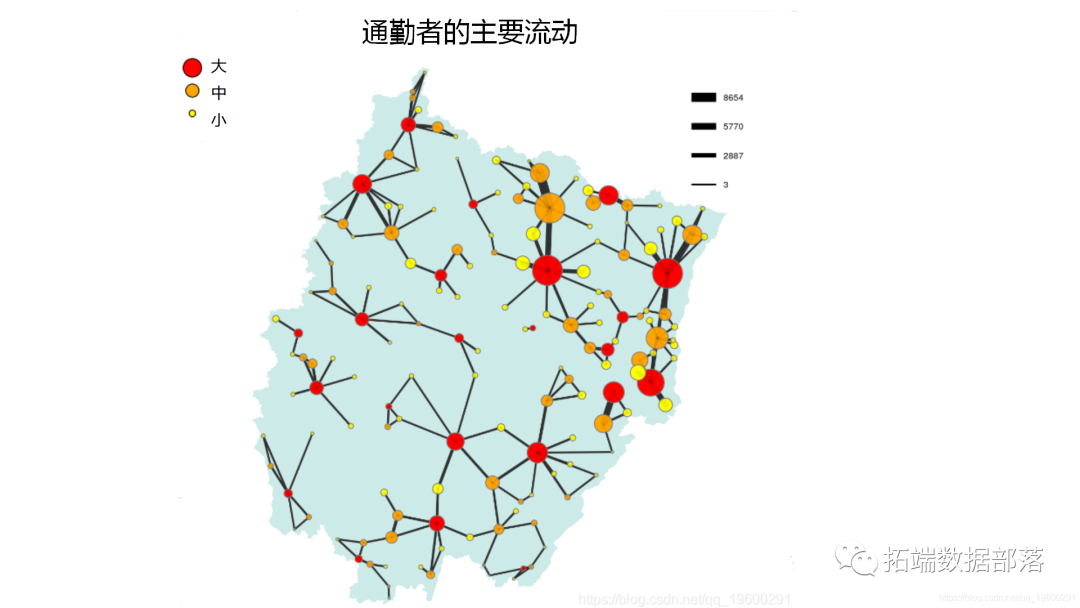
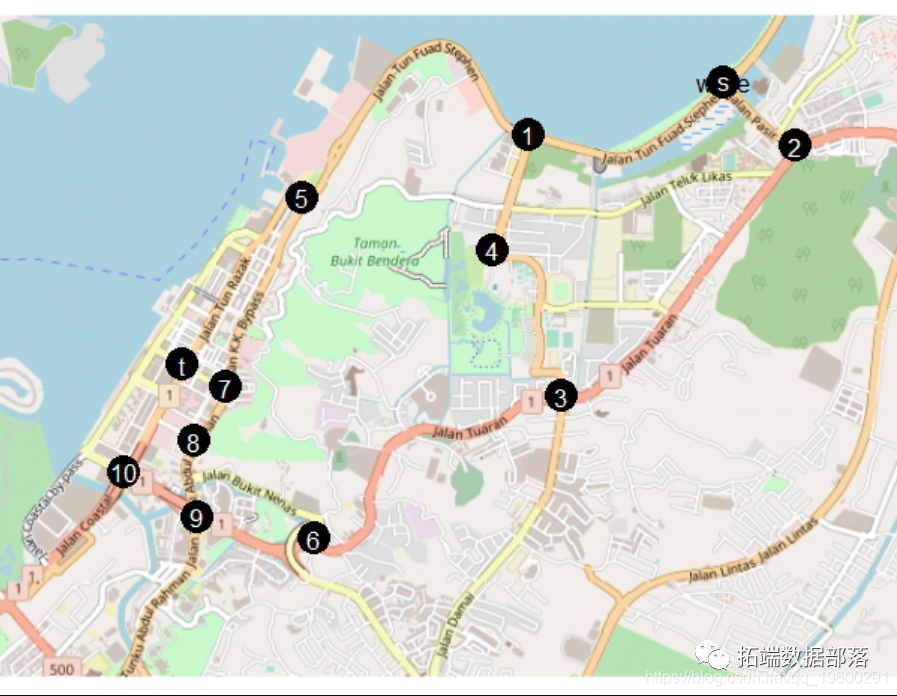
R语言网络和网络流的可视化实践:通勤者流动网络
R语言基于ARMA-GARCH-VaR模型拟合和预测实证研究分析案例
对象存储OSS产品常见问题之购买的资源包和预留空间区别只购买了预留空间会自动抵扣如何解决
R语言有RStan的多维验证性因子分析(CFA)
R语言最大流最小割定理和最短路径算法分析交通网络流量拥堵问题
对象存储OSS产品常见问题之go语言SDK client 和 bucket 并发安全如何解决
Flutter 插件站新升级: 加入优秀 GitHub 开源项目
R语言中的隐马尔可夫HMM模型实例
R语言时间序列:ARIMA / GARCH模型的交易策略在外汇市场预测应用
t-GARCH 模型的贝叶斯推断理论
