相较数据处理的两大阵营,批量处理(Batch)和流式处理(Stream):批量处理比较经济,且只对全量数据进行处理;但数据延时较大,因为只有跑批之后数据才提供给应用系统。
流式处理延时小,但由于24小时运作,因此不许有宕机时间,并且由于只处理增量数据,所以难免会遗漏部分数据的处理。
在两相权宜之下,演化出了以下两种混合架构:- Lambda架构:有流式处理以提供低延时的数据访问,同时定期跑批以覆盖流式处理中可能带来的不完整的数据。但这会造成企业中有两套代码库。

-
Kappa架构:在原有流式处理的管道中加入数据保留(Retention)以减小数据未处理的风险,但这就约束了使用者只能在处理中加入增量算法,不然无法识别新旧数据。

流式处理可以集成一些简单的算法,他们体量很小在完成算法的同时又不会影响到数据的实时性,例如: - 数据的过滤与转换;
- 数据的分类;
- 简单的数学计算(求和、计数、求平均等)及逻辑运算
-
滑动窗口大小设定(比如只对过去5分钟的数据做运算等)

Twitter有业界知名的流式处理框架(从Yahoo学来的),它需要定期汇报给客户广告投放的效果,怎么做呢?首先从Kafka中提取广告跟踪的数据,然后做初步筛选,然后提取相关字段(比如实际播放时长、浏览量等),然后按照广告的投放活动进行分组,最后定义窗口时长进行浏览量的统计。
下面我们来看下流式处理中的各代表框架。
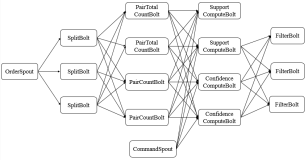
Storm是第一个被广泛采纳的流式框架,它在2010年由BackType公司开发(目前这家公司已被Twitter收购),2011年开源,2014年成为Apache顶级项目。在Storm中提出了“spouts”和“bolts”的想法,前者接收流数据(比如Kafka)后稍作处理生成全新的流,而后者以流作为输入,并生成流作为输出。Bolts只需订阅它们需要处理的流,并指明作为输入的流应该如何划分。它是一个由spouts和bolts组成的网络。
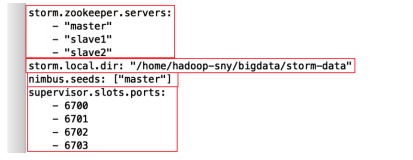
它的部署也非常简单,设计好架构之后,提交给Nimbus服务器,再由Zookeeper将架构部署到组织内的节点,每一个Storm节点中有多个Worker进程(Worker进程中运行了spouts和bolts的任务)及一个监管进程(Supervisor)。当有Storm节点宕机时,Nimbus还会重新部署workers和工作流。
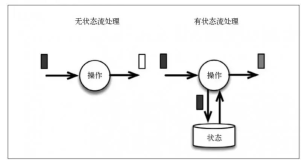
对于组织中一些状态数据(例如登陆账号),Storm将其存放在内存中或放到Redis数据库里,同时会在关键路径上同步这些状态数据。当然如果这些状态数据过大,会影响到流式框架的传输实时性。
当然如果真的有太多Tuples(storm中使用的最基本单元、数据模型和元组)要处理导致实时数据流拥堵,Storm也会有相应的反压机制,它对bolt的入站缓存做监控,当超过“高水位”时做限流;低于“低水位”时做加速。 在2012年,Storm推出了新的扩展组件Trident,用来提供高级API以满足更多数据的接入,并将流式框架减速为微批量(Micro-batch),提高了数据流的时序性和吞吐量。
从上图中我们可以看到,Trident将Spout到最终服务间的数据流切成了三个微批量(Trident在英语中就是三叉戟的意思)。 领英公司(Linkedin)在开发Kafka的时候同时开发了Samza,Samza是在Kafka上层的实时数据流,是上文提到的Kappa架构(Kafka能保留一定量的历史数据,因此绝大多数的Kappa会基于Kafka)。2013年开源,2015年成为Apache顶级项目。他的特点是单线程作业(避免数据的时序错乱和数据对点),只保留本地状态(便于分布式拓扑与灾难恢复),只使用本地流处理器(更低的延时)。除领英外,我们熟悉的Uber、Netflix也是Samza的用户。 在架构设计上,它的作业(Job)类似于Storm中的bolt,但是因为有Kafka帮忙缓存数据,在Kafka的Partition内部完成数据排列,因此Samza完全不用担心反压问题和时序问题。分布式的作业还能保证数据流的高可用。
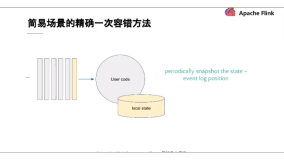
在处理状态数据时有两种办法,第一种是异地存放,作业会将状态数据(例如移动窗口)存放在一个KV存储中(例如Redis),但这样一个共享的KV存储的读写会非常频繁;另一种本地存放,即将状态变化的日志作为数据流的一部分写到Kafka,然后根据日志数据更新状态变化。我们一般倾向于第二种,因为没有反压,查询便捷并且恢复简单。
既然说到恢复,对于Samza任务的恢复,只需要重播Kafka中的变更日志再比较其余任务节点就能将故障节点状态恢复到最后运行正常的时刻。
希望今天的讲述不太枯燥,下一堂课我们介绍流式框架的另外半壁江山:Spark和Flink。