背景
公司选用elasticjob作为分布式任务调度工具,版本2.1.5,其中有一个任务对应机器两台,A和B,任务总分片数是4,A对应分片0、1,B对应分片2、3。任务每晚23:30:00执行,T日计算数据记录日期T+1,供T+1日使用。
突然有一天,A机器在22:24运行执行起分片2任务,执行完分片2之后又执行了分片3,注意分片2、3本该是机器B所用的分片,这两点就很奇怪了,异常的时间执行了不属于自己的分片,而且是一个一个执行。下方是日志中记录的task id
// 异常的task id,很清楚的看到分片是@2@,机器A在执行
"taskId":"jobname@-@2@-@READY@-@A机器ip@-@4927"
// 正常的task id,分片号@2,3@,ip对应的是机器B
"taskId":"jobname@-@2,3@-@READY@-@B机器ip@-@12384"经过分析,基本断定是进任务失效转移逻辑了。但是,为什么任务失效转移呢?任务不在执行的时间点,而且也没有执行中,不可能出现这个情况。
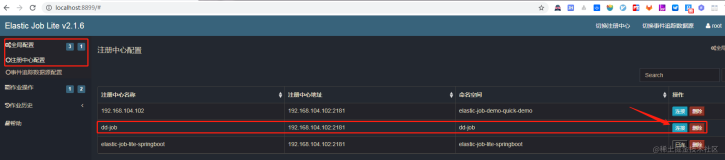
经过回忆,22:23的时候,开发对机器B做了一次内存dump,与A机器启动相差一分钟,可能问题出在这里了。难道对B机器做dump操作导致B短暂与ZK注册中心断开了吗,导致误以为服务器宕机?带着问题,我们又对B做了一次dump,很快,证实了我们的猜测,如下图所示,分片2正在运行,实际执行分片2的是机器A,而且标识也很清楚,失效转移
但是,按照官方的说法,失效转移是指运行中的作业服务器崩溃不会导致重新分片,只会在下次作业启动时分片。启用失效转移功能可以在本次作业执行过程中,监测其他作业服务器空闲,抓取未完成的孤儿分片项执行。
运行中的作业服务器崩溃不会导致重新分片,经过确认,当时我们的任务并不在执行中,这个就很奇怪了,带着这些疑问我们深入elasticjob源码。
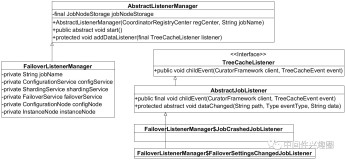
失效转移
失效转移相关逻辑入口在FailoverListenerManager#JobCrashedJobListener,实际处理是FailoverService。当一台服务器宕机后会触发一个事件Type.NODE_REMOVED,elastic-job根据这个事件来进行相关的处理,相关过程都注释在代码里了。
public final class FailoverListenerManager extends AbstractListenerManager {
// ...
private final FailoverService failoverService;
private final ShardingService shardingService;
class JobCrashedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
// 1失效转移开启、2注册中心事件-节点移除,也就是一台服务器下线、3是instance路径,即jobName/instances路径
if (isFailoverEnabled() && Type.NODE_REMOVED == eventType && instanceNode.isInstancePath(path)) {
// path,jobName/instances/ip-@-@pid
// jobInstanceId是这个样子的ip-@-@pid
String jobInstanceId = path.substring(instanceNode.getInstanceFullPath().length() + 1);
// 如果jobInstanceId和当前机器一致,直接跳过
if (jobInstanceId.equals(JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId())) {
return;
}
// 获取失效转移的分片,对应zk目录jobName/sharding/分片号/failover,失效转移分片对应的实例id
List<Integer> failoverItems = failoverService.getFailoverItems(jobInstanceId);
if (!failoverItems.isEmpty()) {
// 如果有jobInstanceId的失效转移分片
for (int each : failoverItems) {
// 把分片存放到目录leader/failover/items
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
} else {
// 获取如果jobInstanceId没有失效转移分片对应的分片,然后存放到目录leader/failover/items/分片号,执行分片分片失效转移
// 从这里看只要是服务器宕机就一定要执行时效转移逻辑了,其实也不是,
// shardingService.getShardingItems(jobInstanceId)会判断服务器是否还可用,不可用的话返回的分片集合就是空的
// 但是,针对dump对内存导致的服务器短暂的不可用,则有可能出现错误,我们的任务异常启动就出现这里
for (int each : shardingService.getShardingItems(jobInstanceId)) {
// 把分片存放到目录leader/failover/items
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
}
}
}
}
// ...
