本文来自于《程序员》与阿里云联合出品的《凌云》杂志。
作者:余晋
随着业务的迅猛发展,阿里各业务部门如淘宝、天猫、一淘、B2B等每天都会产生大量的数据,日均增量数百TB。2013年初,阿里内部的生产集群PA所在机房的存储量最多可扩容到数十PB,而当时已使用75 % 的存储量。存储容量告急,迫切需要将生产集群PA上的大量数据迁移到其他集群。
此时,如何安全地跨集群迁移几十PB的数据和其上相关业务,是我们面临的第一个挑战。数据迁移之后,两个集群间存在大量的数据依赖,需要互相访问最新的数据,如何安全快速地实现跨集群数据同步,这是紧跟其后的第二个挑战。本文将结合这两个挑战详细地介绍实现的细节和解决方案。
数据多版本和读写
首先,跨集群复制意味着同一份数据将存储在多个集群上。那么,每个集群上的数据可能会对应不同的版本。本文首先讲述数据多版本的表示,数据多版本与跨集群复制的一些基本假设以及如何做好多版本数据的读写。
数据多版本的表示
ODPS中的元数据管理依赖于OTS(开放结构化数据服务)。系统中的元数据,按照project、table和partition的层级来组织和表示。每一层级的meta都存储在同一张OTS的大表中。如图1所示,在每个project的meta中,有一列专用于该project多集群复制的相关配置,还有一列专用于表示这个partition在多集群中的数据版本。

每个最低层级的数据(为了描述方便,将分区表的每个分区和非分区表的表统称为分区),在meta中会有一列专用于表示这个数据的版本信息,具体内容如下:
{"LatestVersion":V1,"ClusterStatus":{"ClusterA":"V1", "ClusterB":"V0"}}
表示这个集群的有效版本号为V1,在ClusterA上的版本号为V1,在ClusterB上的版本号为V0。其中,“LatestVersion”是一个抽象描述,表示这个分区当前有效的版本号。V1是一个字符串,通常不用于做语义上的判断,V1和V0之间并无时序上的关系。“ClusterStatus”描述这个分区对应于每个计算集群上的物理文件的版本。
跨集群复制前提条件1:
计算集群之间的关系是对等的,即计算集群之间没有主从关系,只根据版本信息分为有效版本数据集群和无效版本数据集群。数据同步只与分区的版本信息相关,永远将有效版本的集群分区数据同步至无效版本集群。
跨集群复制前提条件2:
数据同步是准实时的,且不涉及跨集群的事务。假设一个分区当前版本信息为:
{"LatestVersion":V3,"ClusterStatus":{"ClusterA":"V3", "ClusterB":"V3"}},
那么该分区在ClusterA和ClusterB均为有效数据。假设此时在ClusterA上执行一个作业,修改了分区数据,该作业仅影响ClusterA和分区有效版本号,成功执行后该分区版本信息为:
{"LatestVersion":V4,"ClusterStatus":{"ClusterA":"V4", "ClusterB":"V3"}},
后台异步将V4版本数据从ClusterA同步至ClusterB,成功后,分区版本信息变为:
{"LatestVersion":V4,"ClusterStatus":{"ClusterA":"V4", "ClusterB":"V4"}},
如果在V4版本数据从ClusterA复制至ClusterB的过程中,ClusterA执行一个SQL作业,试图修改分区版本为V5,复制任务是否成功取决于修改meta和SQL作业修改meta的先后,如果复制任务在SQL作业之后修改meta,此时有效meta已被修改为V5,而复制作业的有效meta是V4,此时复制任务会失败。后台将再次复制分区数据V5版本至ClusterB。meta修改的原子性可由OTS的事务保证。
数据访问集群选择
既然数据可能在多个集群上存在多个版本,那么,对这份数据进行访问的时候如何在集群和版本之间做选择呢?本小节会阐述这个问题。
在ODPS中,每一个project,都有一个指定的计算集群default cluster。
跨集群复制前提条件3:
project的用户空间内所有作业默认在该project的default cluster上执行。
