前提:
数据样本符合标准正态分布,正态分布的核心是中心极限定理即:如果一个事物受到多种因素的影响,不管每个因素本身是什么分布,它们加总后,结果的平均值就是正态分布。如果要符合正态分布则这些因素必须彼此独立,彼此不独立的各项因素会互相加强影响,那么就构不成正态分布。(还有对数正态分布是指各种因素对结果的影响不是相加,而是相乘)
经验法则原理:
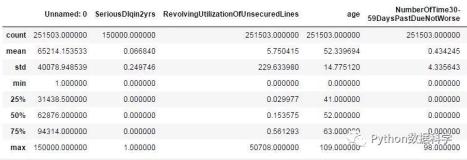
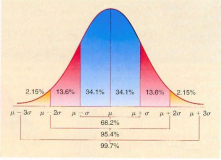
标准正态分布下的曲线为钟型曲线,期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。因此对于一组数据,如果符合正态分布,则可以通过经验法则来检测异常值,同图中可以发现,68.2%的测量值落在μ值处正负一个标准差σ的区间内,95.4%的测量值将落在μ值处正负两个标准差σ的区间内,99.7%的值落在μ值处正负三个标准差σ的区间内。因此,对于一组符合正态分布的数据,如果某个值距离μ值超过三个标准差σ则可以判断这个值属于异常数据。

计算步骤:
μ值:μ是遵从正态分布的随机变量的均值,由于前提是各种因素对结果的影响为相加,因此μ值的计算可以为样本数据的算术平均值。
标准差σ:所有数据减去其平均值的平方和,所得结果除以该组数之个数N(数据集为总体数据情况,一般用于大数据算法)或者个数N减1(数据集为样本数据情况,认为数据集不是总体数据而是总体数据的一部分,一般用于统计学),再把所得值开根号,所得之数就是这组数据的标准差。

数据科学异常值检测原理—经验法则
判断逻辑:计算μ+3σ,μ-3σ,当单个数据大于μ+3σ或者小于μ-3σ时,认为此数据为异常值,因为按照经验法则,此数据在数据集的99.7%范围外。