}public final class FailoverService {
/**
* 如果需要失效转移, 则执行作业失效转移.
*/
public void failoverIfNecessary() {
if (needFailover()) {
jobNodeStorage.executeInLeader(FailoverNode.LATCH, new FailoverLeaderExecutionCallback());
}
}
// 判断leader/failover/items下是否有节点
// failoverService.setCrashedFailoverFlag(分片号);方法就是往leader/failover/items目录下存节点,也就是执行了setCrashedFailoverFlag方法后,needFailover()是true
private boolean needFailover() {
return jobNodeStorage.isJobNodeExisted(FailoverNode.ITEMS_ROOT) && !jobNodeStorage.getJobNodeChildrenKeys(FailoverNode.ITEMS_ROOT).isEmpty()
&& !JobRegistry.getInstance().isJobRunning(jobName);
}
/**
* 获取作业服务器的失效转移分片项集合.
*
* @param jobInstanceId 作业运行实例主键
* @return 作业失效转移的分片项集合
*/
public List<Integer> getFailoverItems(final String jobInstanceId) {
// 作业分片
List<String> items = jobNodeStorage.getJobNodeChildrenKeys(ShardingNode.ROOT);
List<Integer> result = new ArrayList<>(items.size());
for (String each : items) {
int item = Integer.parseInt(each);
// 获取目录sharding/分片号/failover下的节点
String node = FailoverNode.getExecutionFailoverNode(item);
// 确认jobName/sharding/分片号/failover下的实例是否和失效的jobInstanceId一致,如果是的话就加入到失效分片集合
if (jobNodeStorage.isJobNodeExisted(node) && jobInstanceId.equals(jobNodeStorage.getJobNodeDataDirectly(node))) {
result.add(item);
}
}
Collections.sort(result);
return result;
}
class FailoverLeaderExecutionCallback implements LeaderExecutionCallback {
@Override
public void execute() {
// 判断本机是否停止调度任务了以及是否需要失效转移
if (JobRegistry.getInstance().isShutdown(jobName) || !needFailover()) {
return;
}
// leader/failover/items下获取失效转移的分片
int crashedItem = Integer.parseInt(jobNodeStorage.getJobNodeChildrenKeys(FailoverNode.ITEMS_ROOT).get(0));
log.debug("Failover job '{}' begin, crashed item '{}'", jobName, crashedItem);
// 目录下sharding/分片号/failover下创建节点,标识失效转移正在执行中
jobNodeStorage.fillEphemeralJobNode(FailoverNode.getExecutionFailoverNode(crashedItem), JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId());
// 删除分片失效转移记录
jobNodeStorage.removeJobNodeIfExisted(FailoverNode.getItemsNode(crashedItem));
// TODO 不应使用triggerJob, 而是使用executor统一调度
// 执行失效转移作业
JobScheduleController jobScheduleController = JobRegistry.getInstance().getJobScheduleController(jobName);
if (null != jobScheduleController) {
jobScheduleController.triggerJob();
}
}
}
}
public final class ShardingService {
/**
* 设置需要重新分片的标记.
*/
public void setReshardingFlag() {
jobNodeStorage.createJobNodeIfNeeded(ShardingNode.NECESSARY);
}
/**
* 获取作业运行实例的分片项集合.