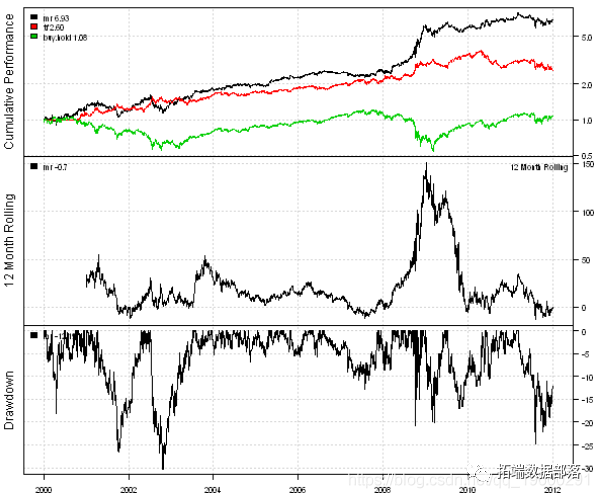
R语言基于Garch波动率预测的区制转移交易策略
对象存储OSS产品常见问题之有几十亿个txt文件,单个4kb,使用oss如何解决
matlab对国内生产总值(GDP)建立马尔可夫链模型(MC)并可视化
【后端面经】【数据库与MySQL】SQL优化:如何发现SQL中的问题?-02
R语言具有Student-t分布改进的GARCH(1,1)模型的贝叶斯估计
软件体系结构 - 网络拓扑结构
对象存储OSS产品常见问题之使用Spring Cloud Alibaba情况下文档添加水印如何解决
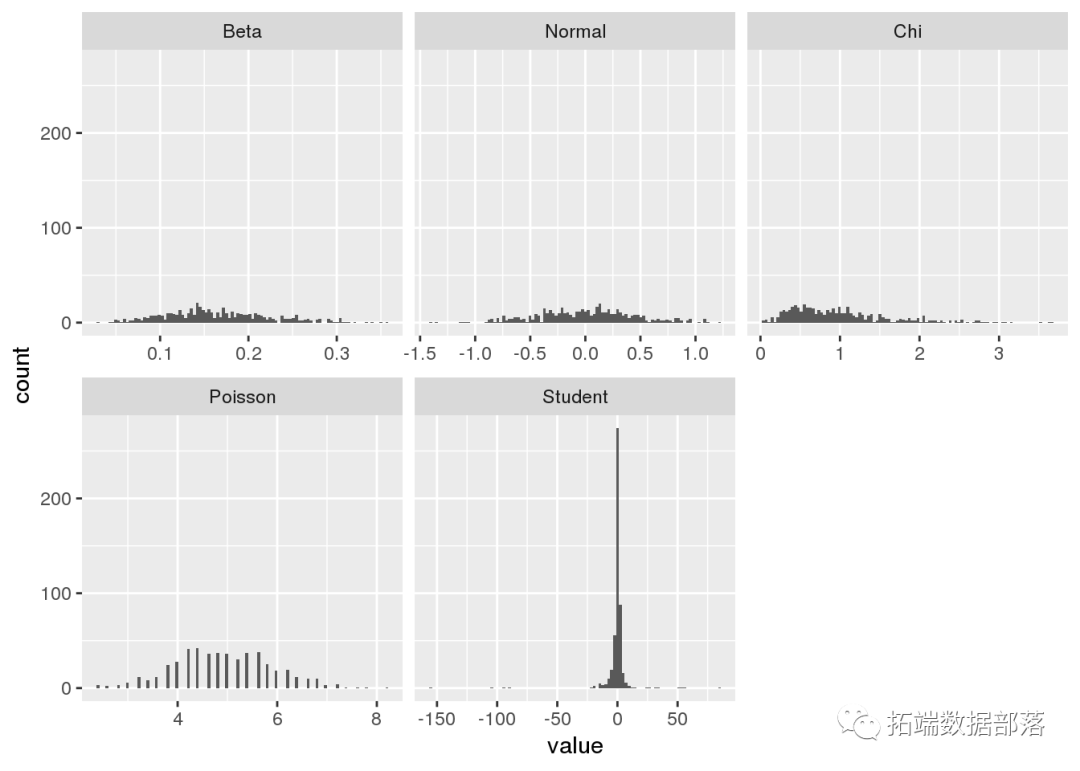
R语言中的模拟过程和离散化:泊松过程和维纳过程
R语言Lee-Carter模型对年死亡率建模预测预期寿命