如图2所示,假设有两个project分别为p1和p2,p1的default cluster为C1,p2的default cluster为C2,p1和p2的数据可能同时 存在于C1和C2。此时执行一个SQL作业,“create table p2.t3 as select * from p2.t1”,该作业在p2的用户空间内访问p2的数据, 那么按照假设3,所有数据操作都在C2上进行。

再执行一个SQL作业“create table p1.t1 as select * from p2.t1”,此作业在p1的用户空间内,按照假设3,作业将执行在C1上,而作业中对p2.t2的数据访问遵循如下规则:
■如果C1上配置了p2.t2的跨集群数据复制,那么在C1上完成对p2.t2的数据操作;
■如果C1上未配置p2.t2的跨集群数据复制,那么在p2的default cluster即C2上完成对p2的数据操作。
也就是说,如果数据设置了跨集群数据复制,那么总是选择当前集群的数据。如果没有设置跨集群数据复制,那么就直接访问数据的default cluster。
如果数据都配置跨集群数据复制,那么不仅会对数据中心间的带宽产生很大的冲击,还会造成不必要的计算集群存储资源浪费。如果数据都不配置跨集群数据复制,那么跨数据中心数据访问的网络延迟无法保证。有跨机房数据依赖的作业的执行则得不到有效的保障。
数据读写
跨集群复制前提条件4:
永远读写有效版本的数据,允许出错或者等待。
当选择了一个计算集群进行数据访问后,在实际数据访问之前,会验证这个分区在这个集群的数据版本。
如图2所示,Job1在C2上访问P2.t2,假设t2的版本信息如下:
{"LatestVersion":V4,"ClusterStatus":{"C1":"V4","C2": "V4"}}
那么作业顺利进行。如果版本信息为:
{"LatestVersion":V4,"ClusterStatus":{"C1":"V4","C2": "V3"}}
那么作业会报版本信息错误的异常。
如果是会对数据写回的操作,如SQL中的insert into或者insert overwrite等,那么数据操作完成后有效版本信息也会发生改变。比如,还是访问C2的数据,进行写操作,作业之前版本信息为:
{"LatestVersion":V4,"ClusterStatus":{"C1":"V4","C2": "V4"}}
作业顺利进行,完成后分区数据更新版本为V5,修改分区meta为:
{"LatestVersion":V5,"ClusterStatus":{"C1":"V4","C2": "V5"}}
假如当前同时有两个作业Job3和Job4,分别对同一个分区进行写操作,Job3在C1执行,Job4在C2执行,Job3先完成,将分区版本更新为:
{"LatestVersion":V5,"ClusterStatus":{"C1":"V5","C2": "V4"}}
当Job4执行完,试图将分区数据更新为版本V6时,Job4会报错,因为当前C2的版本V4不是最新版本,无法在该版本上进行数据读写。
至此,阐述了跨集群复制在元数据层的抽象表示,以及基于这样的抽象表示,作业会如何选择数据进行读写等问题。搞清楚这些,是实现跨集群复制的基础,也是关键。下节会详细描述跨集群复制系统的实现。
系统实现
ODPS是构建在飞天系统上的管理控制系统,主要负责用户空间和对象的管理、Query和命令的解析与启动、数据对象的访问控制与授权等功能。系统中有worker、scheduler和executor三个角色:
■worker处理所有RESTful请求,包括用户空间(project)管理操作、资源(resource)管理操作、作业管理等,而SQL DML、MR、DT等启动伏羲任务的作业及其他异步作业,会提交给scheduler进一步处理;
■scheduler负责instance调度,包括将instance分解为task、对等待提交的task进行排序,以及向计算集群的伏羲Master询问资源占用情况来进行流控;
■executor负责启动SQL / DT / MR task,向计算集群提交任务,并监控这些任务的运行。
跨集群复制在ODPS控制集群增加了两个角色:replication worker,一个单独的进程;replication task,运行在executor中的抽象task。下面分别介绍这两个角色。
replication task