*
* @param jobInstanceId 作业运行实例主键
* @return 作业运行实例的分片项集合
*/
public List<Integer> getShardingItems(final String jobInstanceId) {
JobInstance jobInstance = new JobInstance(jobInstanceId);
// 服务器可用,即servers/目录及jobName/instances目录下存在对应的ip
if (!serverService.isAvailableServer(jobInstance.getIp())) {
return Collections.emptyList();
}
List<Integer> result = new LinkedList<>();
// 获取所有分片
int shardingTotalCount = configService.load(true).getTypeConfig().getCoreConfig().getShardingTotalCount();
for (int i = 0; i < shardingTotalCount; i++) {
// 找到宕机服务器对应的分片
if (jobInstance.getJobInstanceId().equals(jobNodeStorage.getJobNodeData(ShardingNode.getInstanceNode(i)))) {
result.add(i);
}
}
return result;
}
}结论
dump堆内存导致服务器B短暂不可用,与注册中心断开连接,触发了注册中心zk节点删除事件,服务器A监听到事件后执行失效转移逻辑,当服务器A去获取服务器B对应的分片时,服务器B又恢复了工作,这时服务器A拿到了服务B的两个分片2、3,依次执行失效转移逻辑,这就是为什么dump B之后A开始执行B的两个分片。
class JobCrashedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
// 1失效转移开启、2注册中心事件-节点移除,也就是一台服务器下线、3是instance路径,即jobName/instances路径
if (isFailoverEnabled() && Type.NODE_REMOVED == eventType && instanceNode.isInstancePath(path)) {
...
List<Integer> failoverItems = failoverService.getFailoverItems(jobInstanceId);
if (!failoverItems.isEmpty()) {
...
} else {
// 获取如果jobInstanceId没有失效转移分片对应的分片,然后存放到目录leader/failover/items/分片号,执行分片分片失效转移
// 从这里看只要是服务器宕机就一定要执行时效转移逻辑了,其实也不是,
// shardingService.getShardingItems(jobInstanceId)会判断服务器是否还可用,不可用的话返回的分片集合就是空的
// 但是,针对dump对内存导致的服务器短暂的不可用,则有可能出现错误,我们的任务异常启动就出现这里
for (int each : shardingService.getShardingItems(jobInstanceId)) {
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
}
}
}
}附 zk注册中心任务记录
-
namespace/jobname
-
leader
-
failover
-
items
- 2 失效转移分片,也是判断是否需要标识
- 3 失效转移分片,也是判断是否需要标识
-
-
sharding
- necessary 需要重新调整分片
-
election
- host
- latch
-
-
servers
-
172.16.101.112
- prcessSuccessCount
- hostName
- processFailureCount
- status
- disabled
- sharding
-
172.16.101.52
- prcessSuccessCount
- hostName
- processFailureCount
- status
- disabled
- sharding
-
-
config
- cron
- shardingTermParameters
- failover
- processCountIntervalSeconds
- monitorExecution
- shardingTotalCount
- jobParameter
- fetchDataCount
- concurrentDataProcessThreadCount
-
instances
- [172.16.101.112@-@9644, 172.16.101.52@-@10138]
-
sharding
-
0
- running 分片运行中
- instance 运行的实例
- failover 分片失效转移,运行中
- 1
- 2
- 3
-
-
重要的类,待完善
JobRegistry 任务管理,一个JVM一个单例,记录任务和注册中心对应关心、任务状态、任务实例
SchedulerFacade 任务调度门面类,一个任务对应一个
JobNodeStorage 作业节点访问
ShardingNode zk节点名称构建规则
JobNodePath 作业节点构建
/jobname/sharding
注册中心
RegistryCenter
CoordinatorRegistryCenter
ZookeeperRegistryCenter
事件监听
AbstractListenerManager
ShutdownListenerManager