在利用Spark处理数据时,如果数据量不大,那么Spark的默认配置基本就能满足实际的业务场景。但是当数据量大的时候,就需要做一定的参数配置调整和优化,以保证业务的安全、稳定的运行。并且在实际优化中,要考虑不同的场景,采取不同的优化策略。
1.合理设置微批处理时间
在SparkSreaming流式处理中,合理的设置微批处理时间(batchDuration)是非常有必要的。
如果batchDuration设置过短,会导致SparkStreaming频繁提交job。如果每个batchDuration所产生的job不能在这个时间内完成处理,就会造成job不断堆积,最终导致SparkStreaming发生阻塞,甚至程序宕掉。
需要根据不同的应用场景和硬件配置等确定,可以根据SparkStreaming的可视化监控界面,观察Total Delay等指标来进行batchDuration的调整。
2.控制消费的最大速率
比如SparkStreaming和Kafka集成,采用direct模式时,需要设置参数spark.streaming.kafka.maxRatePerPartition以控制每个Kafka分区最大消费数。该参数默认没有上线,即Kafka当中有多少数据它就会直接全部拉出。
但在实际使用中,需要根据生产者写入Kafka的速率以及消费者本身处理数据的速度综合考虑。
同时还需要结合上面的batchDuration,使得每个partition拉取的数据,要在每个batchDuration期间顺利处理完毕,做到尽可能高的吞吐量,该参数的调整需参考可视化监控界面中的Input Rate和Processing Time。
3.缓存反复使用的"数据集"
Spark中的RDD和SparkStreaming中的DStream,如果被反复的使用,最好利用cache或者persist算子,将"数据集"缓存起来,防止过度的调度资源造成的不必要的开销。
4.合理的设置GC
JVM垃圾回收是非常消耗性能和时间的,尤其是stop world、full gc非常影响程序的正常运行。
关于JVM和参数配置,建议研读《JVM内存管理和垃圾回收》、《JVM垃圾回收器、内存分配与回收策略》、《内存泄漏、内存溢出和堆外内存,JVM优化配置参数》。
5.合理设置CPU
每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况。
要避免CPU的使用浪费,比如一个executor占用多个core,但是总的CPU利用率却不高。此时建议让每个executor占用相对之前较少的core,同时worker下面增加更多的executor进程来增加并行执行的executor数量,从而提高CPU利用率。同时要考虑内存消耗,毕竟一台机器运行的executor越多,每个executor的内存就越小,容易产生OOM。
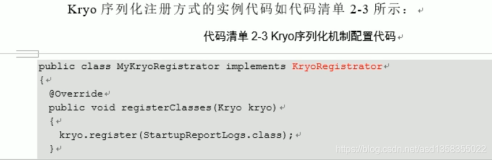
6.使用Kryo进行序列化和反序列化
Spark默认使用Java的序列化机制,但这种Java原生的序列化机制性能却比Kryo差很多。使用Kryo需要进行设置:
//设置序列化器为KryoSerializer
SparkConf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
//注册要序列化的自定义类型
SparkConf.registerKryoClasses(Array(classOf[CustomClass1],classOf[CustomClass2]))7.使用高性能的算子
1)使用reduceByKey、aggregateByKey替代groupByKey
2)filter之后进行coalesce操作
3)使用repartitionAndSortWithinPartition
替代repartition与sort操作
4)使用mapPartition替代map
5)使用foreachPartition替代foreach
要结合实际使用场景,进行算子的替代优化。
除了上述常用调优策略,还有合理设置Spark并行度,比如参数spark.default.parallelism的设置等,所有这些都要求对Spark内核原理有深入理解,这里不再一一阐述。
阿里巴巴开源大数据技术团队成立Apache Spark中国技术社区,定期推送精彩案例,技术专家直播,问答区近万人Spark技术同学在线提问答疑,只为营造纯粹的Spark氛围,欢迎钉钉扫码加入!

对开源大数据和感兴趣的同学可以加小编微信(下图二维码,备注“进群”)进入技术交流微信群。
Apache Spark技术交流社区公众号,微信扫一扫关注