闲鱼技术-渐漓
背景
在闲鱼的很多业务场景中有大量需要利用算法进行分类的需求,例如图片分类、组件识别、商品分层、纠纷类别预测等。这些场景往往需要模型识别出的结果具备可解释性,也就是识别不能只得到其类别,最好能在识别过程中同时解释类别的层级和来源。如何进行有解释的图片分类成为了项目研发中的一个需求,基于此我对NBDT算法进行了调研。
NBDT 是UC伯克利和波斯顿大学最新(2020年4月)发的一篇paper中的模型。NBDT全称“Neural-Backed Decision Trees”,翻译为“神经支持决策树”,特别强调此处“B”不代表“Boosting”,以免熟悉GBDT的同学可能会误以为NBDT又是一种新型的梯度提升树模型。NBDT只是一颗决策树,而不是多棵树。
介绍
NBDT的特点在于它在决策树中(准确说是决策树前)融入了神经网络NN,这里NN通常是CNN即卷积神经网络。个人理解,NBDT的结构可以大致认为是“前面的CNN + 后面的DT”。DT=决策树。
NBDT目前的使用场景是在图像分类领域。它的优势不在于准确率有多高,事实上在作者的实验中,它的准确率是略低于“前面的CNN”的。它的真正优势是能够很好的平衡模型准确率和模型解释性。具体来讲,它可以在略微牺牲CNN的准确率的前提下,取得比任何树模型都高的多的(分类)准确率,同时因为它融入了决策树,还可以显式的、逐级的给出模型推断的依据,也就是说,NBDT不但可以把一张狗的图片识别为“狗”,还可以告诉你它是如何一步一步识别的:比如,先把该图片以99.49%的概率识别为“动物”,再以99.63%的概率识别成“脊椎动物(Chordate)”,然后以99.4%的概率识别成脊椎动物下的“食肉动物(Carnivore)”,最后以99.88%的概率判断成食肉动物下的“狗”。这种推断方式无疑增强了模型的解释力。

原理细节
NBDT采用了“预训练+finetune”的框架。整个流程大致分为以下三步:
① 预训练一个CNN模型,并拿CNN最后一层的权重作为“每种类别”的隐向量。
比如先拿cifar10(一个图片分类数据集,有“猫”、“狗”之类的10种类别)训练一个resnet18的CNN。这类CNN的最后一层通常是全连接层(Fully Connected layer, FC),设倒数第二层输出的向量维度为d,则该全连接层W的维度为W,那么W的每一个列向量正好对应了每一个类别,可以将其视作每一种类别的隐向量。这种做法有点类似于Word2Vec。
② 利用类别的隐向量做层次聚类(Hierarchical Clustering),并利用WordNet形成层次树结构。
论文中将该树结构称之为“诱导层级”(Induced Hierarchy)。具体地,首先对类别隐向量做层次聚类,源码中是直接调用sklearn模块的AgglomerativeClustering类实现。聚类的分层结构有了之后,带来了两个问题:(1)两个子节点可以被聚类算法聚到一起,子节点都表示一类实体,但它们的父节点并没有一个实体的描述。(2)假设两个子节点被聚到了一起,子节点都有隐向量,它们的父节点的隐向量该怎么表示?
针对问题(1),作者使用了WordNet,一种包含名词之间上下位关系的词网络,python里面可以直接在nltk模块中导入wordnet模块调用。由于叶节点是存在实体描述的,比方说cifar10的10个类别,那么通过WordNet,可以找到两个叶节点“最邻近的共同祖先”,e.g. “猫”和“狗”在WordNet中可能最近的归属是都位于“哺乳动物”下,那么“哺乳动物”就被作为“猫”和“狗”的父节点。因此,可以按照层次聚类的结果,自底向上依次为父节点“命名”,直到只有一个根节点,这就形成了所谓的“诱导层级”,即下图中的“Step 1”。这个诱导层级也就是上面狗狗图片中的决策树。
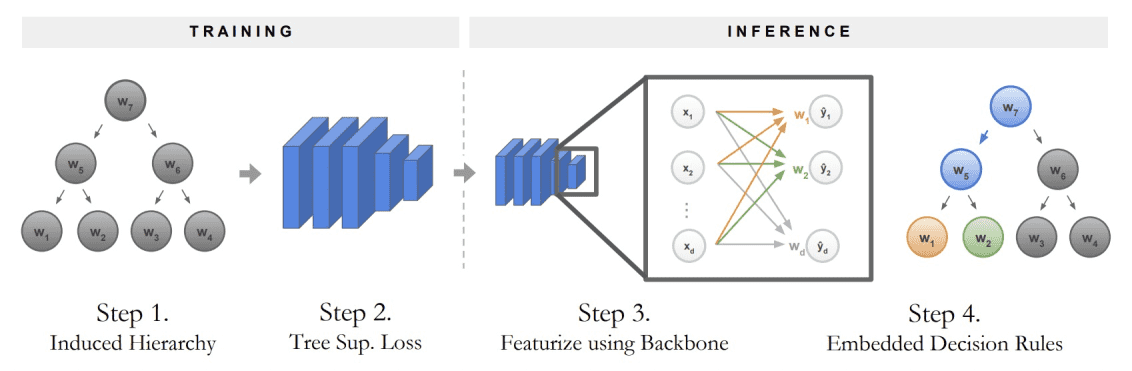
针对问题(2),作者使用了子节点隐向量的均值,来代表父节点的隐向量。如下图中的“Step C”描述。