一个replication task会且仅会负责管理一个project所有数据的跨集群复制任务。不同于其他task,replication task不能由用户通过RESTful API访问。replication task的启动 / 停止由集群的管理者通过admin console操作。
复制任务产生
一个分区的数据发生版本变化,就会产生一个复制任务,该任务要完成两件事:
■将有效版本的物理数据从一个有效版本集群拷贝到一个非有效版本集群;
■在成功拷贝后修改分区元数据,更新分区版本信息。
一个复制任务所包含的信息为:源 / 目的集群、table、partition、version、物理文件地址、物理文件meta等。
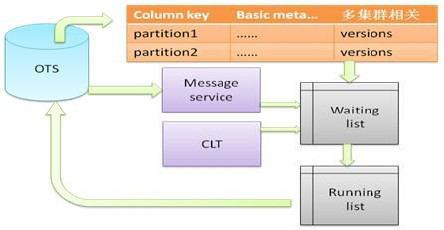
图3是复制任务工作流程,分区的版本信息发生变化可通过以下三种途径被感知。
■周期性扫描OTS中的元数据表,将有无效版本信息的集群和分区信息加入到复制任务的等待队列。
■当元数据发生变化时,message service会发出相应的event。通过订阅相关project的变化,可以在数据发生变化的第一时间感知到,加入到复制任务的等待队列。
■当用户使用ODPS CLT提交作业时,如果要访问的数据需要等待复制,CLT会推送复制信息,最终会加入到复制任务的等待队列。
复制任务在等待队列中按照复制任务的优先级高低排列,等待处理。一旦复制任务从等待队列中取出并成功执行,则记录到运行队列中。
复制作业
replication task会一直试图从等待队列中取出复制任务,按照计划将若干个复制任务组织成一个Job。分区的物理文件通过Job完成从源集群到目的集群的拷贝。
当一个Job计划出来后,这个Job需要的instance个数也按照每个instance处理的上限计算好。
复制资源申请
复制资源,主要指带宽资源,后文将详细介绍。当复制的Job计划好后,replication task会向replication worker申请需要的instance资源。replication worker会根据当前全局情况,授予一定instance资源给task。
复制任务执行
每个replication Job由三个task组成,即plan task、replicate task和statics task。
■plan task:将需要复制的C物理文件按照文件大小均分在replicate task的各instance之间。
■replicate task:完成物理文件从源集群到目的集群的拷贝。
■statics task:根据replicate task的每个instance拷贝文件的结果,统计记录每个分区是否复制成功。
replication task感知到一个Job结束后,会对这个Job里的每个复制成功的分区修改元数据中的版本信息。
数据版本变化
在线上生产环境中,源数据发生变化后的处理如下。
■新增表,新增分区:task收到event后会立即对新增的表和分区启动OTS扫描复制任务,加入到等待队列。
■rename表和分区:从等待队列中删除相关任务,从运行队列中停止相关任务。
■表和分区的版本发生变化:更新等待队列中的相关任务,或者从运行队列中停止相关任务。
Failover
replication task是在executor中执行的一个task。如同其他task,executor会定期向scheduler心跳更新其进度。如果长期未更新,scheduler会再次启动这个task,新启动的task会根据之前task的Failover信息,恢复至之前的进度。
replication worker
worker是ODPS service中的一个角色,一个service中只有一个instance。replication worker是跨集群复制与其他模块交互的接口,提供以下功能。
1.复制详情的查询。
■当前所有project正在复制的Job。
2.带宽管理(后文详细讲述)。
■根据带宽使用情况和replication task申请的带宽和优先级等信息,统筹带宽分配。
■当前集群使用带宽查询。
3.某一个project / table / partition是否正在 / 可能会被复制。
4.订阅复制的project数据变化message,接受数据变化的event。
5.维护与replication task的心跳;task通过心跳向worker更新该task目前使用的instance总数,目前该task运行的Job详情,向worker申请instance,而worker通过心跳分配带宽,发送相关event和命令。