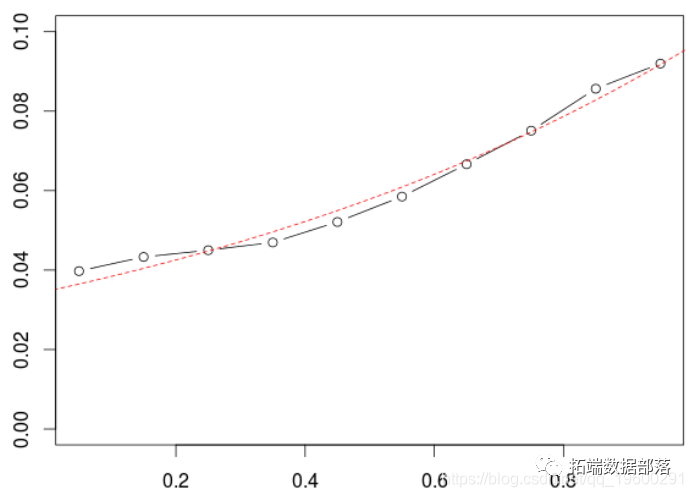
R语言POT超阈值模型和极值理论EVT分析
探索Sun-Panel:一站式服务器、NAS导航面板、Homepage、浏览器首页
R语言使用灰色关联分析(Grey Relation Analysis,GRA)中国经济社会发展指标
如何从xml文件创建R语言数据框dataframe
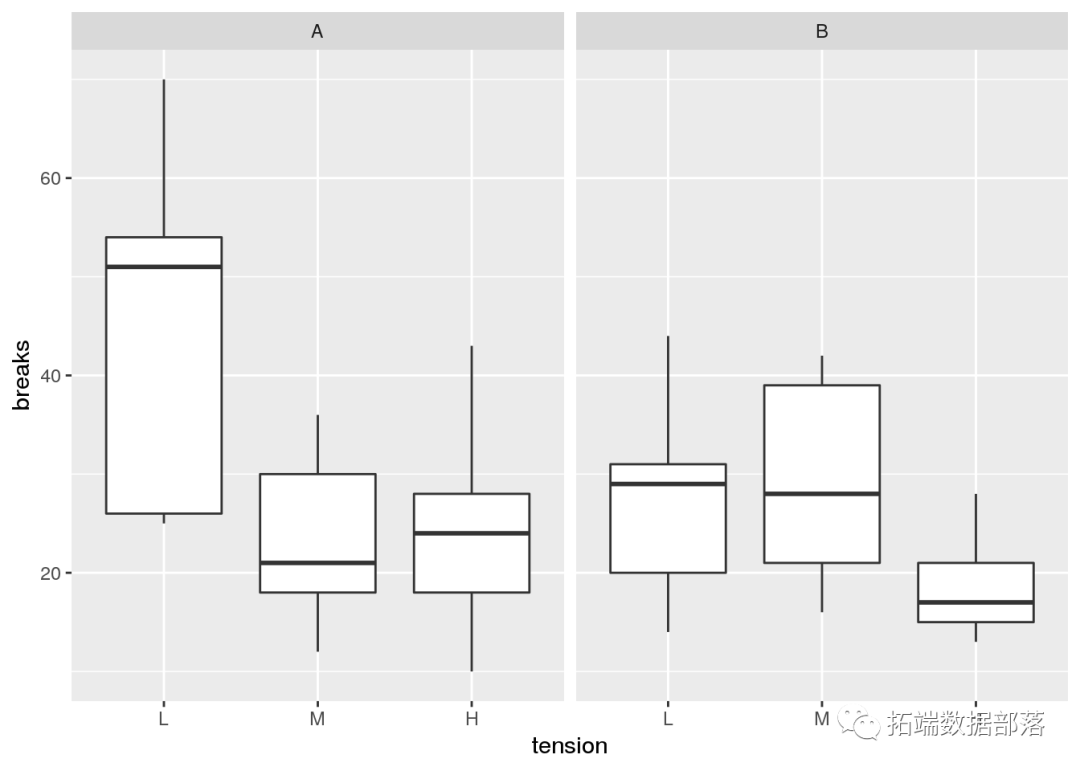
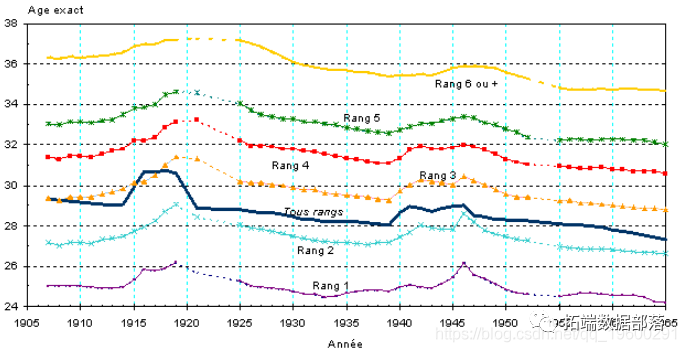
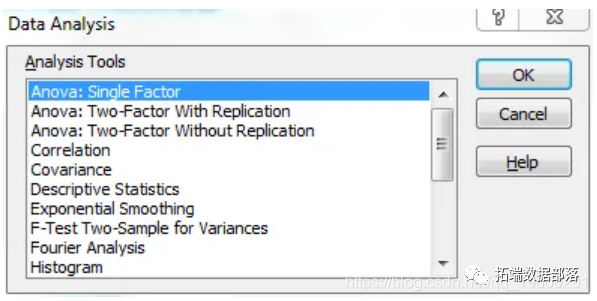
Excel 实例:单因素方差分析ANOVA统计分析
Mac系统R语言升级后无法加载包报错 package or namespace load failed in dyn.load