③ 在总损失中加入诱导层级的分类损失,finetune模型。
在诱导层级(树结构,下称DT)有了之后,完整的模型不再是CNN,而是CNN+DT。为了迫使模型对新样本的预测能够遵循树结构从根节点一路推断至叶节点,就需要在总损失中加入树结构的分类损失,并对模型做finetune。
这里首先要理解完整模型预测所采用的方式,我认为作者在这里的思路是非常之精髓的。一个新的样本(一张图片)进来,首先要经过前面的CNN,在最后一层的全连接层W之前,CNN给该图片输出的是一个d维向量x。将x与W做矩阵乘法(实质上是与各列向量做内积),即得到该样本在各个类别的logits分布,如果再softmax则得到了概率分布。由于W的各列向量代表着DT叶节点的隐向量,那么完全可以用该DT来替换W,不再直接把x与W做矩阵乘法,而是从DT的根节点开始遍历,让x依次与DT各节点的子节点隐向量计算内积。这里遍历DT各节点有两种模式:“Hard”和“Soft”。以DT是二叉树为例,若是Hard模式,那么每次x会与左右两边的子节点分别算内积,哪边大就把x归为哪一边,一直计算到叶节点为止,最后x落到的叶节点,即为x所属的最终类别。若是Soft模式,则x会自顶向下遍历全部中间节点并计算内积,然后叶节点的最终概率是到达叶节点的路径上各中间节点的概率之乘积,最后通过比较各叶节点上的最终概率值的大小,即可确定x所属类别。
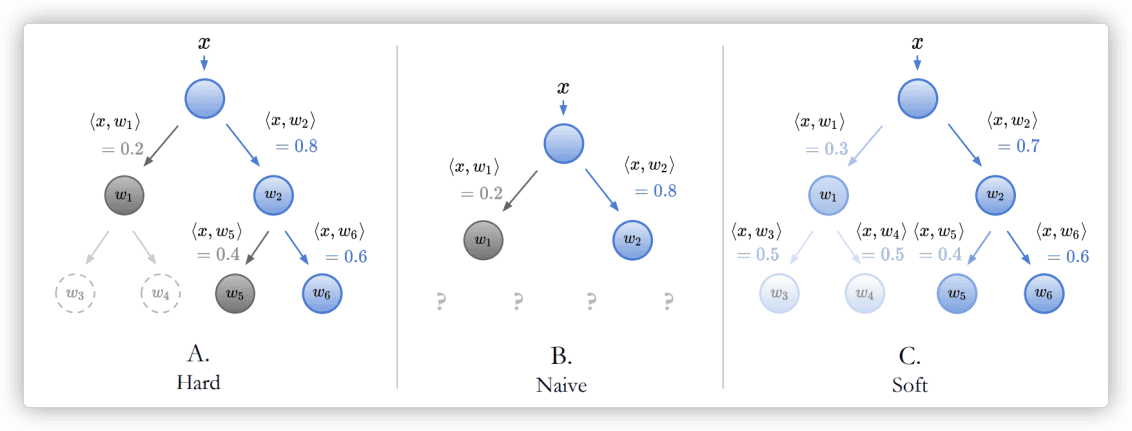
在理解了完整模型预测的细节之后,就可以来解释“诱导层级(树结构)的分类损失”。相对应的,损失函数同样有“Hard”和“Soft”两种模式,如下图所示。若是Hard模式的损失,那么Loss只会累加样本所属叶节点在DT中真实路径上的每个节点的分类损失(以一定权重),非真实路径(下图A虚线节点w3/w4)则不会计入,此处每个节点的分类损失使用交叉熵计算。若是Soft模式的损失,则是直接计算叶节点上的最终概率分布与真实onehot分布的交叉熵作为Loss。简言之,Hard模式损失函数计算的是“路径交叉熵”,Soft模式则计算的是“叶节点交叉熵”。在pytorch中的交叉熵计算方式为:
$$\text{CrossEntropy}(x, class) = -\log\left(\frac{\exp(x[class])}{\sum_j \exp(x[j])}\right) = -x[class] + \log\left(\sum_j \exp(x[j])\right)$$ 最终模型的总损失还会考虑原始CNN的分类损失Lossoriginal,因此最后交由finetune阶段进行优化的总损失为: $$Loss_{total} = Loss_{original}+Loss_{hard\ or\ soft} $$ 根据我对源码的阅读,Loss进行BP反向传播时优化的依然是CNN的网络权重,直观上理解:就是迫使前面CNN的输出能够符合后面DT的预期,尽可能使得样本按照DT的推断路径输出的预测类别符合其真实类别。 