流量控制
集群间的带宽是一个有限的固定值。复制Job读写的数据都会竞争这个资源。假设每个instance读写吞吐率为a MB / s,集群间可使用带宽为bGb,那么需要控制instance个数不超过上限C:
C = b Gb*1024/(8*a)
流量控制在task端和worker端都有体现。
task端
每次replication task计划好一个Job,会相应地计算出这个Job需要的instance数。此时,task会尝试做project内的并发控制,如果该project设置了并发instance的个数上限,那么project已经使用的instance个数 + 这个Job申请的instance个数的总和不能超过这个上限。如果project没有设置并发上限,则会向worker申请计算出来的instance数。
worker端
worker收到replication task的instance请求(设为a)后,会根据目前已经分配的instance总数(设为b),和集群间可使用的instance总数(设为c),来决定分配多少:
■a < c且b < c,则分配a
■a > c且b < c则分配c
■b >= c分配0
这种分配策略,会避免带宽分配零碎化,零碎化会导致每个Job执行时间都过长,也可以防止带宽浪费。同时,也带来一个问题,在一定的时间内,使用的带宽总量会超过限制值。由于每个instance处理的文件大小会不超过一个上限,因此每个instance实际执行的时间不会很长。超过带宽总量的情况很快就可以缓解。
复制优先级
优先级的产生
不同的project,数据的重要程度不同,对数据同步的需求程度也不同;同一个project之间的不同table,在任务中的优先级也不同,关键节点上的相关table对数据同步的实时性要求也会更高一些。
同时,如果一个复制请求是通过CLT推送的,说明用户依赖的数据没有同步好,用户正在等待,一旦等待一定时间还未同步好,用户请求就会超时。那么,这种复制任务的优先级也会非常高。
在这两种场景下,为复制任务设置了优先级,优先级越高的复制任务会优先以尽可能多的资源完成。
优先级的设置和比较
用户可以在跨集群的配置里设置每个需要同步的表的优先级,优先级为0~9,依次递增。复制任务之间的优先级规则如下:
■一个Job的优先级由Job内优先级最高的分区来决定;
■由非CLT推送产生的复制任务,优先级高低以配置值为准;
■CLT推送复制任务的优先级高于所有非CLT推送复制任务;
■同为CLT推送的复制任务,则以配置为准。
task中的等待队列是一个优先级队列。
在worker端,worker会优先将instance资源分配给优先级更高的请求。如果曾经有高级优先级的请求来过,那worker会暂将低优先级的请求hold住一段时间,如果没有高优先级的请求继续过来,再分配instance给低优先级的请求。
总结与未来展望
总结一下,ODPS的跨集群复制,完成了下面几个技术难点:
■支持数据的准实时跨集群复制;
■动态配置作业对跨集群数据的依赖;
■根据任务的优先级等合理管理和分配资源。
同时,跨集群数据复制也为未来数据业务长期发展打下了坚实的基础:
■突破了单集群的数据存储上限。由于目前主流分布式系统Master / Slave的结构,单集群受限于Master的内存和处理能力上限,而现在数据可以存储在多个集群上,不再受单集群的限制;
■可以实现多机房数据容灾,将来可以动态的跨机房备份重要数据;
■实现跨数据中心动态负载均衡,将热点集群上的数据和作业动态迁移到空闲集群,缓解热点集群的压力,提高空闲集群的使用率;
■对于响应速度要求比较高的请求,可以在多个集群同时调度这个作业,将响应最快的请求返回给用户。
跨集群复制上线后,2013年8月下旬,在十天之内,生成集群PA完成了数十PB数据的分批次迁移,安全无事故地迁移到了生成集群PB,全程没有人工干预,完美解决了这个项目的第一个挑战。随后,在每天的生成作业中,由于数据在两个集群之间互有依赖,每天有上十TB的线上数据通过跨集群复制在两个集群之间同步更新,解决了这个项目的第二个挑战。线上监控数据表明,每天数十TB的修改数据均在20分钟之内通过跨集群复制同步到了其他需要的集群。没有作业由于访问其他集群的依赖数据而失败。随着数据规模的增大,ODPS的生产集群早已从2个增加到了更多个。不同的生产集群分布在不同的地域,跨集群复制承担的责任也越来越重大。