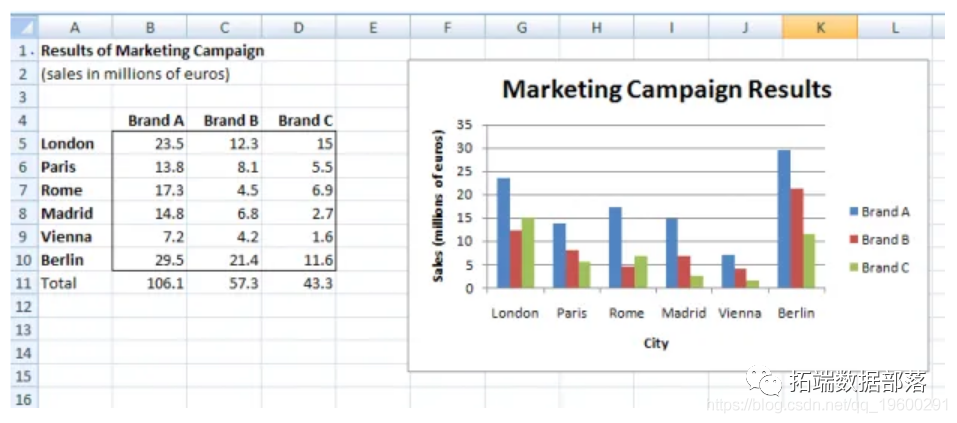
Excel实例:Excel图表可视化:条形图、折线图、散点图和步骤图
用R语言中的神经网络预测时间序列:多层感知器和极限学习机
基于yolov2深度学习网络的螺丝螺母识别算法matlab仿真
对象存储OSS产品常见问题之python sdk中的append_object方法支持追加上传xls文件如何解决
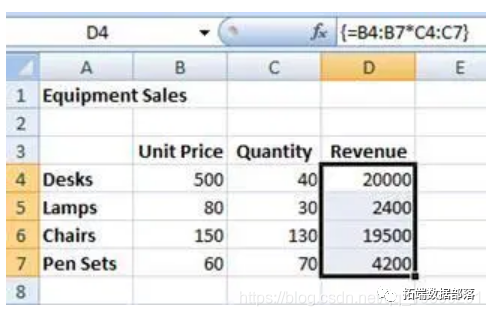
Excel实例:数组公式和函数
状态空间模型:卡尔曼滤波器KFAS建模时间序列
R语言关联挖掘实例(购物篮分析)
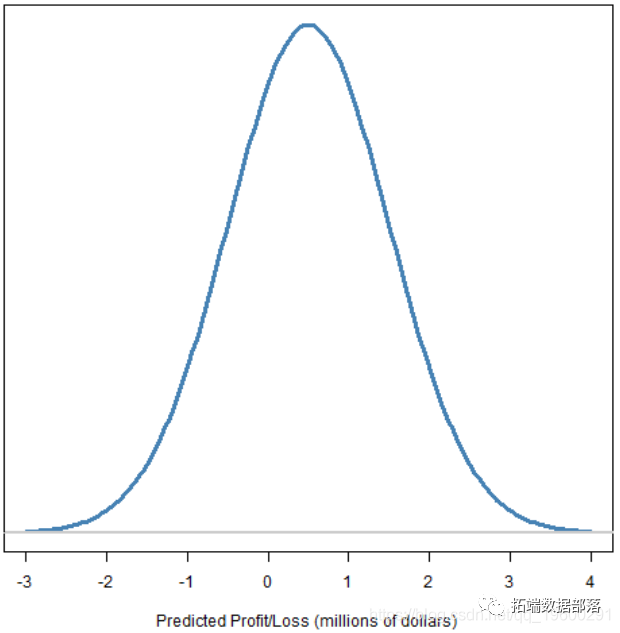
R语言风险价值VaR(Value at Risk)和损失期望值ES(Expected shortfall)的估计