#### ② 前向计算节点概率 前面提到新样本进来后会先经过CNN,在FC之前会输出d维向量x,然后x与DT的各个节点的隐向量做内积,而各节点的隐向量又等于其子节点隐向量的均值。**get_node_logits**方法在这里做了一个优化:**考虑到向量均值的内积等于向量内积的均值**(如下图公式),因此不必显示的去求隐向量再做内积,而是对某个节点,直接把其子节点的logits求均值作为它本身的logits。具体代码如下:


#### ③ 总损失函数 前面提到,总损失=原始CNN损失+树结构损失。具体地,以Hard模式为例,如下代码解释了如何计算决策路径上的树结构损失,并合并到总损失当中。

## 论文实验 在多个数据集上,作者拿原始CNN(WiderResnet28×10)和多个“可解释”的神经网络模型做了对比,从下表可以看到,NBDT精度仅仅比原始CNN略低,但已经远远超过其它模型,说明NBDT已达到SOTA。**而在NBDT中,Soft模式的分数要高于Hard模式**,这个好理解,因为Soft考虑的是全局最优,Hard考虑的则是连续多次局部最优。
 图6 - 实验结果 (引用自原Paper) ## 使用 > 安装和使用详见官方github,此处仅对常用方式做总结 #### ① 命令行预测 直接调用 **nbdt** 命令,后面跟图片路径(url或本地路径)。第一次执行会下载WordNet和官方预训练模型。由于该预训练模型是针对cifar10数据集的,因此尽量输入一张属于这十类之一的图片。从输出中可以看到,预测行为是“逐级进行”的。
图6 - 实验结果 (引用自原Paper) ## 使用 > 安装和使用详见官方github,此处仅对常用方式做总结 #### ① 命令行预测 直接调用 **nbdt** 命令,后面跟图片路径(url或本地路径)。第一次执行会下载WordNet和官方预训练模型。由于该预训练模型是针对cifar10数据集的,因此尽量输入一张属于这十类之一的图片。从输出中可以看到,预测行为是“逐级进行”的。
 #### ② 在python中预测
#### ② 在python中预测
 #### ③ 完整使用方式
#### ③ 完整使用方式
 ## 后续计划 调研NBDT的目的是寻找一种让分类问题变得可解释的方法,这种可解释性可以应用在任何分类过程中需要给出决策路径的场景。尽管作者在论文中介绍的应用场景是图片分类,但只要把前面的CNN替换成其他网络,那么实际上任何分类问题都可以利用NBDT做出解释。比如在闲鱼优质商品分层项目中,我们可以基于业务知识构造商品间的诱导层级(例如第一层分为专业卖家/个人卖家、第二层分为动销率高/中/低...最后一层分为商品不同的优质等级等等),然后基于层级结构训练NBDT做分类。再比如一个典型的图片分类场景,卖家在闲鱼上上传一张图片,希望算法能自动判断出他想卖什么类别的商品,有可能他上传了一张“椅子”和一张“桌子”的图片,但其实他想卖的是“家具”。那么基于层级结构的NBDT就能自动把他发布的商品识别为“家具”,或者提供推荐的备选项让用户自己选择他想要卖的是哪一层大类,省去了手动填写的麻烦。这些都是NBDT可以在后续中尝试的实践。 ## 参考 - 论文:[https://arxiv.org/abs/2004.00221](https://arxiv.org/abs/2004.00221) - 源码:[https://github.com/alvinwan/neural-backed-decision-trees](https://github.com/alvinwan/neural-backed-decision-trees)
## 后续计划 调研NBDT的目的是寻找一种让分类问题变得可解释的方法,这种可解释性可以应用在任何分类过程中需要给出决策路径的场景。尽管作者在论文中介绍的应用场景是图片分类,但只要把前面的CNN替换成其他网络,那么实际上任何分类问题都可以利用NBDT做出解释。比如在闲鱼优质商品分层项目中,我们可以基于业务知识构造商品间的诱导层级(例如第一层分为专业卖家/个人卖家、第二层分为动销率高/中/低...最后一层分为商品不同的优质等级等等),然后基于层级结构训练NBDT做分类。再比如一个典型的图片分类场景,卖家在闲鱼上上传一张图片,希望算法能自动判断出他想卖什么类别的商品,有可能他上传了一张“椅子”和一张“桌子”的图片,但其实他想卖的是“家具”。那么基于层级结构的NBDT就能自动把他发布的商品识别为“家具”,或者提供推荐的备选项让用户自己选择他想要卖的是哪一层大类,省去了手动填写的麻烦。这些都是NBDT可以在后续中尝试的实践。 ## 参考 - 论文:[https://arxiv.org/abs/2004.00221](https://arxiv.org/abs/2004.00221) - 源码:[https://github.com/alvinwan/neural-backed-decision-trees](https://github.com/alvinwan/neural-backed-decision-trees)