使用方法
tnpm install -g @ali/tuzki
tuzki set -a 你的账号
tuzki set -p 你的密码
tuzki starttuzki set
-a --account ,设置域账号
-p --passowrd ,设置域账号密码
tuzki config
输出当前配置的域账号和密码
tuzki start
运行代理,默认是 5000 端口,如果你在 start 后指定了一个端口则会在指定端口运行
tuzki start -p 9000 // 在9000端口运行开发过程
koa
Koa 是一个新的 web 框架,由 Express 幕后的原班人马打造, 致力于成为 web 应用和 API 开发领域中的一个更小、更富有表现力、更健壮的基石。 通过利用 async 函数,Koa 帮你丢弃回调函数,并有力地增强错误处理。 Koa 并没有捆绑任何中间件, 而是提供了一套优雅的方法,帮助您快速而愉快地编写服务端应用程序。
当然,这段话是我抄的。https://koa.bootcss.com/
puppeteer
Puppeteer是一个Node库,它提供了高级API来通过DevTools协议控制Chrome或Chromium 。
当然,这句话也是我抄的。https://github.com/puppeteer/puppeteer。简单的说就是Puppeteer提供了一个可供node环境使用的一个无界面、代码控制的谷歌浏览器。可以通过调用api来实现一个用户可能有的所有操作。说实话我用完以后觉得这个拿来当爬虫用真的杠杠的。。
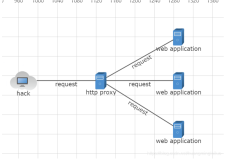
方案
基本是围绕着怎么生成cookie,怎么请求接口进行。
让puppeteer代替用户登陆平台,请求接口,拿到响应以后再用koa响应本地的前端请求。emm,大概就是下面这条线。
代码实现
代码实现思路大致分两部分,第一部分是让koa去识别和响应前端请求,第二部分是puppeteer收到koa拆解出协议和参数后,收发请求。
koa部分
用koa生成一个http server,开始监听某个端口的请求。这里使用了koa-log4帮助记录日志。
const Koa = require("koa");
const log4js = require("koa-log4");
const logger = log4js.getLogger("app");
const { PORT } = require("./config");
require("../log");
const bodyParser = require("koa-bodyparser");
const { instance: Proxy } = require("./Proxy");
async function server() {
// init app & proxy
const app = new Koa();
app.use(bodyParser());
app.use(log4js.koaLogger(log4js.getLogger("http"), { level: "auto" }));
await Proxy.login();
// add logger to a request
app.use(async (ctx, next) => {
const start = new Date();
await next();
const ms = new Date() - start;
logger.info(`${start} ${ctx.method} ${ctx.url} - ${ms}ms`);
});
// send request to server
app.use(async ctx => {
if (ctx.method === "GET") {
let res = await Proxy.get(ctx.url);
ctx.body = res;
} else if (ctx.method === "POST") {
let res = await Proxy.post(ctx.url, ctx.request.body);
ctx.body = res;
}
});
app.on("error", (err, ctx) => {
logger.error("server error", err, ctx);
});
app.listen(PORT);
}
server();puppeteer部分
生成一个浏览器,登陆平台,向koa提供get和post方法。
登陆部分
模拟真实用户的登陆操作即可。
login = async () => {
this.browser = await puppeteer.launch();
const page = await this.browser.newPage();
await page
.goto(
"https://login.abc.com/login.html“
)
.catch(async e => {
await page.waitFor(2000);
logger.error(`load login page timeout,retrying...`);
});
await page
.evaluate(() => {
document.querySelector("input[name='account']").focus();
})
.catch(async _ => {
logger.error(`Cannot get login form`);
});
await page.keyboard.type(ACCOUNT);
await page
.evaluate(() => {
document.querySelector("input[name='password']").focus();
})
.catch(async _ => {
logger.error(`Cannot get login form`);
});
await page.keyboard.type(PASSWORD);
await Promise.all([page.waitForNavigation(), page.click(".submit")])
.then(async () => {
await page.goto("http://abc.net/manage.htm");
console.log("proxy ready...");
})
.catch(async _ => {
logger.error(
`Navigation timeout of 30000 ms exceeded,restarting browser...`
);
await this.restartBrowser();
});
};get请求
puppeteer只能用来模拟用户操作,无法自如的发送ajax,所以get请求的思路是用page.goto来模拟。
get = async url => {
const page = await this.browser.newPage();
let res = "";
await page
.goto("http://abc.net" + url)
.then(async () => {
res = await page.content();
res = res.slice(res.indexOf("{"), res.lastIndexOf("}") + 1);
})
.catch(_ => {
logger.error(`get request got net::ERR_CONNECTION_RESET error`);
res = {
code: -1,
message: "Got a net error, try again?"
};
});
await page.close();
return res;
};post请求
post请求比get复杂一些,因为get可以通过页面跳转,而post无法模拟。
/**
* 用注入一段js的方式发送post请求
* 打开index页面,同时注入一段js代码,将参数填充进js代码段中,
* 将接口返回的内容写入div#root的innerHTML中,wait()接口请求时间后,获取div#root的innerHTML即为接口返回内容。
* 为每个请求单独开辟一个标签页,防止上一个请求没结束时即被新的请求覆盖,
* 当请求结束时主动关闭标签页,释放占用的内存
* 若此过程成功,则返回json字符串,若失败,返回失败原因
* @param {string} url 请求的地址
* @param {object} param 请求的参数
* @return {string} json字符串
*/
post = async (url, param) => {
const page = await this.browser.newPage();
let res = "";
await page.goto(
"http://abc.net/project/jarvis/page/index.html"
);
await page.addScriptTag({
content: `
$.post('http://abc.net'+'${url}', {data: ${JSON.stringify(
param.data
)}}, function (result) {
document.querySelector('#root').innerHTML = JSON.stringify(result)
});`
});
await page.waitFor(500);
res = await page.evaluate(() => {
return document.querySelector("#root").innerHTML;
});
await page.close();
return res;
};